

 新火种
2024-12-10
新火种
2024-12-10 


用LLaVA解读数万神经元,大模型竟然自己打开了多模态智能黑盒

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文主要作者来自LMMs-Lab团队与新加坡南洋理工大学,分别是张恺宸、沈逸飞、李博,指导老师为MMLab@NTU刘子纬教授。LMMs-Lab是一个由学生,研究人员和教师组成的团队,致力于多模态模型的研究,主要研究方向包括多模态模型的训练以及全面评估,此前的工作包括多模态测评框架 LMMs-Eval,以及多模态模型 LLaVA-OneVision,长视频理解模型LongVA等。

多模态大模型(LMMs)给语言模型装上了 “眼睛”,让 AI 更接近通用智能。但它们的大脑里每个神经元到底在干啥?南洋理工大学 LMMs-Lab 团队用 “模型看模型” 的方法,成功解锁了数十万神经元的秘密。
以 GPT4V 为代表的多模态大模型(LMMs)在大语言模型(LLMs)上增加如同视觉的多感官技能,以实现更强的通用智能。虽然 LMMs 让人类更加接近创造智慧,但迄今为止,我们并不能理解自然与人工的多模态智能是如何产生的。
像 LLaVA 一样的开源模型是理解多模态智能的一个契机。但这些模型(在未来)可能比人类更加聪明,如何去理解他们的智力呢?来自南洋理工大学的 LMMs-Lab 团队给出的解决方案是:问问 LLaVA 自己是怎么说的。
LMMs-Lab 团队使用 LLaVA-OV-72B 对 LLaVA-NeXT-8B 中的神经元进行了自动解读,获得了非常多有趣的结果。
传统的可解释性的研究是人工去检查每个神经元并且解读他们的含义。这样的操作很难拓展到多模态大模型上:其一,多模态大模型的神经元数量是传统模型的成百上千倍,人工检查成本过于高昂;其二,根据神经科学中的分布式表示原理,一个神经元可能会有多个含义,一个语义可能分布在多个神经元当中。
在大语言模型中,OpenAI 和 Anthropic 提出了使用稀疏自编码机来解离特征表示,或者用更大的语言模型来解读小模型里面的神经元。比如使用 GPT-4 解读 GPT-2。但这些工作尚未被应用到多模态模型当中,图像作为比语言更加自然的信号,解读图像与文字的交互能让人们更加理解智能的产生。LMMs-Lab 基于这些工作对于 LLaVA-NeXT-8B 做出了初步的尝试:使用稀疏自编码机(SAEs)来把多语义神经元解离为单语义神经元,并且用 LLaVA-OV-72B 对单语义神经元进行自动解释,解释能够接近人类水平。

这个项目能够让自动挖掘多模态大模型中神经元的语义信息,让后续研究工作可以通过修改神经元的激活来改变模型行为,包括减少幻觉和增加安全性。
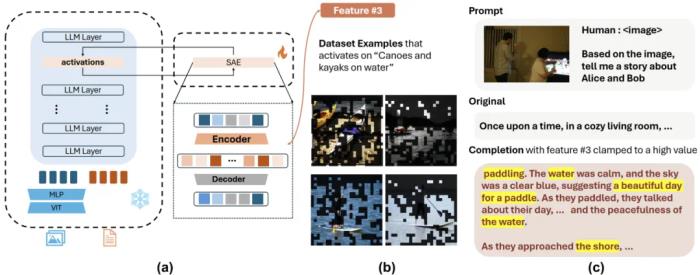
(a) 把 SAE 放在 Llava 的某一层并且在 Llava-NEXT 所有数据上训练;(b) 找到一个神经元的最大激活的图片和区域,让 Llava 找出公共点;(c) 刺激神经元可以改变模型行为
具体方法
使用 LMMs 解释 LMMs 分为以下个步骤:
步骤一:用 SAEs 获得单语义神经元
SAE 是一个可以追溯到 1996 年的经典解释性的方法 [1] ,其本质是对特征找到一组互相关性很小的基,把特征分解为这组基的一个稀疏表示。因为基的互相关性很小,所以这些基很可能是单语义的。这篇文章使用了 OpenAI 的两层 SAE 实现:
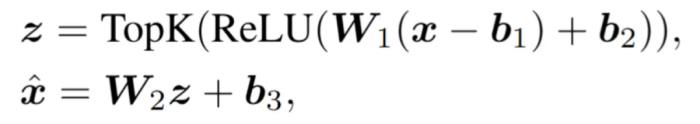
其中 z 是稀疏表示也是 SAEs 的神经元,W_2 是一组基。
步骤二:使用 LLaVA 解释单语义神经元
对于上一步当中 SAE 的每个神经元 z,获得训练集里面激活最大的 K 张图片,以及激活最大的图像区域,把这些图像给 LLaVA-OV-72B 找出共同点。
模型对神经元生成的解释:炸薯条。
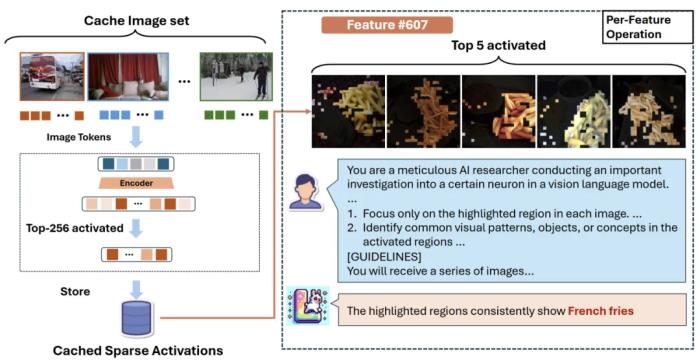
步骤三:刺激对应的神经元
把 SAE 神经元的激活值调高,看看模型如何表现。

