

 新火种
2024-12-10
新火种
2024-12-10 


LeCun团队新作:在世界模型中导航
现实世界版的 Genie-2?最近,世界模型(World Models)似乎成为了 AI 领域最热门的研究方向。继World Labs(李飞飞)、谷歌 DeepMind 接连发布自己的世界模型研究之后,Meta FAIR 的 Yann LeCun 团队也加入了战场,也在同一周之内发布了导航世界模型(Navigation World Models/NWM)。我们知道,Yann LeCun 一边在不断唱衰当前主导 LLM 领域的自回归范式,同时也一直是世界模型的「鼓吹者」。上月中旬,该团队就已经发布了一篇世界模型相关研究成果,但那篇研究涉及的模型规模不大,环境也较为简单,参阅机器之心报道《LeCun 的世界模型初步实现!基于预训练视觉特征,看一眼任务就能零样本规划》。而这一次,LeCun 团队发布的 NWM 看起来能适应更复杂的环境了,并且与 World Labs 和 DeepMind 的世界模型一样,也能基于单张图像生成连续一致的视频。只是 LeCun 团队的这个世界模型更加强调世界模型的导航能力,其能够在已知环境中按照轨迹行进,也能在未知环境中自己寻找前进道路,还能执行路径规划。不过整体而言,与能单图生世界的 DeepMind Genie 2 相比,NWM 的单图生视频还是要稍逊一些。 论文标题:Navigation World Models论文地址:https://arxiv.org/pdf/2412.03572v1项目地址:https://www.amirbar.net/nwm/从其项目网站的演示视频看,NWM 的效果很不错,能够基于单张真实照片执行相当好的导航操作。只能说,世界模型,也开始卷起来了。NWM 效果演示在深入了解 NWM 的技术细节之前,我们先来看看它的实际表现如何。首先是在已知环境中按照轨迹行进的能力。NWM 能够基于单张输入帧和给定的输入动作合成视频,这个过程是自回归式的。另需说明,在这里,模型已经已经训练阶段看过了这个环境,但轨迹是全新的。可以看到,不管是室内环境还是室外环境,NWM 都具有相当不错的场景理解表现。
论文标题:Navigation World Models论文地址:https://arxiv.org/pdf/2412.03572v1项目地址:https://www.amirbar.net/nwm/从其项目网站的演示视频看,NWM 的效果很不错,能够基于单张真实照片执行相当好的导航操作。只能说,世界模型,也开始卷起来了。NWM 效果演示在深入了解 NWM 的技术细节之前,我们先来看看它的实际表现如何。首先是在已知环境中按照轨迹行进的能力。NWM 能够基于单张输入帧和给定的输入动作合成视频,这个过程是自回归式的。另需说明,在这里,模型已经已经训练阶段看过了这个环境,但轨迹是全新的。可以看到,不管是室内环境还是室外环境,NWM 都具有相当不错的场景理解表现。
