

 机器之心
2024-12-05
机器之心
2024-12-05 


被忽略的起点?Karpathy揭秘最初的注意力论文被Transformer光芒掩盖的故事
机器之心报道
编辑:Panda
几个小时前,著名 AI 研究者、OpenAI 创始成员之一 Andrej Karpathy 发布了一篇备受关注的长推文,其中分享了注意力机制背后一些或许少有人知的故事。
其中最值得注意的一个故事是真正首次提出注意力机制的论文其实是 Dzmitry Bahdanau、Kyunghyun Cho 和 Yoshua Bengio 的《Neural Machine Translation by Jointly Learning to Align and Translate》,这比《Attention is All you Need》还早 3 年,但很显然,这篇论文并没有收获后者那般的关注。

Karpathy 长推文的不完整截图
实际上,这个故事来自 Dzmitry Bahdanau 发给 Karpathy 的一封邮件。Bahdanau 是 ServiceNow Research 的研究科学家和研究负责人以及麦吉尔大学兼职教授。
他在发给 Karpathy 的这封邮件中分享了自己发现注意力机制的旅程以及 Attention 这个术语的由来——其实来自 Yoshua Bengio。此外,他也提到了 Alex Graves 的 NMT 论文和 Jason Weston 的记忆网络(Memory Networks)论文各自独立发现类似机制的故事。
Karpathy 推文发布后反响热烈,短时间内就已有超过 20 万阅读量,很多读者都被这个注意力背后的故事吸引。

有读者在看过这个故事后发出感叹:2013-2017 年间的深度学习宇宙中有很多隐藏的英雄。

也有人分享自己对注意力机制的看法。

Hyperbolic Labs 创始人和 CTO Yuchen Jin 更是打趣说《Attention Is All You Need》的另一项重要贡献是将后面的 AI 论文标题带歪了:「吸引注意力的标题才是 All You Need」。

注意力机制的背后故事
下面我们就来看看 Karpathy 的推文究竟说了什么:
「attention」算子——也就是提出了 Transformer 的《Attention is All you Need》中的那个注意力,背后的(真实)开发和灵感故事。来自大约 2 年前与作者 @DBahdanau 的个人电子邮件通信,在此发布(经许可)。此前几天,网上流传着一些关于其开发过程的假新闻。
Attention 是一种出色的(数据依赖型)加权平均运算。它是一种形式的全局池化、归约、通信。它是一种从多个节点(token、图块等)聚合相关信息的方法。它富有表现力、功能强大、具有足够的并行性,并且可以高效优化。甚至多层感知器(MLP)实际上也可以大致重写为数据独立型权重上的 Attention(第一层权重是查询,第二层权重是值,键就是输入,softmax 变为元素级,删除了规范化)。简单来说,注意力非常棒,是神经网络架构设计中的重大突破。
《Attention is All You Need》获得的…… 呃…… 注意力差不多是 3 年前真正提出 Attention 的论文的 100 倍,即 Dzmitry Bahdanau、Kyunghyun Cho 和 Yoshua Bengio 的论文《Neural Machine Translation by Jointly Learning to Align and Translate》。在我看来,这一直有点出人意料。顾名思义,《Attention is All You Need》的核心贡献是提出:Transformer 神经网络就是删除注意力之外的一切,然后基本上就是将其堆叠在带有 MLP(根据上述内容,这也可以大致被视为注意力)的 ResNet 中。但我确实认为这篇 Transformer 论文有自己独特的价值,因为它一次性添加了其它许多令人惊叹的想法,包括位置编码、缩放式注意力、多头注意力、各向同性的简单设计等。在我看来,直到今天(大约 7 年过去了),Transformer 基本上还保持着 2017 年的形式,只有相对较少的微小修改,也许除了使用更好的位置编码方案(RoPE 等)。
总之,我先把完整邮件贴在下面,其中也暗示了这个运算一开始被称为 Attention 的原因 —— 它源自对源句子中词的关注(attending)并同时以顺序方式输出翻译结果的词,并且之后 Yoshua Bengio 在 RNNSearch 中将其引入成了一个术语(感谢上帝?:D)。同样有趣的是,该设计的灵感来自人类的认知过程/策略,即按顺序来回关注一些数据。最后,从发展进步的本质来看,这个故事相当有趣——类似的想法和表述「早就已经在空气中回荡」,特别要提到当时 Alex Graves(NMT)和 Jason Weston(记忆网络)的工作。
谢谢你的故事 @DBahdanau !
之后,Karpathy 还做了一些补充:ChatGPT 以及绝大多数现代 AI 模型都是巨型 Transformer。「所以 LLM 的核心神奇之处来自于反复应用注意力,一遍又一遍地关注输入的 token,以预测下一个 token 是什么。」

Dzmitry Bahdanau 的原始邮件内容
Karpathy 也一并分享了 Dzmitry Bahdanau 的原始邮件内容:

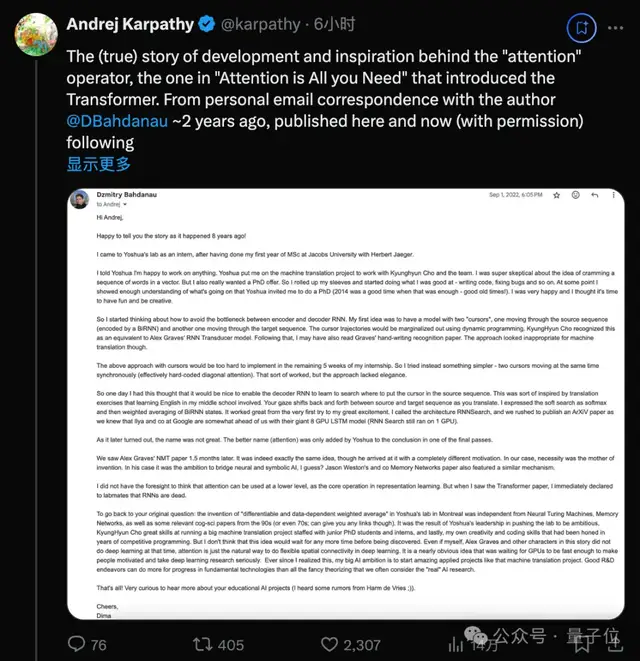
嗨,Andrej,
很高兴告诉你 8 年前发生的故事!
我在雅各布大学 Herbert Jaeger 的指导下完成硕士课程的第一年后,作为实习生来到了 Yoshua 的实验室。
我告诉 Yoshua 我很乐意做任何事情。Yoshua 让我参与机器翻译项目,与 Kyunghyun Cho 和团队一起工作。我当时非常怀疑将词序列塞入向量的想法。但我也非常想获得博士学位。所以我撸起袖子,开始做我擅长的事情——编写代码、修复错误等等。在某个时候,我表现得很了解我做的东西了,Yoshua 邀请我攻读博士学位(2014 年是一个很好的时机,表现得很了解就已经足够了——美好的旧时光!)。我非常高兴,我认为可以开始享受乐趣并发挥创造力了。
所以我开始思考如何避免编码器和解码器 RNN 之间的瓶颈。我的第一个想法是构建一个带有两个「光标」的模型,一个在源序列中移动(由一个 BiRNN 编码),另一个在目标序列中移动。使用动态规划(dynamic programming)可以将光标轨迹边缘化。KyungHyun Cho 认为这相当于 Alex Graves 的 RNN Transducer 模型。之后,我可能还读了 Graves 的手写识别论文。不过,这种方法看起来不适合机器翻译。
在我实习的剩余 5 周内,上述使用光标的方法很难实现。所以我尝试了一种更简单的方法——两个光标同时同步移动(实际上是硬编码的对角注意力)。这种方法有点效果,但方法不够优雅。
所以有一天,我想到如果能让解码器 RNN 学会在源序列中搜索放置光标的位置就好了。这多少受到我中学时学习英语时的翻译练习的启发。翻译时,你的目光会在源序列和目标序列之间来回移动。我将这种软性搜索表示为 softmax,然后对 BiRNN 状态进行加权平均。它的效果很好,从第一次尝试,到后来振奋人心。我将这个架构称为 RNNSearch,我们急于发表一篇 arXiv 论文,因为我们知道谷歌的 Ilya 和同事领先于我们,他们有巨大的 8 GPU LSTM 模型(而 RNN Search 仍在 1 GPU 上运行)。
后来发现,这个名字并不好。直到最后几次过论文时,Yoshua 才将更好的名字(attention)添加到论文结论中。
一个半月后,我们看到了 Alex Graves 的 NMT 论文。这确实是完全相同的想法,尽管他提出它的动机完全不同。在我们的情况下,是因为需要而产生了这个发明。在他的情况下,我想应该是将神经和符号 AI 连接起来的雄心吧?Jason Weston 及其同事的记忆网络论文也采用了类似的机制。
我没有远见地想到注意力可以在较低的层级使用,以作为表征学习的核心运算。但是当我看到 Transformer 论文时,我立即向实验室同事断言 RNN 已死。
回到你最初的问题:在蒙特利尔 Yoshua 的实验室发明的「可微分和数据依赖加权平均」独立于神经图灵机、记忆网络以及 90 年代(甚至 70 年代)的一些相关认知科学论文。这是 Yoshua 领导推动实验室进行雄心勃勃的研究的结果,KyungHyun Cho 在运行一个大型机器翻译项目方面拥有高超的技能,该项目由初级博士生和实习生组成;最后,我自己的创造力和编码技能在多年的竞争性编程中得到了磨练。但我认为这个想法很快就会被发现。就算我、Alex Graves 和这个故事中的其他角色当时没有研究深度学习也是如此,注意力就是深度学习中实现灵活空间连接的自然方式。等待 GPU 足够快,让人们有动力认真对待深度学习研究,这是一个显而易见的想法。自从我意识到这一点以来,我在 AI 领域的抱负就是启动像机器翻译项目这样的出色的应用项目。相比于那些研究所谓的「真正」AI 的花哨理论,良好的研发工作可以为基础技术的进步做出更大贡献。
就这些!我非常想更多了解关于您的教育 AI 项目的信息(我从 Harm de Vries 那里听到了一些传言;))。
祝好,
Dima
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










