新火种
2024-12-13
新火种
2024-12-13 


NeurIPSSpotlight|从分类到生成:无训练的可控扩散生成
论文一作为斯坦福大学计算机博士叶皓天,指导老师为斯坦福大学 Stefano Ermon 与 James Zou 教授。北京大学博士林昊苇、斯坦福大学博士韩家琦为共同第一作者。
近年来,扩散模型(Diffusion Models)已成为生成模型领域的研究前沿,它们在图像生成、视频生成、分子设计、音频生成等众多领域展现出强大的能力。然而,生成符合特定条件(如标签、属性或能量分布)的样本,通常需要为每个目标训练专门的生成模型,这种方法不仅耗费资源,还严重制约了扩散模型作为未来基座模型实际应用潜力。
为了解决这一难题,斯坦福大学、北京大学、清华大学等机构的研究团队联合提出了一种全新的统一算法框架,名为无训练指导(Training-Free Guidance, 简称 TFG)。这一框架无缝整合现有的无训练指导方法,凭借理论创新和大规模实验验证,成为扩散模型条件生成领域的重要里程碑,目前已经被 NeurIPS 2024 接收为 Spotlight。

问题背景:扩散模型的条件生成难题
扩散模型以其渐进降噪生成样本的特性,逐渐被广泛应用于从图像到视频到音频、从分子到 3D 结构等多领域。然而,条件生成的需求(如生成特定类别的图像或满足特定能量约束的分子结构)对模型提出了更高要求。
传统条件生成方法依赖 “基于分类器的指导”(classifier-guidance)或 “无分类器指导”(classifier-free)技术。这些方法通常需要为这一类事先确定的目标属性训练一个生成 + 预测模型或是带标签的生成模型。一旦训练完成,该模型就难以被运用到同一领域的其他条件生成任务中,因而难以推广至多目标或新目标场景。与之相比,无训练指导旨在利用现成的目标预测器(如预训练分类器、能量函数、损失函数等)直接为扩散模型生成提供指导,避免了额外的训练步骤。然而,现有无训练方法存在以下显著问题:
TFG 框架的核心创新
1. 统一设计空间(unified design space)
TFG 提出了一个通用的无训练指导设计空间,将现有算法视为其特殊情况。这种统一视角不仅简化了对不同算法的比较,还通过扩展设计空间提升了性能。具体而言,TFG 基于多维超参数设计,涵盖了多种指导方法的变体,为任务适配提供了灵活性。
2. 高效超参数搜索策略(efficient searching strategy)
为了应对多目标、多样化任务场景,TFG 引入了一种高效的超参数搜索策略。在此框架下,用户无需复杂的调参过程,通过自动化策略即可快速确定最优超参数组合,适配多种下游任务。
3. 全面基准测试(comprehensive benchmark)
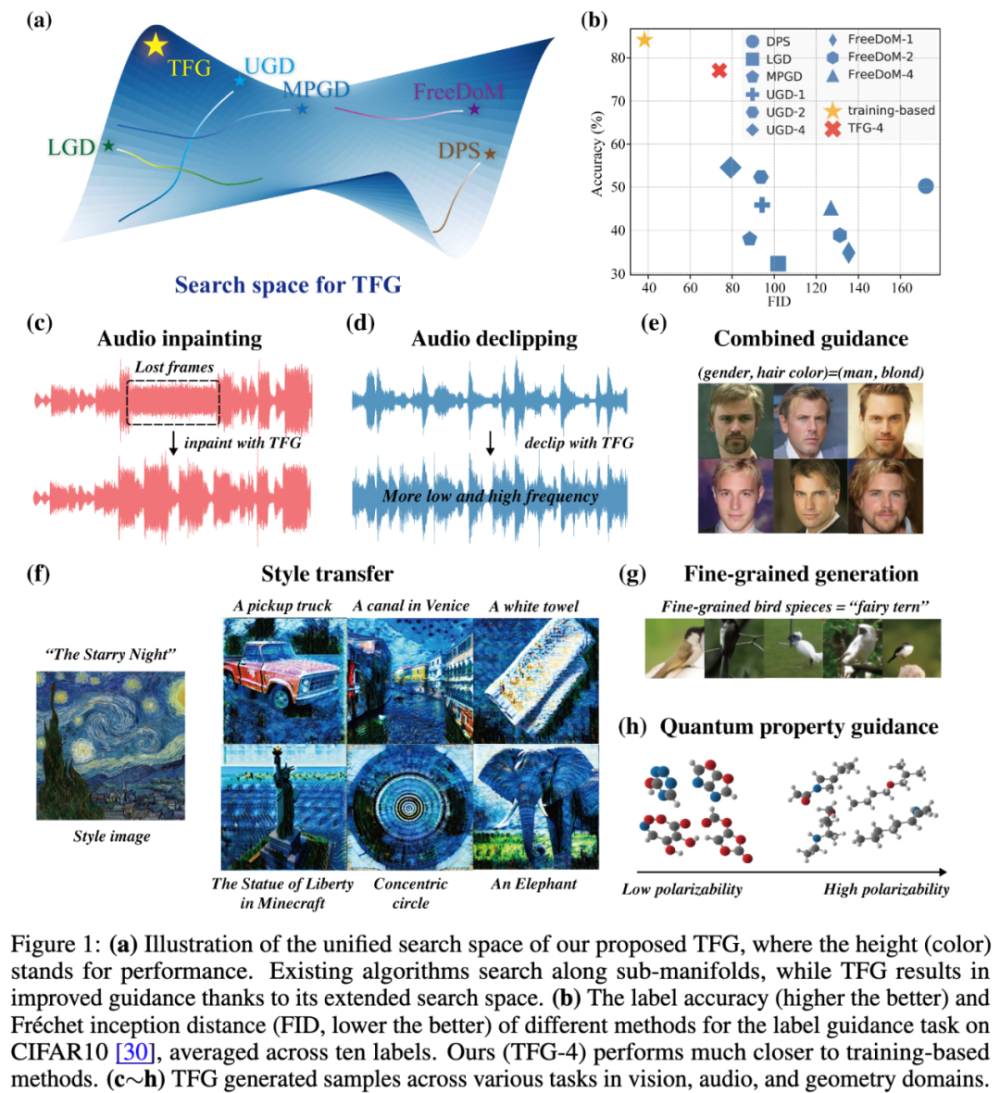
TFG 框架在 7 种扩散模型上开展了广泛的实验,包括图像、分子、音频等 16 项任务和 40 个具体目标。实验结果显示,TFG 平均性能提升 8.5%,在多个任务中均超越现有最佳方法。