 NWM 也能在未知环境中导航:它不仅适用于已知环境,对于训练中从未见过的单张输入图像,模型也可以根据给定的输入动作自回归式地预测后续帧。
NWM 也能在未知环境中导航:它不仅适用于已知环境,对于训练中从未见过的单张输入图像,模型也可以根据给定的输入动作自回归式地预测后续帧。
 下面是与其它模型的对比情况,可以看到,NWM 在保证合成视频的一致性和稳定性方面以及动作的执行效果方面都更加出色。
下面是与其它模型的对比情况,可以看到,NWM 在保证合成视频的一致性和稳定性方面以及动作的执行效果方面都更加出色。 另外,该团队也研究了使用 NWM 和外部导航策略 NoMaD 来执行规划。具体来说,就是让 NoMaD 给出轨迹,再让 NWM 来进行排名 —— 后者会生成轨迹视频并选出其中得分最高的轨迹。
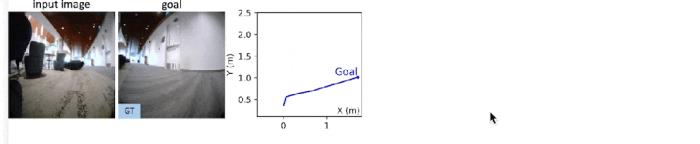
另外,该团队也研究了使用 NWM 和外部导航策略 NoMaD 来执行规划。具体来说,就是让 NoMaD 给出轨迹,再让 NWM 来进行排名 —— 后者会生成轨迹视频并选出其中得分最高的轨迹。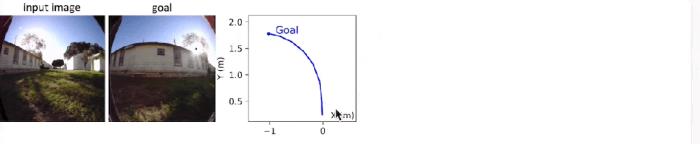
 整体而言,LeCun 团队的这项 NWM 研究做出了以下贡献:提出了导航世界模型和一种全新的条件扩散 Transformer(CDiT);相比于标准 DiT,其能高效地扩展到 1B 参数,同时计算需求还小得多。使用来自不同机器人智能体的视频和导航动作对 CDiT 进行了训练,通过独立地或与外部导航策略一起模拟导航规划而实现规划,从而取得了当前最先进的视觉导航性能。通过在 Ego4D 等无动作和无奖励的视频数据上训练 NWM,使其能在未曾见过的环境中取得更好的视频预测和生成性能。导航世界模型NWM 的数学描述下面先来看看 NWM 的公式描述。直观地说,NWM 是一个接收当前世界状态(例如,对图像的观察)和导航操作(描述物体移动到哪里以及如何旋转)的模型。然后,该模型根据智能体的视角生成下一个世界状态。本文给出了一个第一人称的视频数据集,其包含智能体导航动作
整体而言,LeCun 团队的这项 NWM 研究做出了以下贡献:提出了导航世界模型和一种全新的条件扩散 Transformer(CDiT);相比于标准 DiT,其能高效地扩展到 1B 参数,同时计算需求还小得多。使用来自不同机器人智能体的视频和导航动作对 CDiT 进行了训练,通过独立地或与外部导航策略一起模拟导航规划而实现规划,从而取得了当前最先进的视觉导航性能。通过在 Ego4D 等无动作和无奖励的视频数据上训练 NWM,使其能在未曾见过的环境中取得更好的视频预测和生成性能。