新火种
2024-11-28
新火种
2024-11-28 


跨模态大升级!少量数据高效微调,LLM教会CLIP玩转复杂文本
在当今多模态领域,CLIP 模型凭借其卓越的视觉与文本对齐能力,推动了视觉基础模型的发展。CLIP 通过对大规模图文对的对比学习,将视觉与语言信号嵌入到同一特征空间中,受到了广泛应用。
然而,CLIP 的文本处理能力被广为诟病,难以充分理解长文本和复杂的知识表达。随着大语言模型的发展,新的可能性逐渐显现:LLM 可以引入更丰富的开放时间知识、更强的文本理解力,极大提升 CLIP 的多模态表示学习能力。
在此背景下,来自同济大学和微软的研究团队提出了 LLM2CLIP。这一创新方法将 LLM 作为 CLIP 的强力 「私教」,以少量数据的高效微调为 CLIP 注入开放世界知识,让它能真正构建一个的跨模态空间。在零样本检索任务上,CLIP 也达成了前所未有的性能提升。

论文标题:LLM2CLIP: POWERFUL LANGUAGE MODEL UNLOCKS RICHER VISUAL REPRESENTATION论文链接:https://arxiv.org/pdf/2411.04997代码仓库:https://github.com/microsoft/LLM2CLIP模型下载:https://huggingface.co/collections/microsoft/llm2clip-672323a266173cfa40b32d4c在实际应用中,LLM2CLIP 的效果得到了广泛认可,迅速吸引了社区的关注和支持。HuggingFace 一周内的下载量就破了两万,GitHub 也突破了 200+ stars!
值得注意的是,LLM2CLIP可以让完全用英文训练的 CLIP 模型,在中文检索任务中超越中文 CLIP。此外,LLM2CLIP 也能够在多模态大模型(如 LLaVA)的训练中显著提升复杂视觉推理的表现。代码与模型均已公开,欢迎访问 https://aka.ms/llm2clip 了解详情和试用。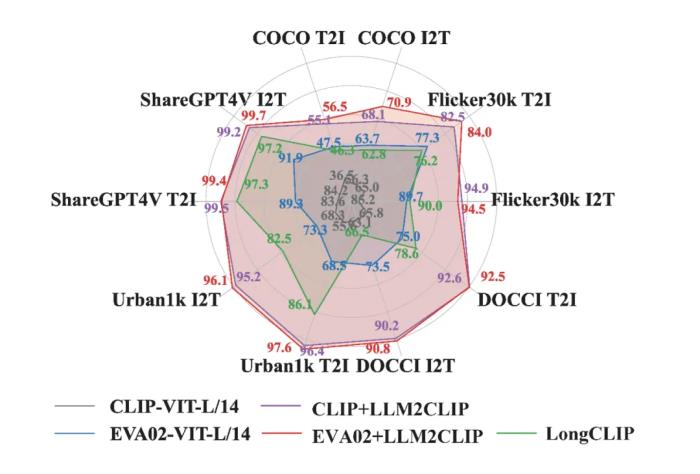
LLM2CLIP 目前已被 NeurIPS 2024 Workshop: Self-Supervised Learning - Theory and Practice 接收。研究背景CLIP 的横空出世标志着视觉与语言领域的一次革命。不同于传统的视觉模型(如 ImageNet 预训练的 ResNet 和 ViT)依赖简单的分类标签,CLIP 基于图文对的对比学习,通过自然语言的描述获得了更丰富的视觉特征,更加符合人类对于视觉信号的定义。这种监督信号不仅仅是一个标签,而是一个富有层次的信息集合,从而让 CLIP 拥有更加细腻的视觉理解能力,适应零样本分类、检测、分割等多种任务。可以说,CLIP 的成功奠基于自然语言的监督,是一种新时代的 「ImageNet 预训练」。虽然 CLIP 在视觉表示学习中取得了成功,但其在处理长文本和复杂描述上存在明显限制。而大语言模型(LLM)例如 GPT-4 和 Llama,通过预训练掌握了丰富的开放世界知识,拥有更强的文本理解和生成能力。将 LLM 的这些能力引入到 CLIP 中,可以大大拓宽 CLIP 的性能上限,增强其处理长文本、复杂知识的能力。借助 LLM 的知识扩展,CLIP 在图文对齐任务中的学习效率也得以提升。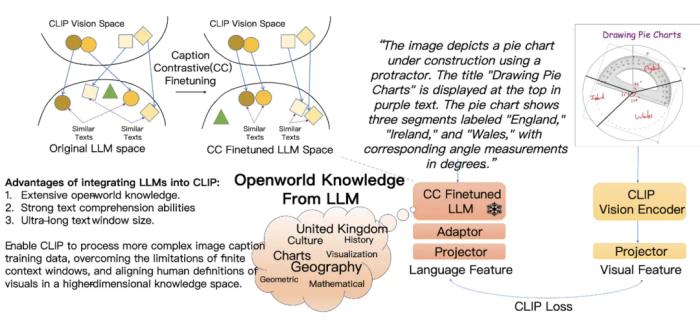
