新火种
2024-09-18
新火种
2024-09-18 


AI蛋白质折叠:在生命宇宙中漫游,远眺生物经济的流光

在2000年出版的《剑桥世界食物史》(The Cambridge World History of Food)中,记载了一则轶事:1728年,意大利学者雅可布·贝卡利(Jacopo Beccari)宣布,发现白面粉中存在具有“动物物质”全部特性的东西。他的处理方式,是将和好的生面团在水中揉搓清洗,除去细小的白色淀粉颗粒,剩下的就是粘性的面筋团,因为不知道它是从哪儿来的,人们就以为它来自动物。贝卡利认为,这些“动物物质”成分使得小麦特别有营养。作为一个整体,面粉并没有表现出动物物质特性,这是因为大量淀粉的存在掩盖了面筋的性质。
贝卡利的这一在现代人看起来无比粗糙的研究,却在无意中为后代人开启了一扇通往微观生命世界的大门。在一个世纪后的1838年,荷兰医生盖里特·穆尔德(Gerritt Mulder)发表文章称,他分析过的所有重要的“动物物质”都具有相同的基本组成:40个碳原子,62个氢原子,10个氮原子和12个氧原子,可以简单地表示为C40H62N10O12。这些“动物物质”表现出不同的性质,仅仅是因为依附于它们的硫或磷原子的个数。他以希腊海神普罗透斯(Proteus,具有预言能力,但会变换成各种形状以逃避回答问题)为名,将其正式命名为“蛋白质(protein)”。而经过他的研究,初步认定了蛋白质是构成动物和植物的基本物质之一。

再往后的故事,如大家所知,20世纪人类开始从分子层面认识和研究生命,除了DNA的秘密被揭晓,推动了生命科学领域的一次重大飞跃外,蛋白质作为生命的物质基础、生命活动的主要承担者的重要性也逐渐为科学家所发掘。而有关蛋白质的研究,特别是关于其三维构型的研究,在经历了很长一段时间缓慢的推进之后,终于在21世纪的前二十年里,被AI一举攻破,“AI蛋白质折叠”成为生命科学领域乃至整个科学研究领域最重要的研究成果。
至此,一幅全新的生物经济画卷在人们眼前逐渐展开:利用AI去设计蛋白质(而不是在自然界中挑选蛋白质)、生产契合人类需求的蛋白质产品,如药物、食品、调味品、新材料、营养保健品、化妆品等,进而推动现有以高污染、高耗能的化工原料为基础的社会生产生活重心,向着新型的、绿色环保的、可持续发展的生物基社会转变,成为当下科学家和产业界孜孜不倦的追求。

再回到当下,我们常说21世纪人类将航向两个宇宙。一个宇宙向外,去往星空深处;一个宇宙向内,去往生命科学的奥秘。近年来中国航空航天工程的快速崛起,再次打开了停滞许久的人类探索太空宇宙的大门,而这艘名为“AI蛋白质折叠”的宇宙飞船,同样由中国学者按下了起飞的按钮,也已经冲出了人类探索生命宇宙的大气层。
时值年中,正是一个阶段性回顾与总结的时间,我们不妨一起回望,它是从何而来,如何发射升空,未来还将驶向何方。