导航世界模型NWM 的数学描述下面先来看看 NWM 的公式描述。直观地说,NWM 是一个接收当前世界状态(例如,对图像的观察)和导航操作(描述物体移动到哪里以及如何旋转)的模型。然后,该模型根据智能体的视角生成下一个世界状态。本文给出了一个第一人称的视频数据集,其包含智能体导航动作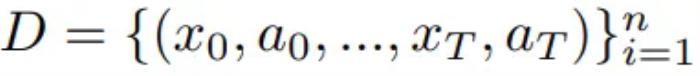 ,其中
,其中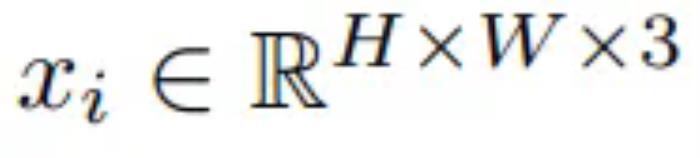 是图像,a_i = (u, ϕ) 是由平移参数
是图像,a_i = (u, ϕ) 是由平移参数 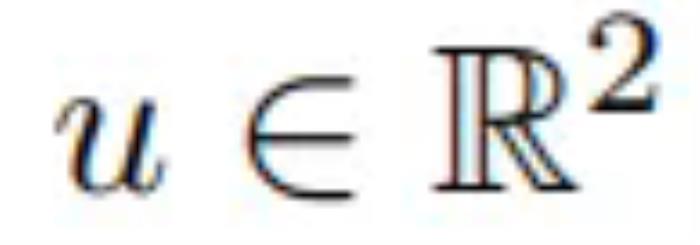 给出的导航命令,控制向前 / 向后和左右运动,以及导航旋转角
给出的导航命令,控制向前 / 向后和左右运动,以及导航旋转角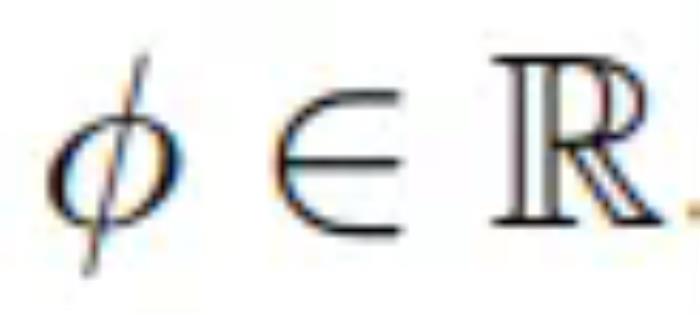 。a_i 的导航动作可以被完全观察到。目标是学习一个世界模型 F,即从先前的潜在观察 s_τ 和动作 a_τ 随机映射到未来的潜在状态表示 s_(t+1 ):
。a_i 的导航动作可以被完全观察到。目标是学习一个世界模型 F,即从先前的潜在观察 s_τ 和动作 a_τ 随机映射到未来的潜在状态表示 s_(t+1 ):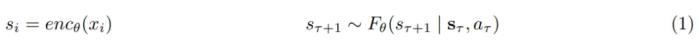 由于此公式简单易懂,因此它可以自然地跨环境共享,并轻松扩展到更复杂的动作空间,例如控制机械臂。公式 1 模拟了动作,但无法控制时间动态(temporal dynamics)。因此,作者用时移输入 k ∈ [T_min, T_max] 扩展此公式,设置
由于此公式简单易懂,因此它可以自然地跨环境共享,并轻松扩展到更复杂的动作空间,例如控制机械臂。公式 1 模拟了动作,但无法控制时间动态(temporal dynamics)。因此,作者用时移输入 k ∈ [T_min, T_max] 扩展此公式,设置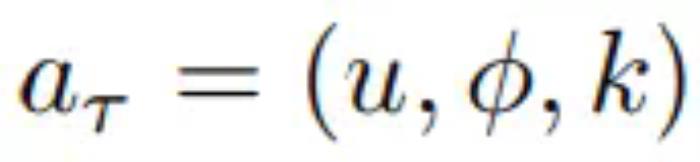 ,因此现在 a_τ 指定时间变化 k,用于确定模型应向未来(或过去)移动多少步。因此,给定当前状态 s_τ ,可以随机选择 k, token 化相应的视频帧。然后可以将导航动作近似为从时间 τ 到 τ + k 的总和:
,因此现在 a_τ 指定时间变化 k,用于确定模型应向未来(或过去)移动多少步。因此,给定当前状态 s_τ ,可以随机选择 k, token 化相应的视频帧。然后可以将导航动作近似为从时间 τ 到 τ + k 的总和: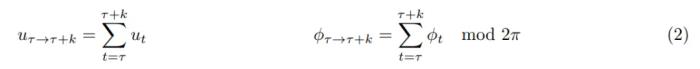 上述公式既可以学习导航动作,也可以学习时间动态。实际上,本文允许时间偏移最多 ±16 秒。扩散 Transformer 作为世界模型条件扩散 Transformer 架构。本文使用的架构是一个时间自回归 transformer 模型,该模型利用高效的 CDiT 块(见图 2)。
