

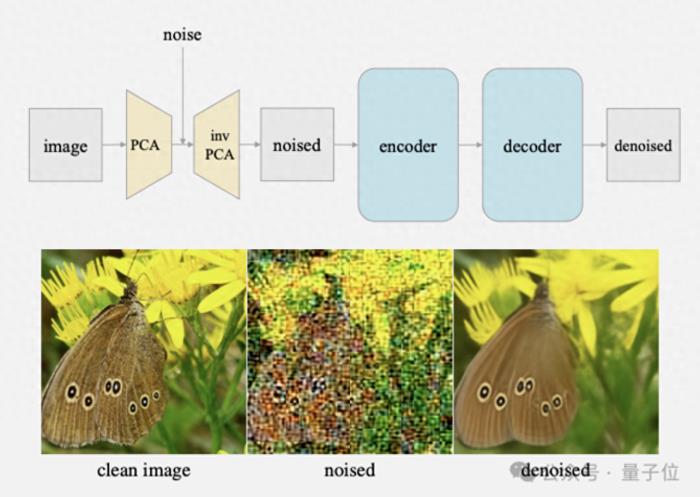
何恺明谢赛宁解剖扩散模型,新作刚刚出炉
CV大神何恺明,也来搞扩散模型(Diffusion Model)了!大神最新论文刚刚挂上arXiv,还是热乎的:解构扩散模型,提出一个高度简化的新架构l-DAE(小写的L)。
CV大神何恺明,也来搞扩散模型(Diffusion Model)了!大神最新论文刚刚挂上arXiv,还是热乎的:解构扩散模型,提出一个高度简化的新架构l-DAE(小写的L)。
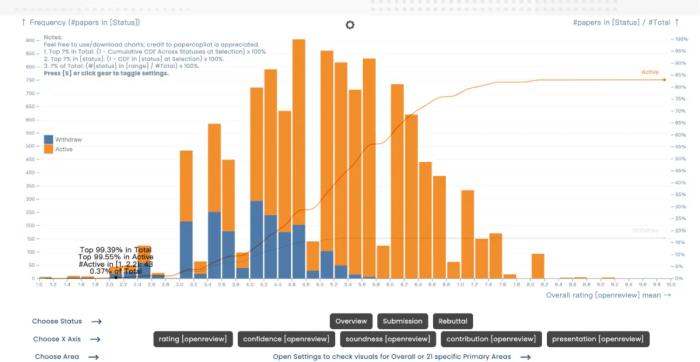
四个 10 分!罕见的一幕出现了。您正在收看的,不是中国梦之队的跳水比赛,而是 ICLR 2025 的评审现场。虽说满分论文不是前无古人,后无来者,但放在平均分才 4.76 的 ICLR,怎么不算是相当炸裂的存在呢。

比斯坦福DPO(直接偏好优化)更简单的RLHF平替来了,来自陈丹琦团队。该方式在多项测试中性能都远超DPO,还能让8B模型战胜Claude 3的超大杯Opus。而且与DPO相比,训练时间和GPU消耗也都大幅减少。这种方法叫做SimPO,Sim是Simple的简写,意在突出其简便性。

造大模型的成本,又被打下来了!这次是数据量狂砍95%的那种。陈丹琦团队最新提出大模型降本大法——数据选择算法LESS, 只筛选出与任务最相关5%数据来进行指令微调,效果比用整个数据集还要好。指令微调正是让基础模型成为类ChatGPT助手模型的关键一步。

现实世界版的 Genie-2?最近,世界模型(World Models)似乎成为了 AI 领域最热门的研究方向。继World Labs(李飞飞)、谷歌 DeepMind 接连发布自己的世界模型研究之后,

斯坦福吴佳俊团队与MIT携手打造的最新研究成果,让我们离实时生成开放世界游戏又近了一大步。从单一图像出发,在用户的实时交互下生成无限延展的3D场景:只需上传一张图片,就能踏入一个由AI创造的虚拟世界。

“绝不是简单的抠图。”ControlNet作者最新推出的一项研究受到了一波高度关注——给一句prompt,用Stable Diffusion可以直接生成单个或多个透明图层(PNG)!

米哈游蔡浩宇的AI游戏,实机演示片段曝光!没想到视频那头的NPC「小美」一句话,直接把人类「小帅」给撩到脸红了。看着眼含深情的「小美」语气温柔地说着土味情话,试问谁能不心动。这个「小美」叫做Stella,正是上个月曝光的AI游戏《Whispers From The Star》里的主角。

编辑:桃子 好困【新智元导读】马毅教授团队最新研究表明,微调多模态大语言模型(MLLM)将会导致灾难性遗忘。模型灾难性遗忘,成为当前一个关键热门话题,甚至连GPT-4也无法避免。近日,来自UC伯克利、NYU等机构研究人员发现,微调后的多模态大模型,会产生灾难性遗忘。论文地址:https://arxi
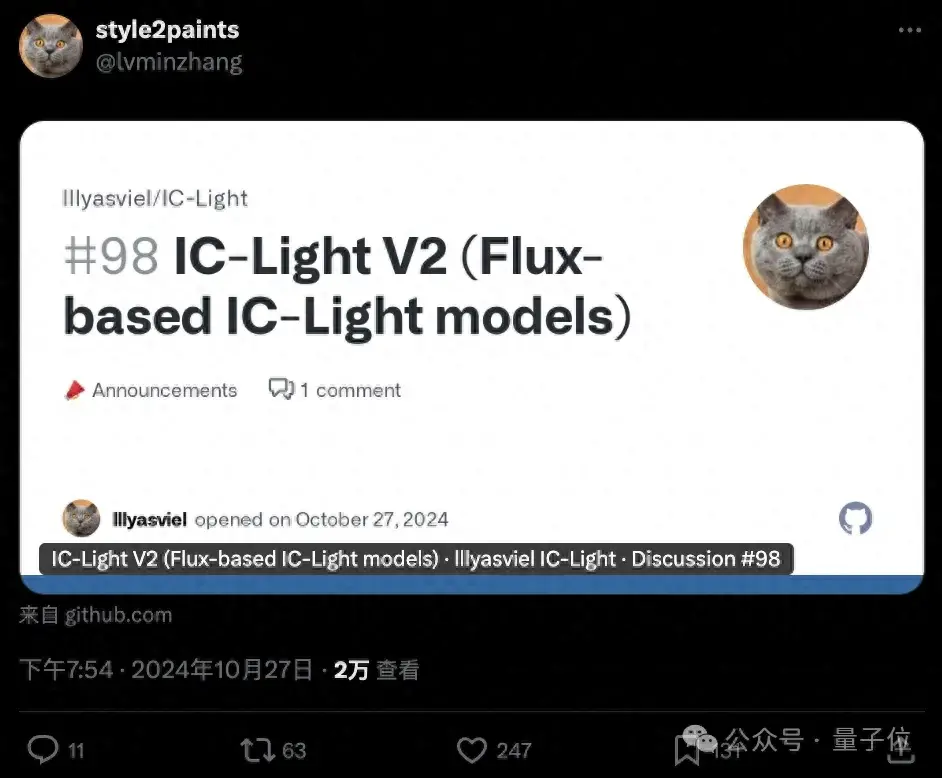
ControlNet作者“敏神”(张吕敏),刚刚上新了一个新项目——名叫IC-Light V2,可以说是把AI打光这事儿玩得溜溜的。IC-Light是此前张吕敏开发的图像处理工具,可以通过AI技术精确控制图像中的光照效果。