让我们回到开端,去重新了解一个我们无比熟悉又异常陌生的事物:蛋白质。
之所以说熟悉,是因为“蛋白质”在当下这个生活条件富足的时代中,出现的频次实在是太高了。各种关于饮食、保健的文章和视频都会不停地告诉我们,某某产品中富含某种蛋白(质),让大家都知道蛋白质是对身体十分重要的营养素。而说陌生,则是因为大多数人对于蛋白质的作用、价值乃至深层次的运作机制其实不甚了解。
从生命科学的角度来说,蛋白质是生命体内四种主要大分子之一(另外三种分别是核酸、多糖和脂质)。在生命体内,DNA作为生命信息的载体,负责遗传信息的存储。围绕它的研究、技术及应用,构成了20世纪人类生命科学领域最重大的进步之一。而关于它的故事,从20世纪50年代双螺旋结构的发现,到当下各种新兴医疗技术的诞生,人们已经不再陌生。
但大家不甚了解的是,遗传信息需要通过转录和翻译形成蛋白质,才能在生命体中执行各种功能。生长、发育、运动、遗传、繁殖等在内的一切生命活动都离不开蛋白质的参与,包括组成生命体、输送各类物质、抵御病毒、消化食物、提供能量、调节激素等,它也因此被称作“生命的物质基础”和“生命活动的主要承担者”。
那么,蛋白质如何能够发挥如此多的作用?
答案在于,蛋白质拥有丰富而复杂的空间结构,这些结构决定了蛋白质的功能。蛋白质以氨基酸为基本组成单位,氨基酸的不同排列(即序列)以及在此基础上的卷曲折叠,形成了特定的三维立体结构,进而执行不同的功能。人类现在已知组成蛋白质的氨基酸有20余种,如果它们可以以任意顺序和长度链接、并折叠形成不同的蛋白质,那么理论上可能存在的蛋白质数量会达到约101300,比整个宇宙中的原子数量还要多很多倍,功能更是因此丰富而复杂。
换言之,理想的情况下,如果我们可以测清氨基酸在组成蛋白质时折叠构成的三维结构,就可以了解清楚蛋白质发挥什么作用和如何发挥作用,那将对人们理解生命运行、探索生命奥秘发挥巨大的助益作用。更进一步,如果人类可以在此基础上对蛋白质进行设计、改造乃至创造自然界中尚不存在的蛋白质,引导它发挥特定的功能,那更将会产生难以估量的价值。例如,在药物研发领域,靶点、抗体药、多肽类药物、蛋白疫苗、融合蛋白药物等都是蛋白质,如果能够设计出新颖的蛋白药物,将会有更大的概率解决当前人类遇见的许多疑难杂症;在食品领域,开发优质、安全、价格低廉的替代蛋白食品,丰富人类营养来源、解决食品短缺问题;材料领域,通过优化蛋白质,开发易降解且能循环使用的环保生物材料,促进社会可持续发展等。
然而,理想很美好,现实却很曲折。仅仅为了弄清楚蛋白质的组成和结构,科学界就已经花费了近一个世纪。1902年诺贝尔化学奖获奖者、德国化学家费舍尔(Hermann Emil Fischer)在20世纪的第一个十年中,率先提出氨基酸之间的肽键相连接形成蛋白质的论点,为蛋白质结构研究开启先河。然而直到半个世纪后的1959年,英国生物学家马克斯·佩鲁茨(Max Perutz)和约翰·肯德鲁(John C. Kendrew)使用当时新兴的X射线晶体衍射技术,分别对血红蛋白和肌血蛋白进行了结构探究,人类才第一次“看清”蛋白质分子的细节,二人也因此获得了1962年诺贝尔化学奖。在同一时期,美国生物化学家克里斯蒂安·安芬森(Christian Boehmer Anfinsen)于1961年发表论文,认为蛋白质所有造成最终构象所需的信息,都被编码于其氨基酸序列上,即蛋白质一级排序决定三维结构。他的这一猜想被称为“安芬森法则”,为后来的蛋白质结构预测奠定了基石。1972年,安芬森也凭借着这一法则斩获了诺贝尔化学奖。
此后,关于蛋白质结构的研究又经历了半个世纪旷日持久的缓慢推进。科学家陆续使用晶体衍射、核磁共振、冷冻电镜等不同实验技术来测定蛋白质的三维坐标。然而,所有这些方法都存在着耗时长、花费高、成功率低等一系列问题,加上蛋白质的数量种类十分庞大,人们用实验探索蛋白质结构的努力只能算是杯水车薪。
到了90年代,计算机科学的兴起,让基于能量优化的计算方法又成为一种可能。该方法的理论基石就是前面说到的“安芬森法则”,即蛋白质会折叠到最小的能量状态,如果能把某个蛋白质的能量最优化,理论上就可以算出它的结构。而把这种方法教给计算机,就可以一步步优化能量,从而达到预测蛋白质结构的目的。
然而,基于能量优化的计算方法虽然在一段时间内取得了一定成果,结果却始终无法令人满意,预测出来的结构离实验技术测出来的结果相差非常远。究其原因,一方面蛋白质是一个非常大的体系,由成千上万个原子组成,对应一个非常大的搜索空间,构型是千变万化的;另一方面,虽然研究者普遍接受蛋白质折叠到最小能量状态,但对于“能量函数到底是什么样的”这个问题,研究者们莫衷一是。
巨大的研究价值,加上有限的研究手段和缓慢的研究进展,让蛋白质结构研究成为现代分子生物学“皇冠上的明珠”。仅在二十世纪的后四十余年内,蛋白质相关的研究成果就有七次获得诺贝尔奖,足见其研究难度和价值。
就此,深入广阔无垠的蛋白质世界、揭开更多的生命奥秘,成为生命宇宙探索的一个清晰的航向。

