

 新火种
2024-09-14
新火种
2024-09-14 


字节AI版小李子一开口:黄风岭,八百里
字节和浙大联合研发的项目Loopy火了!
只需一帧图像,一段音频,就能生成一段非常自然的视频!
研究团队还放出了Loopy和同类应用的对比视频:
网友下场齐夸夸:


真这么牛?咱们一起来看一下!
 Loopy的生成效果
Loopy的生成效果研究团队放出了一些DEMO视频,内容脑洞跨度有点大!
比如让小李子唱《黑神话》灵吉菩萨的陕北说书(高音时还会皱眉):
让兵马俑满口英伦腔:
蒙娜丽莎张口说话:
梅梅自带Bgm说古装台词(甚至还有挑眉的小动作):
狼叔的侧颜照也难不倒它:
叹息声的细节也能处理得很好:
真人肖像的效果也很自然(甚至说话时眼睛还会顺势看向其他方向):
Loopy如何“告别割裂感”?看完这些毫无违和感DEMO视频,咱们来研究一下Loopy是如何生成这类视频的:
总的来说,Loopy是一个端到端的音频驱动视频生成模型。
它的框架可以由四部分构成,分别是:
ReferenceNet:一个额外的网络模块,它复制了原始SD U-Net的结构,以参考图像的潜在表示作为输入,来提取参考图像的特征。
DenoisingNet:一个去噪的U-Net,负责从噪声输入生成最终的视频帧。
在DenoisingNet的空间注意力层中,ReferenceNet提取的参考图像特征会与DenoisingNet的特征在token维度上进行拼接。
这样做是为了让DenoisingNet能够选择性地吸收ReferenceNet中与当前特征相关的图像信息,从而在生成过程中保持图像的视觉一致性。
简单来说,通过结合这两个网络的特征,DenoisingNet能够更好地利用参考图像的细节,提升生成结果的质量和连贯性。
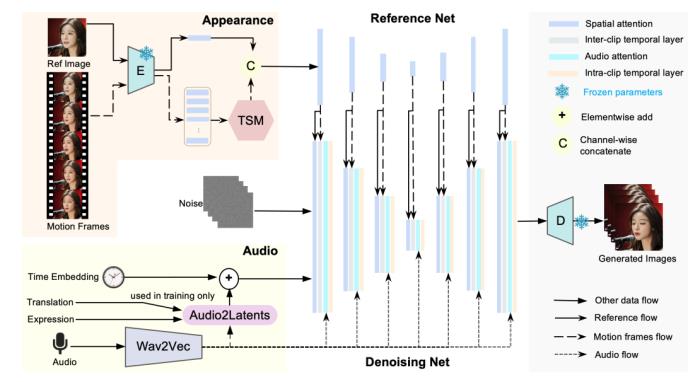
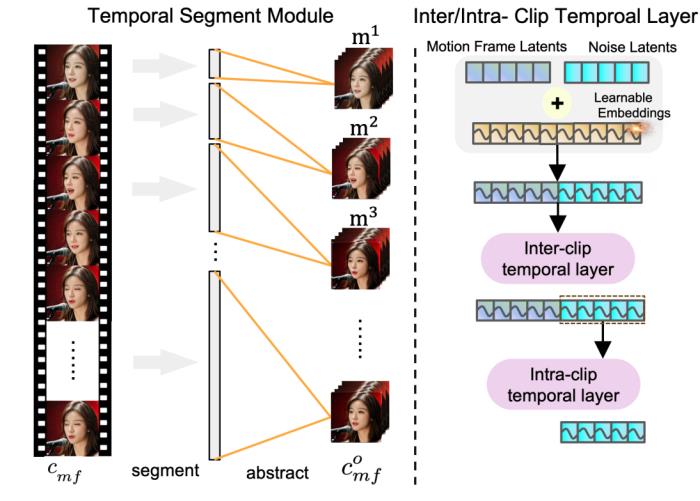
Apperance:Loopy的外观模块,主要接收参考图像和运动帧图像,然后将它们压缩成特殊的数字编码(潜在向量)。
运动帧的潜在向量经过“时间序列模块”处理,与参考图像的潜在向量拼在一起。这样就融合了参考信息和动作信息。
然后将拼接后的潜在向量输入ReferenceNet模块中,生成一张特征图,标注着重要的视觉信息,方便供后续去噪模块使用。
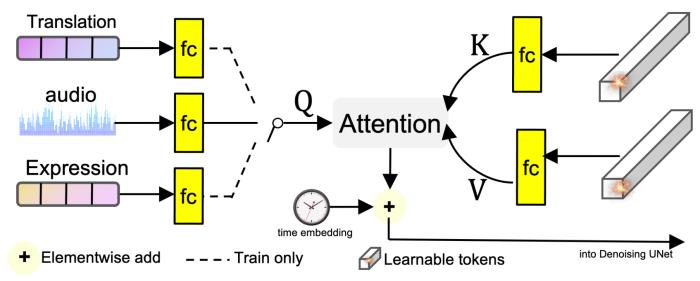
Audio:Loopy的音频模块。模型先是使用Wav2Vec网络提取音频特征,并将每层的特征连接起来,形成多尺度音频特征。
然后对于每一帧视频,将前两帧和后两帧的音频特征连接,形成一个包含5帧音频特征的序列,作为当前帧的音频信息。
最后在每个残差块中,使用“交叉注意力”机制,将音频特征与视觉特征结合,计算出一个关注的音频特征,并将其与视觉特征相加,生成新的特征。
值得一提的是,模型中也涉及到了一个Audio2Latent模块,这个模块可以将音频信息映射到共享的运动潜在空间,进一步帮助模型理解音频与视频中人物动作之间的关系。
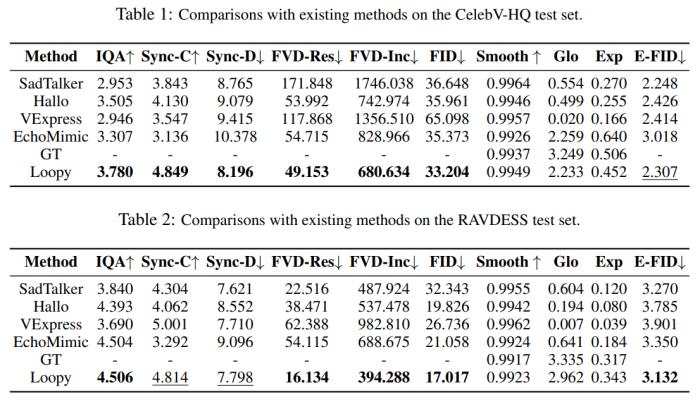
研究团队的实验结果如下:
 One more thing
One more thing值得一提的是,在Loopy之前,字节和浙大就已经联合研发出了一款类似的项目CyberHost。

但与Loopy不同的是,CyberHost是一个端到端音频驱动的人类动画模型。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。