上述公式既可以学习导航动作,也可以学习时间动态。实际上,本文允许时间偏移最多 ±16 秒。扩散 Transformer 作为世界模型条件扩散 Transformer 架构。本文使用的架构是一个时间自回归 transformer 模型,该模型利用高效的 CDiT 块(见图 2)。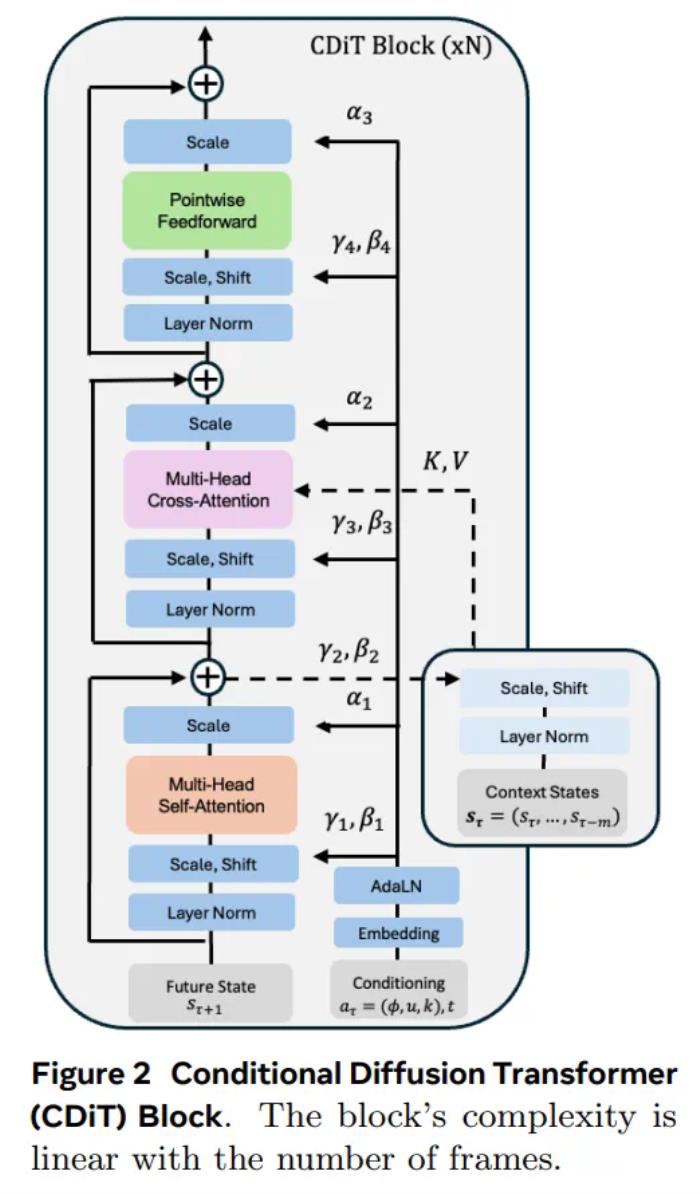 CDiT 通过将第一个注意力块中的注意力限制在正在去噪的目标帧中的 token 上,实现了在时间上高效的自回归建模。为了对过去帧中的 token 进行条件处理,本文还整合了一个交叉注意力层,然后,交叉注意力通过跳跃连接层将表示情境化。使用世界模型进行导航规划接下来,文章描述了如何使用经过训练的 NWM 来规划导航轨迹。直观地说,如果世界模型熟悉某个环境,可以用它来模拟导航轨迹,并选择那些能够达到目标的轨迹。在未知的、分布外的环境中,长期规划可能依赖于想象力。形式上,给定潜在编码 s_0 和导航目标 s^∗,目标是寻找动作序列 (a_0, ..., a_T),以最大化到达 s^∗ 的可能性。定义能量函数
CDiT 通过将第一个注意力块中的注意力限制在正在去噪的目标帧中的 token 上,实现了在时间上高效的自回归建模。为了对过去帧中的 token 进行条件处理,本文还整合了一个交叉注意力层,然后,交叉注意力通过跳跃连接层将表示情境化。使用世界模型进行导航规划接下来,文章描述了如何使用经过训练的 NWM 来规划导航轨迹。直观地说,如果世界模型熟悉某个环境,可以用它来模拟导航轨迹,并选择那些能够达到目标的轨迹。在未知的、分布外的环境中,长期规划可能依赖于想象力。形式上,给定潜在编码 s_0 和导航目标 s^∗,目标是寻找动作序列 (a_0, ..., a_T),以最大化到达 s^∗ 的可能性。定义能量函数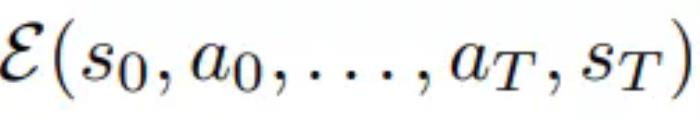 ,使得最小化能量与最大化未归一化的感知相似度得分相对应, 并遵循关于状态和动作的潜在约束。
,使得最小化能量与最大化未归一化的感知相似度得分相对应, 并遵循关于状态和动作的潜在约束。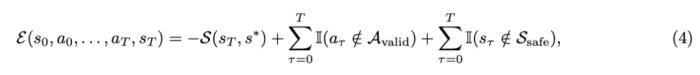 相似度的计算方法是,使用预训练的 VAE 解码器将 s^∗ 和 s_T 解码为像素,然后测量感知相似度。那么问题就简化为寻找最小化该能量函数的动作:
相似度的计算方法是,使用预训练的 VAE 解码器将 s^∗ 和 s_T 解码为像素,然后测量感知相似度。那么问题就简化为寻找最小化该能量函数的动作: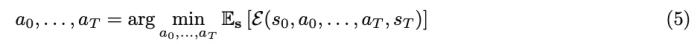 该目标可被重新表述成一个模型预测控制(MPC)问题,并且可使用交叉熵方法(Cross-Entropy Method)来优化它。导航轨迹排名方法。假设已有一个导航策略 Π(a|s_0, s^∗),可使用 NWM 来对采样得到的轨迹进行排名。这里,该团队的使用了一种 SOTA 的导航策略 NoMaD 来执行机器人导航。在排名时,会从 Π 给出的多个样本中选出能量最低的那个。实验结果下面来看看 NWM 在实验中实际表现。首先,数据集方面,该团队使用了 TartanDrive、RECON 和 HuRoN。NWM 可以获取机器人的位置和角度数据,然后推断在当前位置的相关动作。评估指标包括绝对轨迹误差 (ATE)和相对姿态误差 (RPE)。对比基线包括 DIAMOND、GNM 和 NoMaD。消融实验模型在已知环境 RECON 上对验证集轨迹对单步 4 秒未来预测进行评估。研究人员通过测量 LPIPS、DreamSim 和 PSNR 来评估相对于地面真实框架的性能。图 3 中提供了定性示例:
该目标可被重新表述成一个模型预测控制(MPC)问题,并且可使用交叉熵方法(Cross-Entropy Method)来优化它。导航轨迹排名方法。假设已有一个导航策略 Π(a|s_0, s^∗),可使用 NWM 来对采样得到的轨迹进行排名。这里,该团队的使用了一种 SOTA 的导航策略 NoMaD 来执行机器人导航。在排名时,会从 Π 给出的多个样本中选出能量最低的那个。实验结果下面来看看 NWM 在实验中实际表现。首先,数据集方面,该团队使用了 TartanDrive、RECON 和 HuRoN。NWM 可以获取机器人的位置和角度数据,然后推断在当前位置的相关动作。评估指标包括绝对轨迹误差 (ATE)和相对姿态误差 (RPE)。对比基线包括 DIAMOND、GNM 和 NoMaD。消融实验模型在已知环境 RECON 上对验证集轨迹对单步 4 秒未来预测进行评估。研究人员通过测量 LPIPS、DreamSim 和 PSNR 来评估相对于地面真实框架的性能。图 3 中提供了定性示例: 模型大小和 CDiT。研究人员将 CDiT 与标准 DiT(其中所有上下文标记都作为输入)进行比较。其中假设,对于导航已知环境,模型的容量是最重要的,图 5 中的结果表明,CDiT 确实在具有多达 1B 个参数的模型中表现更好,同时消耗的 FLOP 不到 ×2。令人惊讶的是,即使参数数量相同(例如,CDiT-L 与 DiT-XL 相比),CDiT 也可以快 4 倍,并且表现更好。