方法概述:TFG 如何实现无训练指导?

实现 TFG 的核心是利用 Tweedie’s formula,通过预训练的扩散模型预测当前噪声样本对应的干净样本分布均值,再用判别器进行打分,将可微的分数进行反向传播,从而指导噪声样本的去噪过程。基于以上思路,TFG 提出了一个统一的算法框架,精细设计了四大关键机制来提升条件生成任务的表现:Mean Guidance、Variance Guidance、Implicit Dynamics 和 Recurrence。以下是各部分的详细介绍:
1. Mean Guidance(均值指导)
Mean Guidance 利用预测样本的均值梯度来引导生成过程,核心思想是对生成样本的目标属性进行直接优化。在每一步去噪过程中,模型会根据当前的预测样本 计算目标预测器(如分类器)的梯度。这些梯度被用于调整样本,使其逐渐向高目标密度区域移动。Mean guidance 的优点是简单直接,易于实现。但在目标空间的低概率区域中,梯度可能不稳定,导致生成的样本质量下降。为此,TFG 通过 recurrence(递归)和动态调整梯度强度来改进这一不足。
2. Variance Guidance(方差指导)
Variance Guidance 利用预测样本的方差信息,通过对梯度进行协方差调整,进一步优化生成方向。通过在噪声样本空间计算梯度,而非直接作用于预测样本 ,引入了更多高阶信息。根据梯度与样本协方差矩阵的相互作用,对样本生成方向进行动态调整。文章中证明了这种方法等价于对梯度进行了协方差加权,增强了生成过程中目标属性之间的协同作用。例如,正相关的目标特性会被相互加强,而负相关的特性会被弱化。
3. Implicit Dynamics(隐式动态)
隐式动态通过为目标预测器引入高斯核平滑,形成了一种渐进式的 “动态噪声引导”。在每一步生成中,对目标函数进行高斯平滑,逐步增加噪声,并通过噪声样本计算梯度。这种操作使得样本更容易跳出低概率区域,收敛至高目标密度区域。即使采用少量的采样样本,也能显著提升生成样本的多样性和精度。
4. Recurrence(递归机制)
递归机制通过重复应用前述指导步骤来逐步强化生成结果。每一步去噪的中间结果被不断 “回滚” 并重新生成,类似于一个动态优化的循环过程。每次递归的目的是修正前一轮生成的误差,同时引入更多的指导信息。在标准的标签指导任务(如 CIFAR10 和 ImageNet)中,递归次数的增加显著提升了样本准确率。例如,在 CIFAR10 数据集上,将递归次数从 1 增加到 4,准确率从 52% 提升到 77%,缩小了与基于训练的指导方法的性能差距。
本文从理论上证明,已有的一些无训练指导算法(例如 UGD,FreeDoM,MPGD,DPS,LGD)都是 TFG 的特例。TFG 构建了一个全面的超参数搜索空间,而已有的算法本质上都是在这个空间的某个子空间进行搜索。所以,TFG 将免训练指导算法设计的问题转化为:如何进行高效有效的超参数搜索?