进入二十一世纪,机器学习逐步成为计算机科学的重要研究方向,也开始影响蛋白质结构研究。传统的机器学习方法是直接把蛋白质的氨基酸序列映射到一个三维构型上去,结果略优于基于物理或统计的方法,但并没有得到本质上的改变。
这时,一把新的钥匙出现了。
一件在AI领域众所周知的里程碑事件,是深度学习的崭露头角。2012年9月,Geoffrey Hinton等人发表了题为“用深度卷积神经网络进行ImageNet图像分类”的论文。文中提出的AlexNet深度卷积神经网络,在当年的ImageNet分类任务比赛ILSVRC-2012上以巨大的领先优势获得冠军,全面刷新了此前纪录。就此,深度学习技术异军突起,进而带动沉寂多年AI技术进入了新的高潮期,业界迎来了寒冬之后的第三次AI崛起。
深度学习算法采用了模拟大脑神经元工作方式的多层神经网络来实现。它的优势在于,可以不关注每一步的具体计算流程,而是只需要关注整体的输入和输出结果。比如在蛋白质结构研究这一领域,研究者可以提供氨基酸序列,并向AI算法提供氨基酸序列对应的结构,从而训练AI学会自主预测蛋白质结构。这个方法跨越了以往蛋白质结构预测方案的思维定式,全面激活了AI蛋白质预测的可行性。
此时,依旧坚守在蛋白质结构研究的科学家中,已经有人敏锐地注意到了深度学习这个新工具。但最初的尝试依旧并不乐观,使用深度学习后与传统的机器学习方法差别不大。深度学习与蛋白质分析的第一次相遇,并没有取得势如破竹的效果。
让这一切真正从长夜走向黎明的,是一位中国学者的研究成果。

2014年,在芝加哥大学丰田计算技术研究所任职的许锦波教授,设计了一种新的深度学习算法,从更为简单的问题入手——预测蛋白质的二级结构,即肽链主链骨架原子的空间位置排布,不涉及氨基酸残基侧链。测试发现,深度学习对这个简单问题有效。此后在2015年和2016年,许锦波教授再次开发了更好的深度学习算法,可以直接用来预测蛋白质的三维结构。
2016年夏天,许锦波教授开发出的算法RaptorX-Contact,证明了深度残差卷积神经网络可以大幅度提高蛋白质结构预测的性能,并在当年的全球蛋白质结构预测比赛(CASP12)中,在蛋白质接触矩阵的预测上得分居首位,引发学界关注。在此之前,CASP的平均得分一直在30分左右徘徊,而许锦波教授的算法一举将纪录提升到了60分,实现了真正的颠覆性突破。相关成果于2017年发表于国际计算生物学会官方期刊PLoS Computational Biology,后来获得PLoS Computational Biology创新突破奖。
至此,蛋白质宇宙的大门,终于被“AI”这把钥匙打开了。
此后,许锦波教授继续优化和推广这一算法,他的核心思想也快速被业界其他研究者采纳,并相继用于各种AI蛋白质折叠算法的开发。一时间,用深度学习方法研究蛋白质结构的成果出现了井喷。仅许锦波教授自己,就很快在随后的研究中进一步认识到,氨基酸之间的距离预测,不能一对一对预测,要所有对一起预测,并又一次率先开发出端到端模型。相关成果于2019年8月在美国国家科学院院刊(PNAS)发表,全球范围内首次将AI应用至蛋白质氨基酸(原子)之间的距离预测,进一步提升了蛋白质三维结构预测的精度,且让科学家仅需使用笔记本电脑就能完成这项工作,将AI蛋白质结构预测又推向了一个新的高度。
再往后的故事,大家都知道了。DeepMind推出的AlphaFold 2在2020年的CASP 14中,实现了对大部分蛋白质结构的预测与真实结构只差一个原子的宽度,达到了人类利用冷冻电镜等复杂仪器观察预测的水平,引发了全球科学界海啸般的轰动。当年,AI预测蛋白质结构就被《科学》杂志评为“十大科学突破之一”,2021年又被评为“十大科学突破”之首,2022年又入选了《麻省理工科技评论(MIT TR)》十大突破性技术。