模型大小和 CDiT。研究人员将 CDiT 与标准 DiT(其中所有上下文标记都作为输入)进行比较。其中假设,对于导航已知环境,模型的容量是最重要的,图 5 中的结果表明,CDiT 确实在具有多达 1B 个参数的模型中表现更好,同时消耗的 FLOP 不到 ×2。令人惊讶的是,即使参数数量相同(例如,CDiT-L 与 DiT-XL 相比),CDiT 也可以快 4 倍,并且表现更好。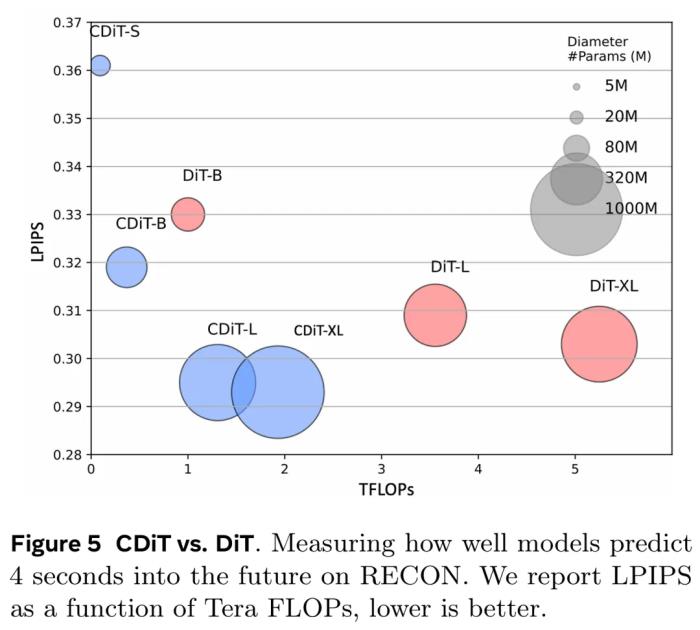 目标数量。在给定固定上下文的情况下训练具有可变目标状态数量的模型,将目标数量从 1 更改为 4。每个目标都是在当前状态的 ±16 秒窗口内随机选择的。表 1 中报告的结果表明,使用 4 个目标可显著提高所有指标的预测性能。上下文大小。研究人员在训练模型的同时将条件帧的数量从 1 变为 4(见表 1)。不出所料,更多的上下文带来了帮助,而对于较短的上下文,模型通常会「迷失方向」,导致预测不佳。时间和动作条件。研究人员同时使用时间和动作条件训练模型,并测试每个输入对预测性能的贡献程度。结果包含在表 1 中。研究人员发现,使用时间运行模型只会导致性能不佳,而不使用时间条件也会导致性能略有下降。这证实了两种输入对模型都有好处。
目标数量。在给定固定上下文的情况下训练具有可变目标状态数量的模型,将目标数量从 1 更改为 4。每个目标都是在当前状态的 ±16 秒窗口内随机选择的。表 1 中报告的结果表明,使用 4 个目标可显著提高所有指标的预测性能。上下文大小。研究人员在训练模型的同时将条件帧的数量从 1 变为 4(见表 1)。不出所料,更多的上下文带来了帮助,而对于较短的上下文,模型通常会「迷失方向」,导致预测不佳。时间和动作条件。研究人员同时使用时间和动作条件训练模型,并测试每个输入对预测性能的贡献程度。结果包含在表 1 中。研究人员发现,使用时间运行模型只会导致性能不佳,而不使用时间条件也会导致性能略有下降。这证实了两种输入对模型都有好处。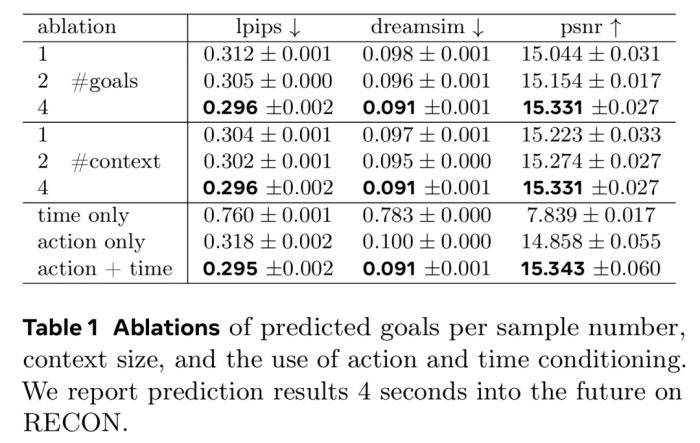 视频预测与合成这里评估的是模型遵从真实动作和预测未来状态的能力。以第一张图像和上下文帧为条件,该模型需要根据 ground truth 动作,以自回归方式预测下一个状态,并给每个预测提供反馈。通过比较在 1、2、4、8 和 16 秒的 ground truth 图像,再得出在 RECON 数据集上的 FID 和 LPIPS 值,可以对这些预测结果进行比较。图 4 展示了在 4 FPS 和 1 FPS 帧率下,NWM 与 DIAMOND 的性能情况。可以明显看到,NWM 的预测准确度比 DIAMOND 好得多。