设计空间的构建
TFG 框架的一个核心创新在于其设计空间(Design Space)的构建与超参数优化策略的提出。研究团队对这一问题进行了系统分析,并提出了一种高效的通用搜索方法,具体由以下几个超参数组成:
1. 时间相关向量:包括 ρ(Variance Guidance 强度) 和 μ(Mean Guidance 强度),分别控制梯度的影响力度及其在每个时间步的分布。
2. 时间无关标量:
这些参数的组合定义了 TFG 的设计空间 。研究表明,现有的无训练指导方法(如 DPS、FreeDoM、UGD 等)可以被视为该设计空间的特殊情况,这意味着 TFG 实现了对这些方法的统一与扩展。为了更好地分析和使用设计空间,研究团队提出了分解方法,将时间相关的向量(如 ρ 和 μ)分解为:
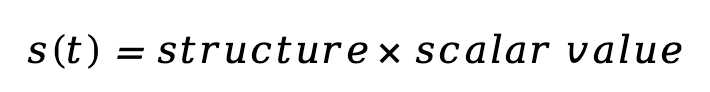
在设计空间中定义了三种结构:
1. Increase(递增结构):如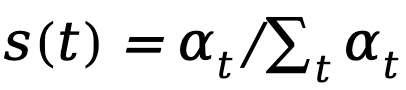 ,权重随时间步逐渐增加。2. Decrease(递减结构):如
,权重随时间步逐渐增加。2. Decrease(递减结构):如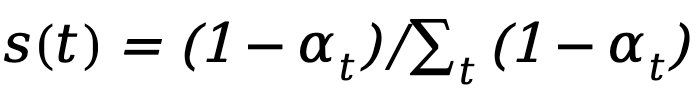 ,权重随时间步逐渐减小。3. Constant(恒定结构):权重在每个时间步均相同。
,权重随时间步逐渐减小。3. Constant(恒定结构):权重在每个时间步均相同。
通过实验对比,研究团队发现:ρ 和 μ 的递增结构在多个任务中表现最佳,生成样本的准确率和质量显著提高;这一结果极大地简化了设计空间的优化过程,为不同任务选择合适的超参数提供了明确的指导。
高效超参数搜索策略
为了在广泛的任务中实现高效优化,研究团队设计了一种通用的超参数搜索策略,包括以下核心步骤:
1. 初始值设定:从较小的初始超参数值开始(如 ρ =μ=0.25),模拟无条件生成的效果。
2. 分步搜索:
3. 选择最佳配置:将表现最优的配置加入候选集,并重复搜索,直至搜索结果稳定或达到预设的迭代次数。
该搜索方法将生成样本数量显著减少,保证在合理的计算成本内完成优化。在计算资源有限的情况下,研究团队建议将递归次数和迭代次数分别限制在 4 次以内,既能保证性能,又能控制计算复杂度。
实验亮点:TFG 的广泛适用性和卓越表现
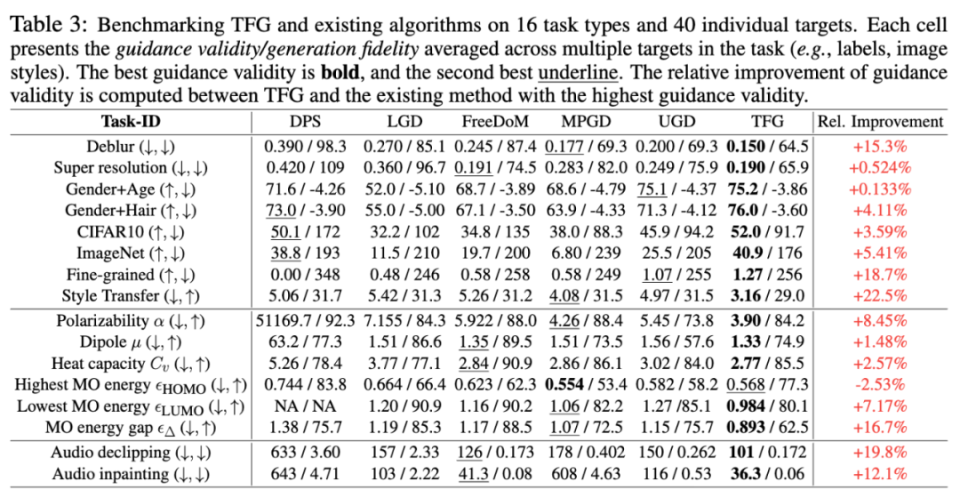
1. 精细类别生成任务
精细类别指导(Fine-Grained Label Guidance)是一种比传统标签指导更具挑战性的任务,旨在为扩散模型生成出满足更细致条件的样本。在这项研究中,TFG 首次将无训练指导方法成功应用于超越训练分布的细粒度标签生成任务。
研究团队选择了鸟类图像的细粒度标签指导任务(例如基于鸟类的物种特征生成图像)。这类任务的挑战在于:
TFG 通过其递归增强(Recurrence)机制显著提升了生成性能。在实验中,TFG 成功生成了具有 2.24% 准确率的目标样本,相比无条件生成(0% 准确率)是一个巨大飞跃。尽管绝对精度仍有提升空间,但这标志着无训练指导方法在细粒度标签生成领域的重要突破。
2. 分子生成任务
TFG 首次应用于分子生成任务的无训练指导,利用无训练指导优化分子属性(如极化率、电偶极矩等)。实验结果显示,TFG 在有效性上显著领先于现有方法,进一步拓展了扩散模型的应用边界。
3. 多目标条件生成