不过,在此期间,还有一个不被外界熟知的小故事。
在2016年秋天,许锦波教授召开了一个小型报告会,向学界人士介绍RaptorX-Contact的研究成果。其中一位参会者,就是芝加哥大学生物物理系的博士后、后来领导DeepMind团队、设计了AlphaFold的John Jumper。在听完报告后,后者全力转向深度学习方法,并在一两个月后加入DeepMind。
后来,业界普遍认为,AlphaFold的早期版本,其实现方式并没有太多创新,而是基于RaptorX-Contact的算法思想。而AlphaFold 2中的关键思想,即端到端模型,根据序列的特征直接输出三维结构,同样与前述许锦波教授于2019年发布的研究成果异曲同工。也正因为如此,AlphaFold取得的成果,还曾在业内引起过一段争议:相比较大学校园中的科研活动,大企业支持的商业实验室,其成果是否更多是精湛的工程技术,而非创新的科学见解?
当然,这段历史现在已经有了公论。CASP比赛的创办人,马里兰大学细胞生物学和分子遗传学系教授约翰·莫尔特(John Moult)就曾表示:“DeepMind在开发一种非常有效的方法方面做得很好。然而,这项工作背后的概念和方法并非凭空而来,关键技术是深度学习方法的应用。毫无疑问,DeepMind直接建立在许锦波的工作之上。”
站在当下,AlphaFold为生命科学带来的巨大影响无法被否定。但中国学者许锦波在推动AI蛋白质研究、AI for Science的道路上做出的先驱、开创性的成果,也同样不该被人忘记。

正如本文第一部分所说,测清蛋白质的三维结构,将对人们理解生命运行、探索生命奥秘发挥巨大的助益作用。在此基础上,如果我们可以对蛋白质进行重新设计、引导它发挥特定的作用,乃至生成全新的蛋白质,那更将会产生难以估量的价值。就此而言,许锦波教授和他的RaptorX-Contact开了一个头,但这只是一个开始。毕竟在深邃的生命宇宙中,还有更多的未知等待着人们去发现。比如,对AI蛋白质结构预测的手段进行优化,进而探明更多蛋白质的结构、更深入地理解生命运行的机制;再比如,更具有应用想象力的AI蛋白质优化与设计。
由于AlphaFold 2擅长的是预测和计算单个蛋白质的结构,仅能够做预测且高度依赖MSA(来自同源蛋白质的多序列比对)及其衍生的共进化信息和序列谱,而蛋白质世界具有的巨大复杂性,意味着蛋白质结构预测还有很大的探索空间,例如蛋白质与其他分子的相互作用、单点突变对蛋白质结构和功能的影响、孤儿蛋白质结构预测、蛋白质侧链预测等。因此,仅AI蛋白质结构预测领域,在AlphaFold 2出现后就仍然不断有前沿成果涌现。

例如,2021年,“科学突破奖”获得者,被称作“上帝之手”的华盛顿大学教授David Baker领导来自华盛顿大学、哈佛大学、德克萨斯大学西南医学中心等团队发布的AI工具RoseTTAFold,拥有媲美AlphaFold 2蛋白质结构预测的超高准确度,而且更快、所需计算机处理能力更低,不仅可以预测单个蛋白质结构,还能预测蛋白复合物结构,但和AlphaFold 2类似,依赖于使用MSA和相似蛋白质结构的模板来实现最优表现。2022年,META也曾推出ESMFold,其在预测蛋白质的三维结构方面与AlphaFold 2能力相当,且能预测孤儿蛋白的结构,计算速度比AlphaFold 2快了一个数量级,单序列输入时精度也明显好于AlphaFold 2。不过后来META解散了该团队,停止在这一领域继续大规模投入。除了这两个在业内大名鼎鼎的团队之外,在其他一些AlphaFold 2没有很好解决的问题方面,仍有研发团队不断取得超过前人的成果。
这里还有一个小插曲。2024年5月8日,谷歌旗下公司DeepMind和Isomorphic Labs合作,正式发布了蛋白质结构预测领域的最新AI模型AlphaFold 3。DeepMind宣称,AlphaFold 3能预测含有蛋白质数据库(Protein Data Bank)内几乎所有分子类型的复合物的结构,包括配体(小分子)、蛋白质、核酸(DNA和RNA)如何聚集在一起并相互作用,以及预测翻译后修饰和离子对这些分子系统的结构影响,从而帮助我们在原子水平上精确地观察生物分子系统的结构。不过,这一全新版本暂时不开源代码,需要等到六个月以后,才能将代码和模型权重提供给学术界使用。因此,新版本能在多大程度上超越前作,谜底还有待进一步揭开。
而在AI蛋白质结构预测继续取得突破的同时,也有目光长远的科学家转向了更具产业应用价值的AI蛋白质优化与设计。
以生物医药为例,此前,由于对蛋白质结构与功能的理解不够深入,生物药的开发一定程度上受到了局限。而如果可以运用AI对蛋白质进行优化与设计,则有希望加速提升蛋白质药物的性质,获得更理想的功能,甚至可借助AI,根据靶点按需快速生成新的蛋白质药物乃至自然界不存在的全新药物分子,很多过去缺少解药,甚至被视为没有解药的疾病,有了被治愈的可能。