视频预测与合成这里评估的是模型遵从真实动作和预测未来状态的能力。以第一张图像和上下文帧为条件,该模型需要根据 ground truth 动作,以自回归方式预测下一个状态,并给每个预测提供反馈。通过比较在 1、2、4、8 和 16 秒的 ground truth 图像,再得出在 RECON 数据集上的 FID 和 LPIPS 值,可以对这些预测结果进行比较。图 4 展示了在 4 FPS 和 1 FPS 帧率下,NWM 与 DIAMOND 的性能情况。可以明显看到,NWM 的预测准确度比 DIAMOND 好得多。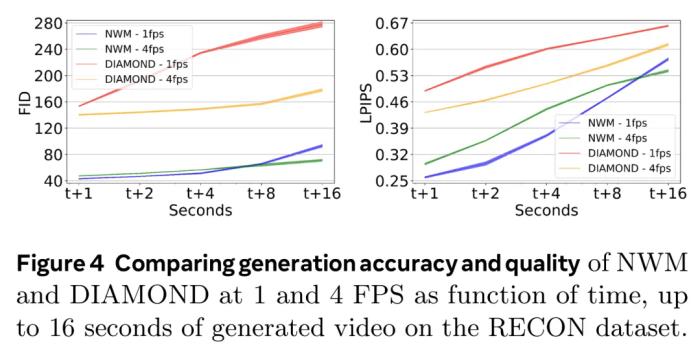 一开始的时候,NWM 1 FPS 的表现更好,但 8 秒之后,它就会因为累积误差和上下文损失而被 4 FPS 版本超过。生成质量。为了评估视频质量,该团队以 4 FPS 的速度自回归预测生成了一些 16 秒长的视频,同时这是基于 ground truth 动作的。然后,再使用 FVD 评估生成视频的质量,并与 DIAMOND 进行比较。图 6 中的结果表明 NWM 输出的视频质量更高。
一开始的时候,NWM 1 FPS 的表现更好,但 8 秒之后,它就会因为累积误差和上下文损失而被 4 FPS 版本超过。生成质量。为了评估视频质量,该团队以 4 FPS 的速度自回归预测生成了一些 16 秒长的视频,同时这是基于 ground truth 动作的。然后,再使用 FVD 评估生成视频的质量,并与 DIAMOND 进行比较。图 6 中的结果表明 NWM 输出的视频质量更高。 使用 NWM 执行规划接下来的实验衡量了 NWM 执行导航的能力。独立规划。实验表明,这个世界模型可以有效地独立执行目标导向的导航。基于过去的观察和目标图像,NWM 可以使用交叉熵方法找到一条轨迹,同时尽可能降低预测图像和目标图像之间的 LPIPS 相似度,实验结果见下表 2,可以看到 NWM 的规划能力足以比肩 SOTA 策略。
使用 NWM 执行规划接下来的实验衡量了 NWM 执行导航的能力。独立规划。实验表明,这个世界模型可以有效地独立执行目标导向的导航。基于过去的观察和目标图像,NWM 可以使用交叉熵方法找到一条轨迹,同时尽可能降低预测图像和目标图像之间的 LPIPS 相似度,实验结果见下表 2,可以看到 NWM 的规划能力足以比肩 SOTA 策略。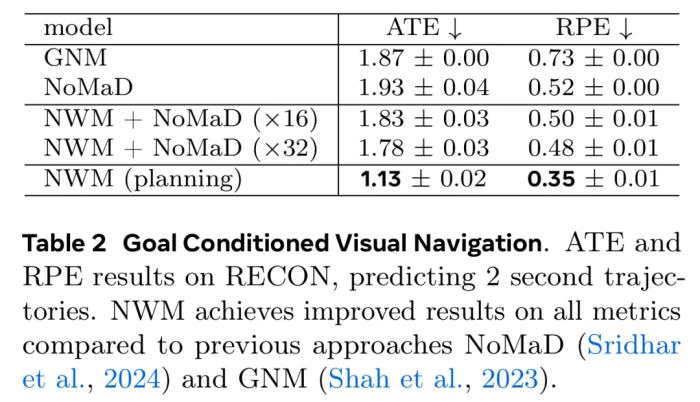 带约束条件的规划。在使用 NWM 进行规划时,还可以指定约束条件,比如要求智能体走直线或只转弯一次。表 3 的结果表明,NWM 可以在满足约束的同时进行有效规划,并且规划性能变化不大。
带约束条件的规划。在使用 NWM 进行规划时,还可以指定约束条件,比如要求智能体走直线或只转弯一次。表 3 的结果表明,NWM 可以在满足约束的同时进行有效规划,并且规划性能变化不大。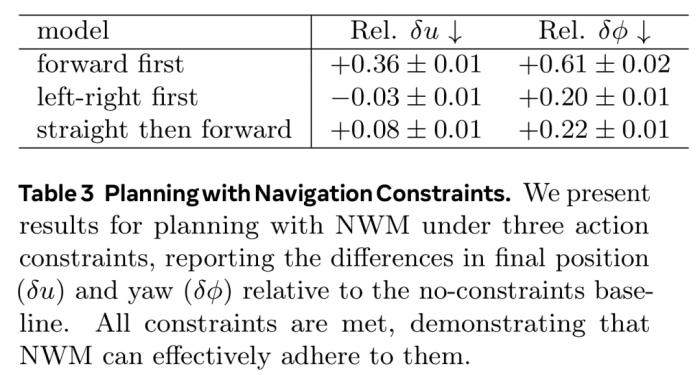 下图 9 中包含了左右优先约束下的规划轨迹案例。