TFG 在多属性指导任务(如生成特定性别和发色组合的人脸)中展示了显著的均衡性和适配性。通过对生成样本进行详细分析,研究团队发现 TFG 有效缓解了由于训练数据分布不平衡导致的生成偏差问题。例如,在 “男性 + 金发” 这一稀有目标组合中,TFG 的生成准确率高达 46.7%,远高于原始数据分布中的 1%。
4. 音频生成任务
在少有探索的音频生成领域,TFG 同样表现出色。实验涵盖了音频修复(去剪裁、补全)等任务,相比其他方法,TFG 的相对性能提升超过 15%。
TFG 的未来展望:重新定义扩散模型的可能性
近年来,扩散模型(Diffusion Models)已成为生成模型领域的研究前沿,它们在图像生成、视频生成、分子设计、音频生成等众多领域展现出强大的能力。然而,生成符合特定条件(如标签、属性或能量分布)的样本,通常需要为每个目标训练专门的生成模型,这种方法不仅耗费资源,还严重制约了扩散模型作为未来基座模型实际应用潜力。
为了解决这一难题,斯坦福大学、北京大学、清华大学等机构的研究团队联合提出了一种全新的统一算法框架,名为无训练指导(Training-Free Guidance, 简称 TFG)。这一框架无缝整合现有的无训练指导方法,凭借理论创新和大规模实验验证,成为扩散模型条件生成领域的重要里程碑,目前已经被 NeurIPS 2024 接收为 Spotlight。
- 论文标题:TFG: Unified Training-Free Guidance for Diffusion Models
- 论文链接:https://arxiv.org/abs/2409.15761
- 项目地址:https://github.com/YWolfeee/Training-Free-Guidance
问题背景:扩散模型的条件生成难题
扩散模型以其渐进降噪生成样本的特性,逐渐被广泛应用于从图像到视频到音频、从分子到 3D 结构等多领域。然而,条件生成的需求(如生成特定类别的图像或满足特定能量约束的分子结构)对模型提出了更高要求。
传统条件生成方法依赖 “基于分类器的指导”(classifier-guidance)或 “无分类器指导”(classifier-free)技术。这些方法通常需要为这一类事先确定的目标属性训练一个生成 + 预测模型或是带标签的生成模型。一旦训练完成,该模型就难以被运用到同一领域的其他条件生成任务中,因而难以推广至多目标或新目标场景。与之相比,无训练指导旨在利用现成的目标预测器(如预训练分类器、能量函数、损失函数等)直接为扩散模型生成提供指导,避免了额外的训练步骤。然而,现有无训练方法存在以下显著问题:
- 缺乏系统性理论支持和设计指导;
- 即使在简单任务中表现也不稳定,容易失败;
- 难以高效选择适合的超参数。
TFG 框架的核心创新
1. 统一设计空间(unified design space)
TFG 提出了一个通用的无训练指导设计空间,将现有算法视为其特殊情况。这种统一视角不仅简化了对不同算法的比较,还通过扩展设计空间提升了性能。具体而言,TFG 基于多维超参数设计,涵盖了多种指导方法的变体,为任务适配提供了灵活性。
2. 高效超参数搜索策略(efficient searching strategy)
为了应对多目标、多样化任务场景,TFG 引入了一种高效的超参数搜索策略。在此框架下,用户无需复杂的调参过程,通过自动化策略即可快速确定最优超参数组合,适配多种下游任务。
3. 全面基准测试(comprehensive benchmark)
TFG 框架在 7 种扩散模型上开展了广泛的实验,包括图像、分子、音频等 16 项任务和 40 个具体目标。实验结果显示,TFG 平均性能提升 8.5%,在多个任务中均超越现有最佳方法。
方法概述:TFG 如何实现无训练指导?