同理,在其他诸如合成生物、农业、食品、新材料等更广泛的领域,AI蛋白质优化与设计技术还有更多、更丰富的想象力。例如,在当下发展势头迅猛的合成生物领域中,酶(也是一类蛋白质)被广泛使用用于生物催化,如果可以设计和改造酶的结构和功能,提高催化效率、稳定性和选择性,将极大提升生物合成、催化与转化的效率。或者,直接设计具有特定功能的蛋白质制品,比如,开发更易于人体吸收、更富营养的替代蛋白食品;研发对人类安全无害、对环境友好的绿色生物农药;开发强有力的塑料降解催化剂帮助消除污染;创造更有延展性和韧性的纤维材料从而提升航空工业水平;提升农作物的产量、品质,培育更多绿色高产的农作物产品……如此多的应用方向,还有待人们开发强有力的蛋白质优化与设计工具逐一去探索解决。
但相比蛋白质结构预测,蛋白质设计是一个更加困难的问题。
首先,蛋白质序列空间非常大。自然界有20余种氨基酸,假设我们需要设计1个带有100个氨基酸的蛋白质,这个蛋白质的序列空间就有20100种可能性。但是这个巨大的序列空间中仅有很小比例的氨基酸序列可以稳定折叠,且具有我们所需的特定功能。因此,要在巨大的空间中找到符合需求的氨基酸系列,无异于大海捞针。
其次,基于特定功能设计蛋白质,需要对蛋白质结构、功能的深入理解,而这对科学家和产业界而言,仍是难题。
再次,产业界对蛋白质的需求复杂多样,比如根据特定靶点设计蛋白药物,设计可催化特定底物的酶,或是提升现有酶的催化效率等,这无疑又加大的蛋白质设计研究的复杂程度。
以有“万能生物催化剂”之称的P450酶(CYP)为例。作为一个在生物体内广泛分布的庞大酶家族(包含多个家族、亚家族和酶个体,具有高度的多样性和复杂性),它能够催化多种反应类型,且可识别的底物(即可与其发生生化反应的物质)范围极广,因而在药物合成,以及合成生物领域的应用中具有极大的潜力。由于天然存在的P450酶无法完美契合工业需求,因此改造现有或设计具备新功能的P450酶,从而拓宽其应用范围的需求就应运而生。然而,大多数P450蛋白的长度约为4—500个氨基酸,这就意味着,设计出新P450的可能性就达到了20400-20500,比宇宙中所有原子的数量(有预计可达到1078x1082)还要多得多,想找到合适的那一种无异于在大海中捞针。不止如此,由于P450酶的催化反应需要适配的辅酶,这就意味着设计具备新功能的P450酶,还需要同时考虑其他蛋白质与其相互作用的情况,这让设计新酶的复杂度呈指数型上升。
在没有AI技术以前,科学界也在运用一些方法,试图在浩如烟海的蛋白质宇宙中,寻找可能对人类有价值的蛋白质分子,并有目的地对蛋白质分子进行优化设计,使其更好地为人类所用。例如,定向进化和理性设计。前者主要是模拟自然选择的过程,对目标基因进行多轮突变和筛选实验,直至获得所需的优良变体;后者则是依据序列和结构信息,选择较少的关键位点进行精准改造。但两者都具有很明显的缺陷。前者通过模拟自然选择过程,对目标基因进行多轮突变和筛选实验,直至获得所需水平的优良变体,但是该技术受限制于较低的筛选速率和序列空间中庞大的变体数量。后者依据序列和结构信息,选择较少的关键位点进行精准改造,从而构建较小的突变文库,但是需要对结构功能信息有深入了解,并且当实验结果不符合预测时无法调整。像前述的P450酶,想要找到理想的新分子,研究者们可能花费毕生的精力,也未必能得到想要的成果——从20世纪50年代P450酶被首次发现以来,研究界还从未能够通过人工设计的方式得到新的分子,仅仅是对某些已存在的分子进行了部分改造优化。研究界需要更有力的工具方法,更快、更精准地设计符合需求的蛋白质。