下图 9 中包含了左右优先约束下的规划轨迹案例。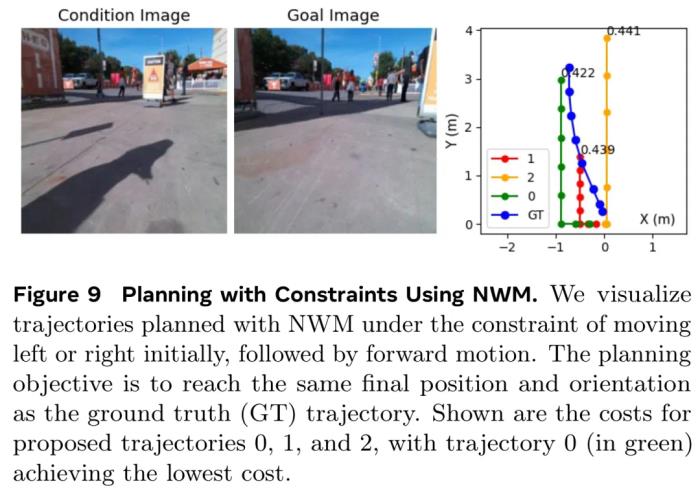 使用导航世界模型进行排序。NWM 可以增强目标条件导航中已有的导航策略。研究者根据过去观察结果和目标图像对 NoMaD 进行条件化,采样了 n ∈ {16,32} 条轨迹,其中每条轨迹长度为 8,并通过使用 NWM 来自回归地遵循动作以对这些轨迹进行评估。最后,研究者通过测量与目标图像的 LPIPS 相似性来对每条轨迹的最终预测结果进行排序,结果如下图 7 所示。他们还在上表 2 中报告了 ATE 和 RPE,发现对轨迹进行排序可以产生 SOTA 导航性能,并且采样的轨迹越多结果越好。
使用导航世界模型进行排序。NWM 可以增强目标条件导航中已有的导航策略。研究者根据过去观察结果和目标图像对 NoMaD 进行条件化,采样了 n ∈ {16,32} 条轨迹,其中每条轨迹长度为 8,并通过使用 NWM 来自回归地遵循动作以对这些轨迹进行评估。最后,研究者通过测量与目标图像的 LPIPS 相似性来对每条轨迹的最终预测结果进行排序,结果如下图 7 所示。他们还在上表 2 中报告了 ATE 和 RPE,发现对轨迹进行排序可以产生 SOTA 导航性能,并且采样的轨迹越多结果越好。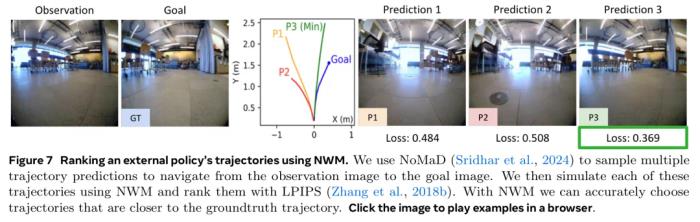 泛化到未知环境的能力研究者尝试添加未标注的数据,并询问 NWM 是否可以使用想象力在新环境中做出预测。他们在所有域内数据集以及来自 Ego4D 的未标注视频子数据集上训练了一个模型,并且只能访问时移操作。研究者训练了一个 CDiT-XL 模型,并在 Go Stanford 数据集以及其他随机图像上对该模型进行了测试。结果如下表 4 所示,可以发现,在未标注数据上进行训练可以显著提升各项视频预测结果,包括提高生成质量。
泛化到未知环境的能力研究者尝试添加未标注的数据,并询问 NWM 是否可以使用想象力在新环境中做出预测。他们在所有域内数据集以及来自 Ego4D 的未标注视频子数据集上训练了一个模型,并且只能访问时移操作。研究者训练了一个 CDiT-XL 模型,并在 Go Stanford 数据集以及其他随机图像上对该模型进行了测试。结果如下表 4 所示,可以发现,在未标注数据上进行训练可以显著提升各项视频预测结果,包括提高生成质量。 研究者在下图 8 中提供了一些定性案例。相较于域内(上图 3),模型崩溃得更快并且在生成想象环境的遍历时还会产生幻觉路径。
研究者在下图 8 中提供了一些定性案例。相较于域内(上图 3),模型崩溃得更快并且在生成想象环境的遍历时还会产生幻觉路径。

更多实验细节请参阅原论文。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