实现 TFG 的核心是利用 Tweedie’s formula,通过预训练的扩散模型预测当前噪声样本对应的干净样本分布均值,再用判别器进行打分,将可微的分数进行反向传播,从而指导噪声样本的去噪过程。基于以上思路,TFG 提出了一个统一的算法框架,精细设计了四大关键机制来提升条件生成任务的表现:Mean Guidance、Variance Guidance、Implicit Dynamics 和 Recurrence。以下是各部分的详细介绍:
1. Mean Guidance(均值指导)
Mean Guidance 利用预测样本的均值梯度来引导生成过程,核心思想是对生成样本的目标属性进行直接优化。在每一步去噪过程中,模型会根据当前的预测样本 计算目标预测器(如分类器)的梯度。这些梯度被用于调整样本,使其逐渐向高目标密度区域移动。Mean guidance 的优点是简单直接,易于实现。但在目标空间的低概率区域中,梯度可能不稳定,导致生成的样本质量下降。为此,TFG 通过 recurrence(递归)和动态调整梯度强度来改进这一不足。
2. Variance Guidance(方差指导)
Variance Guidance 利用预测样本的方差信息,通过对梯度进行协方差调整,进一步优化生成方向。通过在噪声样本空间计算梯度,而非直接作用于预测样本 ,引入了更多高阶信息。根据梯度与样本协方差矩阵的相互作用,对样本生成方向进行动态调整。文章中证明了这种方法等价于对梯度进行了协方差加权,增强了生成过程中目标属性之间的协同作用。例如,正相关的目标特性会被相互加强,而负相关的特性会被弱化。
3. Implicit Dynamics(隐式动态)
隐式动态通过为目标预测器引入高斯核平滑,形成了一种渐进式的 “动态噪声引导”。在每一步生成中,对目标函数进行高斯平滑,逐步增加噪声,并通过噪声样本计算梯度。这种操作使得样本更容易跳出低概率区域,收敛至高目标密度区域。即使采用少量的采样样本,也能显著提升生成样本的多样性和精度。
4. Recurrence(递归机制)
递归机制通过重复应用前述指导步骤来逐步强化生成结果。每一步去噪的中间结果被不断 “回滚” 并重新生成,类似于一个动态优化的循环过程。每次递归的目的是修正前一轮生成的误差,同时引入更多的指导信息。在标准的标签指导任务(如 CIFAR10 和 ImageNet)中,递归次数的增加显著提升了样本准确率。例如,在 CIFAR10 数据集上,将递归次数从 1 增加到 4,准确率从 52% 提升到 77%,缩小了与基于训练的指导方法的性能差距。
本文从理论上证明,已有的一些无训练指导算法(例如 UGD,FreeDoM,MPGD,DPS,LGD)都是 TFG 的特例。TFG 构建了一个全面的超参数搜索空间,而已有的算法本质上都是在这个空间的某个子空间进行搜索。所以,TFG 将免训练指导算法设计的问题转化为:如何进行高效有效的超参数搜索?