2018年以后,许锦波教授率先将研究范围扩展至AI蛋白质优化与从头设计,并将预训练机制引入其中,进一步探索AI蛋白质技术的产业应用路径。他先后推出了十余项技术,比如,可同时用于蛋白质侧链预测与序列设计的算法,性能媲美ESMfold的单序列结构预测算法,精度超越AlphaFold 3的复合物预测算法等,并创新性地融合AI与分子动力学、量子化学等技术,解决科学与产业问题。这些技术不仅在测试中表现出了世界领先的性能,也在湿实验中得到验证,迅速被一些跨国药企、生物科技公司所采用。2021年底,他回国创建了名为“分子之心”的AI蛋白质优化与设计平台公司,并快速推出了业内首个功能完整的AI蛋白质优化与设计平台MoleculeOS,推动相关研究成果尽快实现更大的应用价值与社会价值。
除了许锦波教授以外,其他团队也在陆续发表AI蛋白质设计算法,探索各种功能性蛋白质生成,只是成果仅限于计算层面,未有公布产业应用结果。2022年9月,David Baker团队又开发出一种名为ProteinMPNN的从头设计蛋白质的深度学习工具,确定与给定蛋白质结构相对应的氨基酸序列,短短几秒钟之内就能够根据自主意愿快速生成全新蛋白质,不过无法要求蛋白具备某种性质;2023年7月,该团队又发布了一种能从头设计全新蛋白质的深度学习方法RoseTTAFold Diffusion,其基于扩散模型(diffusion model),能生成各种功能性蛋白质,包括在天然蛋白质中从未见过的拓扑结构,但与ProteinMPNN类似,无法进行精确的条件式生成,让蛋白具有某种特定的性质。2022年12月,Generate Biomedicines也公布了一个名为Chroma的项目,同样借助扩散模型(diffusion model),生成自然界中没有的全新蛋白结构,并生成了模拟26个英文字母和10个阿拉伯数字形态的全新蛋白结构。然而,Chrome无法基于功能需求产生蛋白,也不能指导如何评估生成的蛋白的功能性,因此更类似于科研工作,对产业应用有多少价值还有待进一步挖掘。
AI蛋白质优化与设计工具如雨后春笋般地出现,让关于AI蛋白质宇宙的探索,又进入到一个更深邃的空间。

当时间进入2023,已经驶入深空的AI蛋白质研究又获得了新的助推器——大模型。
2022年年底,以ChatGPT为代表的大语言模型掀起了新的AI热潮,运用AI大模型解决产业问题成为一种新的趋势。而在科学家们看来,生物是一个高度数字化的系统,具备可解读、可编程的特性,因而大模型的生成能力同样可以应用在生命科学领域,二者可以说是天作之合。
不过,诸如ChatGPT之类的AI大模型,侧重于通用领域的文本、图片、视频等内容生成,无法满足诸如蛋白质生成之类的产业深度需求。原因在于,蛋白质序列形成的结构比自然语言的结构复杂得多,数据也比自然语言复杂得多,涉及高度专业、多样的蛋白质大数据。现代的通用大模型底层架构无法精准地对这些蛋白质多模态数据精准建模,要做好蛋白质生成,必须从底层建立更新、更强大的AI建模技术。因此构建AI蛋白质生成大模型、提升蛋白质设计的效率和成功率,也成为业内关注的新方向。

