新火种
2024-01-05
新火种
2024-01-05 


字节具身智能新成果:用大规模视频数据训练GR-1,复杂任务轻松应对
如何利用大规模的视频数据来帮助机器人学习复杂任务?
最近 GPT 模型在 NLP 领域取得了巨大成功。GPT 模型首先在大规模的数据上预训练,然后在特定的下游任务的数据上微调。大规模的预训练能够帮助模型学习可泛化的特征,进而让其轻松迁移到下游的任务上。但相比自然语言数据,机器人数据是十分稀缺的。而且机器人数据包括了图片、语言、机器人状态和机器人动作等多种模态。为了突破这些困难,过去的工作尝试用 contrastive learning [1] 和 masked modeling [2] 等方式来做预训练以帮助机器人更好的学习。在最新的研究中,ByteDance Research 团队提出 GR-1,首次证明了通过大规模的视频生成式预训练能够大幅提升机器人端到端多任务操作方面的性能和泛化能力。
实验证明这种预训练方法可以大幅提升模型表现。在极具挑战的 CALVIN 机器人操作仿真数据集上,GR-1 在 1) 多任务学习 2) 零样本场景迁移 3) 少量数据 4) 零样本语言指令迁移上都取得了 SOTA 的结果。在真机上,经过视频预训练的 GR-1 在未见过的场景和物体的表现也大幅领先现有方法。
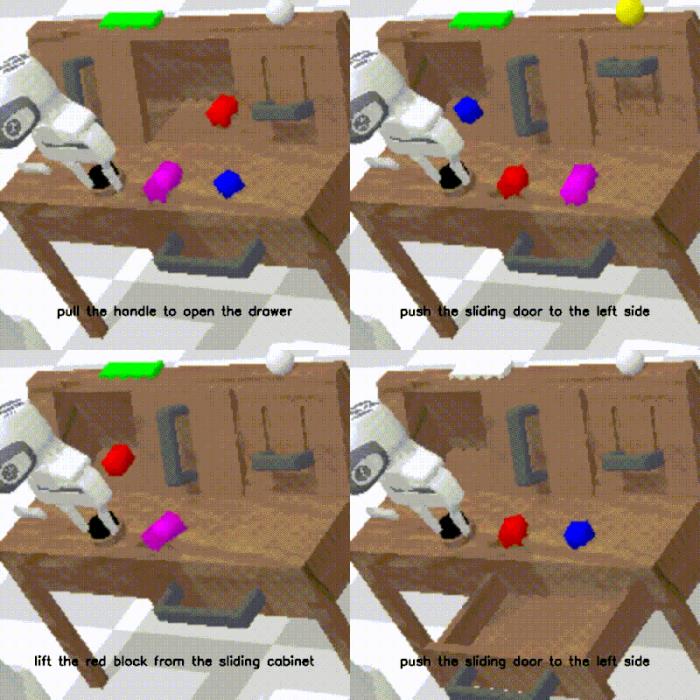



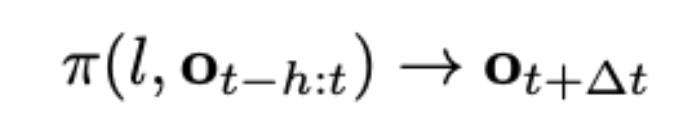
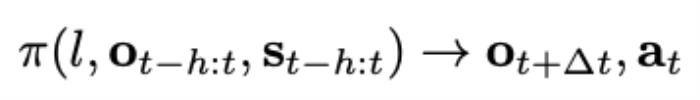
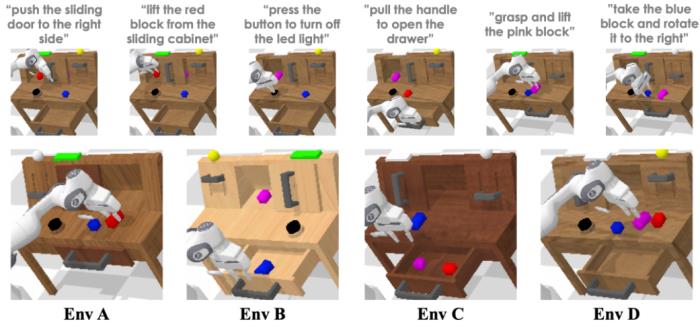
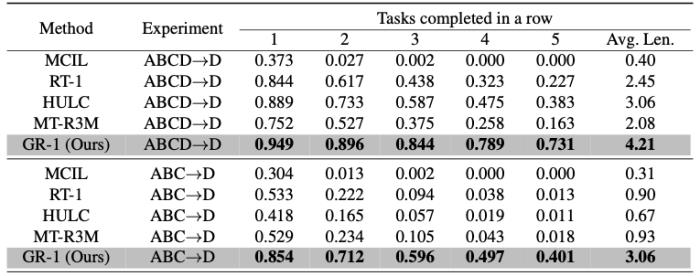
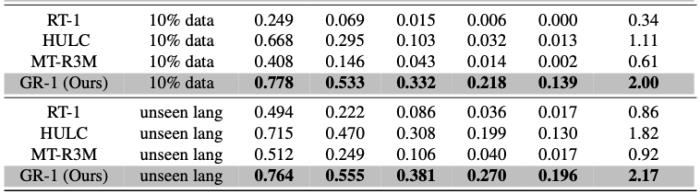
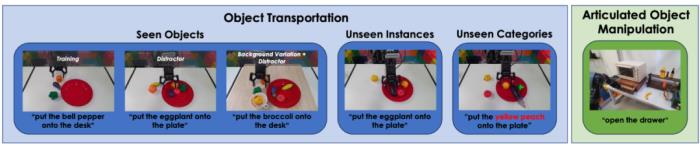








在消融实验中,作者对比了去掉未来帧预测和保留未来帧预测但去掉预训练的模型的能力。结果表明预测未来帧和预训练两者都对 GR-1 学习鲁棒的机器人操作起到了关键作用。在预测动作的同时加入未来帧的预测能帮助 GR-1 学习根据语言指令来预测未来场景变化的能力。这种能力正是机器人操作中需要的:根据人的语言指令来预测场景中应用的变化能够指导机器人动作的生成。而大规模视频数据的预训练则能帮助 GR-1 学习鲁棒可泛化的预测未来的能力。结论GR-1 首次证明了大规模视频生成式预训练能帮助机器人学习复杂的多任务操作。GR-1 首先在大规模视频数据上预训练然后在机器人数据上进行微调。在仿真环境和真机实验中,GR-1 都取得了 SOTA 的结果,并在极具挑战的零样本迁移上表现出鲁棒的性能。
参考文献
[1] Nair, Suraj, et al. "R3m: A universal visual representation for robot manipulation." arXiv preprint arXiv:2203.12601 (2022).
[2] Xiao, Tete, et al. "Masked visual pre-training for motor control." arXiv preprint arXiv:2203.06173 (2022).
[3] Grauman, Kristen, et al. "Ego4d: Around the world in 3,000 hours of egocentric video." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[4] Radford, Alec, et al. "Learning transferable visual models from natural language supervision." International conference on machine learning. PMLR, 2021.
[5] He, Kaiming, et al. "Masked autoencoders are scalable vision learners." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.
[6] Jaegle, Andrew, et al. "Perceiver: General perception with iterative attention." International conference on machine learning. PMLR, 2021.
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。