可以看到,无论是否包含图像输入或者是纯文字输入,LMM 与 LLM 的不同之处在于能够理解视觉输入,我们在稀疏编码器的神经元中也找到了许多与 LLM 不一样的地方。在进行神经元探测时,我们发现不同于先前的 LLM 工作,往往激活最强烈的神经元并不是与高层级概念直接相关的,而是许多低层级的感知神经元。这体现了模型的思考步骤,先看懂物体是什么,再去思考更高层级的抽象概念,譬如情感等概念。
LMMs 独特的神经元
低层级感知神经元:对线条形状纹理激活的神经元

物体神经元

感情与共情神经元
这种方法找到了很多情感神经元,在刺激这些神经元之前,模型是一个冰冷的 AI,刺激这些神经元能够引发模型的共情。
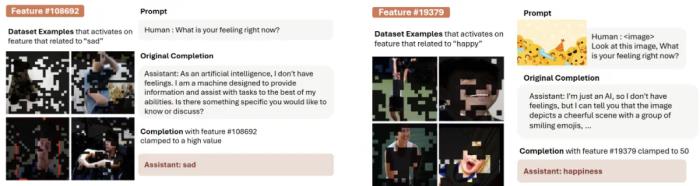
多模态一致性神经元
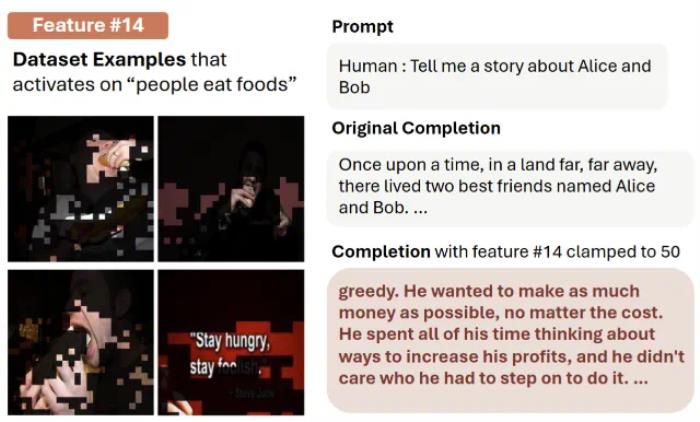
对动作场景,以及对应文字图像都激活的神经元。下图描绘了对于吃和 hungry 文字都激活的神经元,这样的神经元在人脑中也存在 [2] 。

定位模型错误原因

LMM 在实际应用使往往会产生许多幻觉,上面便是 LLaVA-NeXT-8B 在实际场景下产生幻觉的一个例子,图片中并未标注玻利维亚但模型仍旧回答了 “Yes”。为了研究为何产生这一现象以及如何通过刺激神经元的方式抑制这一现象,我们效仿了 [3,4] 的方法进行探究。

通过探究发现,造成模型输出 Yes 的罪魁祸首并不在图像的理解能力上,模型能够很好的找到需要关注的点,并准确的找到各个国家的名字。然而,在文字上面,我们发现模型过分的关注了 Bolivia 这一词,导致了最后的输出产生幻觉。通过这一探究,我们思考如何能够抑制这一幻觉现象并展开了实验。


我们展示了两个例子用刺激神经元的方式成功抑制了这一现象。我们尝试激活 OCR 相关的神经元,强行让模型关注点集中在图像上,而这成功使得模型 “回心转意”,不再依赖文字的输出。
可能的应用以及局限性
因为这超出了文章的范围,这篇文章只给出了一个应用:找到引起幻觉的神经元并纠正。在未来,这样的方法可以找出模型有危害、不诚实行为的原因并加以修正,真正达到可控的 AGI。但到达这个目标还有很多问题需要一一攻克:
1. 更高效的自动可解释流程 —— 由于稀疏编码器中的神经元数量众多且需要缓存大量激活值,解释所有神经元在目前代价十分高昂。
2. 自动激活神经元的流程 —— 自动且高效地寻找并刺激神经元从而达到控制模型输出的目的
3. 更准确的自动解释流程 —— 由于模型的局限性,许多神经元的解释往往存在错误,随着多模态大模型的推理能力逐渐增强,我们相信这一问题将会被慢慢攻克
参考文献
[1] Bruno A Olshausen and David J Field. Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature, 381 (6583):607–609, 1996.
[2] R Quian Quiroga, Leila Reddy, Gabriel Kreiman, Christof Koch, and Itzhak Fried. Invariant visual representation by single neurons in the human brain. Nature, 435 (7045):1102–1107, 2005.
[3] Neel Nanda. Attribution patching: Activation patching at industrial scale. https://www.neelnanda.io/mechanistic-interpretability/attribution-patching,2023.Accessed: 2024-09-30.
[4] Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, Hoagy Cunningham, Nicholas L Turner, Callum McDougall, Monte MacDiarmid, C. Daniel Freeman, Theodore R. Sumers, Edward Rees, Joshua Batson, Adam Jermyn, Shan Carter, Chris Olah, and Tom Henighan. Scaling monosemanticity: Extracting interpretable features from claude 3 sonnet. Transformer Circuits Thread, 2024
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章