研究界在近几年陆续产生一些成果。例如,2020年,AI研究机构Salesforce Research、合成生物学公司Tierra Biosciences和加州大学旧金山分校的一组研究人员联合构建的ProGen,能够以类似“遣词造句”的方式生成跨多个蛋白质家族且功能可预测的蛋白质序列。但其只能接受序列信号、无法接受结构信号,不能够同时考虑结构、功能、相互作用、进化等信息,成功率较低,也无法精准地实现产业应用中所需要的功能。而在国内,2023年,百图生科与清华大学联合提出了千亿参数的蛋白质语言模型xTrimoPGLM,探索了蛋白质理解和生成这两种类型目标之间的兼容性以及共同优化的可能性,能够对单个蛋白质、细胞中蛋白质相互作用、细胞本身,以及细胞系统建模。2024年6月,由前Meta AI研究人员创立的Evolutionary Scale AI发布了蛋白质语言模型ESM3,能力超越了前述两种,支持序列、结构、功能的同时推理,但目前仍存在生成精度不足、使用特别复杂、无法微调等问题。
率先取得产业应用成果验证的,还是许锦波教授及其团队。在分子之心成立不久后的2023年,团队又推出了业界首个集成序列、结构、功能和进化的产业级AI蛋白质生成大模型“NewOrigin(达尔文)”,不仅具备成功率高、普适性高等优势,从而通过计算的方式,规避了传统方法对大规模湿实验(即生物实验)的依赖,提高生产效率、降低成本,还可以让不具备AI算法背景的生物学家,通过对话的形式与大模型进行交互。
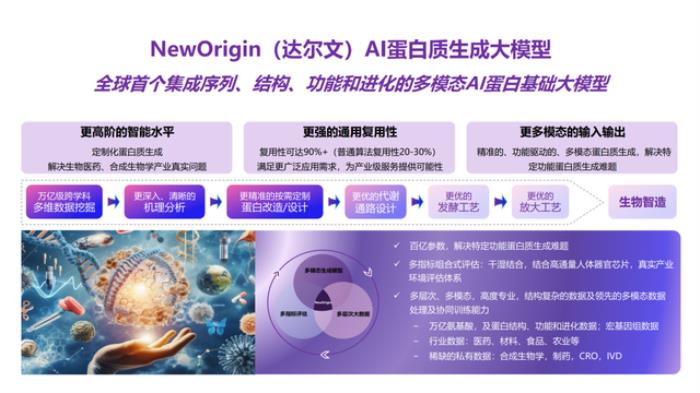
此后,团队积极地将其投入应用于产业项目,在产业实践中一边获得反馈、一边进行优化。不到一年的时间里,就取得了多个产业应用成果。例如,在生物材料领域,运用NewOrigin帮助合作伙伴优化一种涉及行业瓶颈,但极具商业价值的关键蛋白质,在未使用产业场景数据的情况下,相对于野生菌,AI设计的一个重要酶蛋白结构使菌种产率提高了5倍,有望让这一被持续改造了数十年的蛋白质实现性能飞跃,从而带动产率大幅提升、成本大幅降低;在创新药研发领域,针对某蛋白疫苗的稳定性、表达量等进行多目标优化,AI优化后的疫苗,经过动物实验表明,产生中和抗体滴度达到已公开专利和相关大型药企同类疫苗的数倍,并突破相关疫苗稳定性专利。而AI设计的一条细胞因子管线,在保持抑制肿瘤活性的同时,减毒(减少外周活性)数百倍,猴子耐受剂量达到同类管线的数十倍……成功的产业应用成果,证实了AI蛋白质大模型的强有力能力。
大模型的表现初露锋芒,让人信心倍增。在大模型的加持下,过往蛋白质研究的“挖矿寻宝”碰壁试错的模式,将变成“按图索骥”的新方式,甚至有可能从头“发明”具备特定功能的全新蛋白质。而通过可编程的蛋白质设计技术,将解决传统方法无法满足的需求,极大地提升药物研发、合成生物、新材料、食品、农业、环保等领域的研发效率,并降低成本。一个由AI蛋白质大模型作为底层技术支撑、从而推动生物制造产业更加欣欣向荣的场景,已然跃入眼前。
值得一提的是,2024年9月,分子之心宣布完成A轮融资。融资额达数亿元人民币,由谢诺投资、深创投联合领投,商汤国香资本、久奕投资跟投。截至此次融资,分子之心累计完成3轮融资,过往投资方包括合成生物学龙头企业凯赛生物、红杉中国、百度BV、联想创投等。至此,分子之心可以说已经成长为具有行业标杆地位的AI生物大分子设计平台公司,为中国AI生物基础设施建设打开了新的局面。
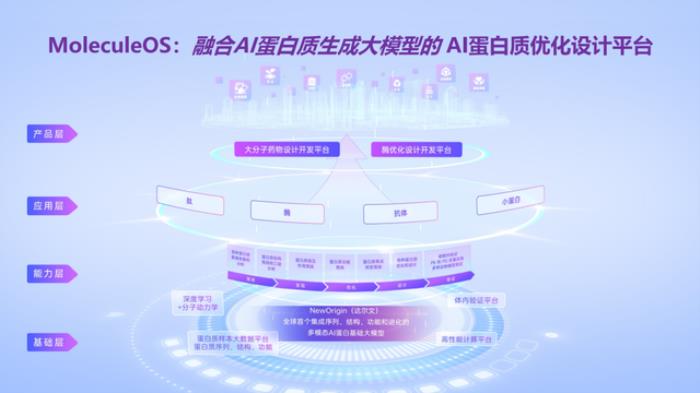
许锦波教授表示,本轮融资将用于进一步扩大顶尖复合型技术及产业人才团队,推进高性能算力平台、智能化高通量湿实验室等硬实力建设,深入AI蛋白质基础大模型、AI蛋白质优化设计平台MoleculeOS等生物经济基础设施建设,更进一步推动AI蛋白质技术的产业级应用及商业化发展。
有了大模型这一助推器,AI蛋白质宇宙深空中的繁星愈发触手可及。