设计空间的构建
TFG 框架的一个核心创新在于其设计空间(Design Space)的构建与超参数优化策略的提出。研究团队对这一问题进行了系统分析,并提出了一种高效的通用搜索方法,具体由以下几个超参数组成:
1. 时间相关向量:包括 ρ(Variance Guidance 强度) 和 μ(Mean Guidance 强度),分别控制梯度的影响力度及其在每个时间步的分布。
2. 时间无关标量:
:递归次数,决定了每个时间步的重复优化程度。
:梯度计算迭代次数,用于控制 Mean Guidance 的渐进式优化。
:用于 Implicit Dynamics 的高斯平滑参数。
这些参数的组合定义了 TFG 的设计空间 。研究表明,现有的无训练指导方法(如 DPS、FreeDoM、UGD 等)可以被视为该设计空间的特殊情况,这意味着 TFG 实现了对这些方法的统一与扩展。为了更好地分析和使用设计空间,研究团队提出了分解方法,将时间相关的向量(如 ρ 和 μ)分解为:
在设计空间中定义了三种结构:
1. Increase(递增结构):如
通过实验对比,研究团队发现:ρ 和 μ 的递增结构在多个任务中表现最佳,生成样本的准确率和质量显著提高;这一结果极大地简化了设计空间的优化过程,为不同任务选择合适的超参数提供了明确的指导。
高效超参数搜索策略
为了在广泛的任务中实现高效优化,研究团队设计了一种通用的超参数搜索策略,包括以下核心步骤:
1. 初始值设定:从较小的初始超参数值开始(如 ρ =μ=0.25),模拟无条件生成的效果。
2. 分步搜索:
- 在每次迭代中,分别对进行倍增(如从 0.25 增加到 0.5),生成多个新配置。
- 使用小规模的生成样本测试新配置,评估其表现(例如 FID 和准确率)。
3. 选择最佳配置:将表现最优的配置加入候选集,并重复搜索,直至搜索结果稳定或达到预设的迭代次数。
该搜索方法将生成样本数量显著减少,保证在合理的计算成本内完成优化。在计算资源有限的情况下,研究团队建议将递归次数和迭代次数分别限制在 4 次以内,既能保证性能,又能控制计算复杂度。
实验亮点:TFG 的广泛适用性和卓越表现
1. 精细类别生成任务
精细类别指导(Fine-Grained Label Guidance)是一种比传统标签指导更具挑战性的任务,旨在为扩散模型生成出满足更细致条件的样本。在这项研究中,TFG 首次将无训练指导方法成功应用于超越训练分布的细粒度标签生成任务。
研究团队选择了鸟类图像的细粒度标签指导任务(例如基于鸟类的物种特征生成图像)。这类任务的挑战在于:
- 数据分布超出训练模型的常见分布范围,导致生成的样本极易偏离目标特性。
- 即使对于成熟的文本 - 图像生成模型(如 DALL-E),该问题也难以解决。
TFG 通过其递归增强(Recurrence)机制显著提升了生成性能。在实验中,TFG 成功生成了具有 2.24% 准确率的目标样本,相比无条件生成(0% 准确率)是一个巨大飞跃。尽管绝对精度仍有提升空间,但这标志着无训练指导方法在细粒度标签生成领域的重要突破。
2. 分子生成任务
TFG 首次应用于分子生成任务的无训练指导,利用无训练指导优化分子属性(如极化率、电偶极矩等)。实验结果显示,TFG 在有效性上显著领先于现有方法,进一步拓展了扩散模型的应用边界。
3. 多目标条件生成
TFG 在多属性指导任务(如生成特定性别和发色组合的人脸)中展示了显著的均衡性和适配性。通过对生成样本进行详细分析,研究团队发现 TFG 有效缓解了由于训练数据分布不平衡导致的生成偏差问题。例如,在 “男性 + 金发” 这一稀有目标组合中,TFG 的生成准确率高达 46.7%,远高于原始数据分布中的 1%。
4. 音频生成任务
在少有探索的音频生成领域,TFG 同样表现出色。实验涵盖了音频修复(去剪裁、补全)等任务,相比其他方法,TFG 的相对性能提升超过 15%。
TFG 的未来展望:重新定义扩散模型的可能性
TFG 不仅为无训练指导提供了统一理论基础和实用工具,也为扩散模型在不同领域的拓展应用提供了新的思路。其核心优势包括:
- 高效适应性:无需为每个任务额外训练模型,显著降低了条件生成的门槛;
- 广泛兼容性:框架适用于从图像到音频、从分子到多目标生成的多种任务;
- 性能优越性:通过理论与实验的结合,显著提升了生成的准确性和质量。
未来,TFG 有望在药物设计、精准医学、复杂音频生成、高级图像编辑等领域进一步发挥作用。研究团队还计划优化框架,进一步缩小与基于训练方法的性能差距。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。