

 新火种
2024-01-05
新火种
2024-01-05 


谷歌联合高校研发通用模型ProteoGAN,可设计具有新功能的蛋白质
近年来,随着医学与生物技术的发展,蛋白质设计的重要性正在不断提高。以目标功能为起点来进行新型蛋白质的设计,在发现新的药物等方面有广阔的应用前景。
然而,由于蛋白质的序列结构与功能之间存在超级复杂的机制,对它进行设计往往耗时耗力,需要庞大的投入。最近,机器学习在该领域的引入有效地快速解决了由于复杂性而难以达成的许多任务,例如,全新治疗方法的开发、设计特定功能的催化剂等。
不过,目前机器学习在蛋白质设计领域的应用,往往只专注于某个特定应用,或只能进行某个蛋白质族系内的新型设计。目前,蛋白质设计领域还没有一种通用模型,可以针对各种应用进行各个蛋白质族系中的新型蛋白质设计。

(来源:资料图)
最近,来自苏黎世联邦理工学院生物系统机器学习与计算机生物系博士生蒂姆·库切拉(Tim Kucera)、马泰奥·托尼纳利(Matteo Togninalli)博士以及来自谷歌研究院大脑团队研究员莱蒂蒂亚·孟·帕帕杉索斯(Laetitia Meng-Papaxanthos)共同发布了 ProteoGAN 模型,为基于条件的蛋白质设计提供了一种通用生成模型。
相关论文以《用于按照层级功能进行从头蛋白质设计的条件生成模型》(Conditional generative modeling for de novo protein design with hierarchical functions)为题发表在 Bioinformatics 上[1]。
该研究团队开发 ProteoGAN 这一蛋白质设计通用模型的背景之一,还有最近在自然语言生成等深度学习的其他子领域中,通用模型的影响力越来越大,其表现比只专注于某个特性功能的模型更佳。
因此研究人员假设,如果是在蛋白质设计领域,同样有模型有能力学习各种不同蛋白质族系的共同原理,这种模型所生成新型蛋白质的质量也会更贴近需求。而且,这种模型甚至可能创造蛋白质此前没有的新的功能。
(来源:Bioinformatics)
对于生成类的模型来说,对其进行评估是一件难事,这主要是因为没有可以将所生成的样本进行参照对比的基本参照物。尤其是在蛋白质设计中,对于结果的验证更加复杂,很难将所生成的数字结果真实地物理合成出来,以证实该新型蛋白质确实拥有设计需要的功能。在该研究中,研究人员选择天然蛋白质作为参照物,将模型生成的蛋白质序列与之对比,来进行模型的评估。
在对模型评估的具体指标方面,研究人员也进行了深度的考量。在模型的分布相似度的评估中,团队选择了 MMD 方法进行评估;在模型的条件一致性的评估中,团队选择了平均倒数秩方法。为预测模型所生成的序列的多样性,该团队结合采用对偶性差距、特征维度上的平均熵以及序列之间的平均成对 RKHS 距离等多种方法。
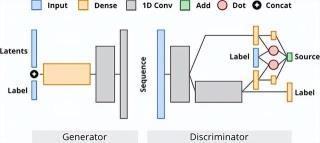
基于所设置的对模型所设计生成的蛋白质进行评估与比较的方法,简单来说,研究人员将 ProteoGAN 的模型架构设计为:在标签集 GO 中给定一系列函数时,可以生成蛋白质序列的基于条件的 GAN 模型。其中,GO 可以对蛋白质功能进行描述的一系列标签,而 GAN 模型则是一个已经在蛋白质序列设计方面被证实表现优异的模型。
在 ProteoGAN 的生成器和筛选器中,都含有卷积层和跳过连接。其中在生成器中,标签与结构中的潜在噪声向量输入进行链接。在筛选器中,研究人员对各种不同的条件反射机制进行了探究。
为了解 ProteoGAN 模型的表现,研究人员将该模型在 UniProt 知识库进行应用。在模型对该知识库进行训练之后,模型共生成了 157891 个新的蛋白质序列。其中,研究人员将功能标签的总数限制成 50,而将每个标签所相应的最少序列数设置为大约 5000。
此外,研究人员还将数据集进行了随机拆分,将其分为训练集、验证集和测试集。其中,验证集和测试集中的序列数量都大约占整个生成数据级的 10%,约有 15000 个序列。
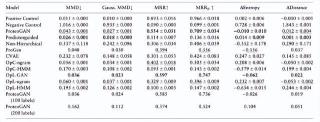
在对 ProteoGAN 模型生成的蛋白质序列结果进行评估时,研究人员将其与此前更经典的概率语言模型和 HMM、CVAE、ProGen 等目前最新最前沿的蛋白质生成深度学习模型进行了对比。
(来源:Bioinformatics)
为了解 ProteoGAN 的不同方面的影响,研究人员将模型进行不同方面的更改并与其进行比较。其中,所更改之后的不同“模型”分别有:每个标签只有一个实例对应的 One-per-label GAN (OpL-GAN)、将 ProteoGAN 的调节机制去除的 Predictor-Guided、以及将标签分层去除的非分层模型(Non-Hierarchical)。
通过使用之前设定的 MMD、MRR 等方法进行对比之后,研究人员发现,在分布相似性、条件一致性和多样性等各个指标方面,ProteoGAN 模型的性能都优于其他对比模型。
参考资料:
1.Tim Kucera et al. Bioinformatics 38, 13, 3454–3461(2022).

相关推荐


- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