二十世纪的后五十年中,人们见证了以基因技术为代表的生物科技日新月异,以及在此基础上医疗健康水平的提升、农牧业生产改善与丰富。进入二十一世纪,合成生物学、AI蛋白质折叠为代表的新一代生物科技兴起。一种不依赖化石能源,而是通过生物制造与生物产品推动社会发展的新科技通道,跃入了人类社会的想象。
麦肯锡全球研究院曾在2020年发布的一份研究报告中指出,全球经济活动中60%的物质产品可以通过生物技术进行生产,其涉及市场规模可能高达4万亿美元。面对如此巨大的经济价值,以及化石能源走向枯竭、环境污染日益严重的问题,世界各国纷纷在生物经济、生物科技的创新应用等方面展开顶层设计与前瞻性布局。希望能够在生物经济时代的大变局中占得先机。
目前,包括中、美、日、欧盟等60多个国家或地区已经制定了生物制造或生物经济的专门政策,更新国家与地区生物经济发展战略,以及制定生物制造发展路线图和行动计划等。
其中,在2022年美国白宫启动了《国家生物技术和生物制造计划》,并于2023年发布“生物技术和制造目标”时间表,成立国家生物经济委员会,明确要大幅度提升生物制造的速度、成功率和创新效率,解决生物实验法无法解决的问题;2024年3月,欧盟委员会发布题为“与自然共建未来:推动生物技术和生物制造”的政策文件,提出采取有效利用研究成果并促进创新、刺激市场需求、简化监管途径、鼓励公共和私人投资、制定并更新标准、开展国际合作等一系列针对性措施,促进欧盟生物技术和生物制造发展;2024年5月,日本政府提出,2030年实现100万亿日元市场规模的生物经济。在生物制造方面,将推动建立生物技术和AI等数字技术融合的微生物和细胞设计平台,并完善生物工厂等基础设施。在中国,2022年《“十四五”生物经济发展规划》首次专门针对生物经济进行规划,明确将生物制造作为生物经济战略性新兴产业发展方向;2024年“生物制造”作为新增长引擎首次被写入两会政府工作报告。
在这样的时代背景下,AI蛋白质折叠可谓占据着“牵一发动全身”的意义。这项技术融合了AI技术的飞速发展与生物经济的巨大价值。兼两家之长,成未有之事。
在AI蛋白质相关领域,承接DeepMind创新研究成果的Isomorphic Labs正在与诺华、礼来的AI药物开展战略合作;AI驱动的蛋白质设计公司Generate Biomedicines接受了生物科技巨头安进(Amgen)的19亿美元投资,用于开发蛋白质疗法;合成生物领域的代表企业Ginkgo Bioworks正在与Google Clouds合作,开发新的大语言模型应用于药物发现、生物安全等领域,并与美国国防部高级研究计划局(DARPA),围绕如何利用无细胞蛋白质合成(CFPS)技术、按需制造蛋白质展开合作;英伟达在2023年连续投资九家应用生成式AI进行药物研发的初创企业……资本、技术、应用等众多力量的加入,将会加速AI蛋白质技术的进一步开发,带来更快、更大规模的应用落地。
站在2024年的时间线上,可以笃定的是,由AI蛋白质折叠解锁的生命宇宙航线,即将为生物经济与人类健康事业,带来更加多彩的流光。

原文标题:AI蛋白质折叠:在生命宇宙中漫游,远眺生物经济的流光
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。