原始的 LLM 无法给 CLIP 带来有意义的监督事实上,将 LLM 与 CLIP 结合看似简单粗暴,实际并非易事。直接将 LLM 集成到 CLIP 中会引发「灾难」,CLIP无法产生有效的表示。这是由于 LLM 的文本理解能力隐藏在内部,它的输出特征空间并不具备很好的特征可分性。于是,该团队设计了一个图像 caption 到 caption 的检索实验,使用 COCO 数据集上同一张图像的两个不同 caption 互相作为正样本进行文本检索。他们发现原生的 llama3 8B 甚至无法找到十分匹配的 caption,例如 plane 和 bat 的距离更近,但是离 airplane 的距离更远,这有点离谱了,因此它只取得了 18.4% 的召回率。显然,这样的输出空间无法给 CLIP 的 vision encoder 一个有意义的监督,LLM 无法帮助 CLIP 的进行有意义的特征学习。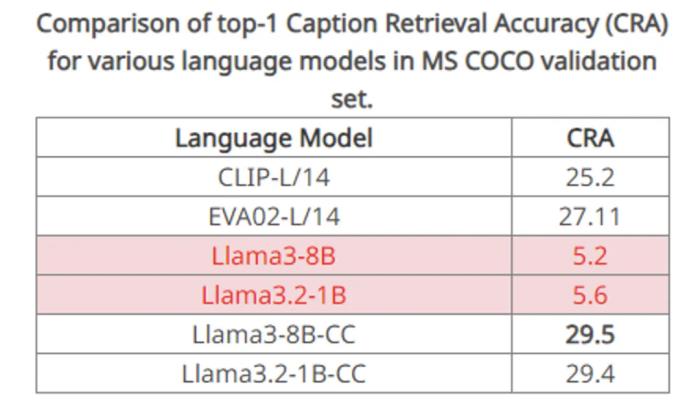
图像描述对比微调是融合 LLM 与CLIP 的秘诀从上述观察,研究团队意识到必须对提升 LLM 输出空间对图像表述的可分性,才有可能取得突破。为了让 LLM 能够让相似的 caption 接近,让不同图像的 caption 远离,他们设计了一个新的图像描述对比微调 ——Caption-Contrastive(CC)finetuning。该团队对训练集中每张图像都标注了两个以上 caption,再采用同一个图像的 caption 作为正样本,不同图像的 caption 作为负样本来进行对比学习,来提升 LLM 对于不同画面的描述的区分度。
实验证明,这个设计可以轻易的提升上述 caption2caption 检索的准确率,从上述 cases 也可以看出召回的例子开始变得有意义。高效训练范式LLM2CLIP让 SOTA 更加 SOTALLM2CLIP 这一高效的训练范式具体是怎么生效的呢?首先,要先使用少量数据对 LLM 进行微调,增强文本特征更具区分力,进而作为 CLIP 视觉编码器的强力 「教师」。这种设计让 LLM 中的文本理解力被有效提取,CLIP 在各种跨模态任务中获得显著性能提升。实验结果表明,LLM2CLIP 甚至能在不增加大规模训练数据的情况下,将当前 SOTA 的 CLIP 性能提升超过 16%。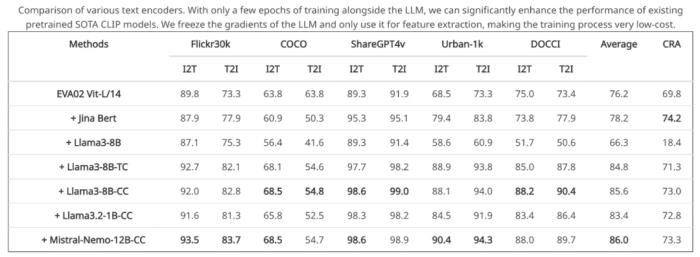
英文训练,中文超越,CLIP 的语言能力再拓展一个令人惊喜的发现是,LLM2CLIP 的开放世界知识不仅提升了 CLIP 在英文任务中的表现,还能赋予其多语言理解能力。尽管 LLM2CLIP 仅在英文数据上进行了训练,但在中文图文检索任务上却超越了中文 CLIP 模型。这一突破让 CLIP 不仅在英文数据上达到领先水平,同时在跨语言任务中也展现了前所未有的优势。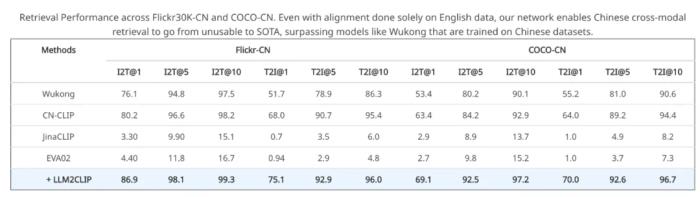
提升多模态大模型的复杂视觉推理性能LLM2CLIP 的优势还不止于此。当该团队将 LLM2CLIP 应用于多模态大模型 LLaVA 的训练时,显著提升了 LLaVA 在复杂视觉推理任务中的表现。LLaVA 的视觉编码器通过 LLM2CLIP 微调后的 CLIP 增强了对细节和语义的理解能力,使其在视觉问答、场景描述等任务中取得了全面的性能提升。总之,该团队希望通过 LLM2CLIP 技术,推动大模型的能力反哺多模态社区,同时为基础模型的预训练方法带来新的突破。LLM2CLIP 的目标是让现有的预训练基础模型更加强大,为多模态研究提供更高效的工具。除了完整的训练代码,他们也逐步发布了经过 LLM2CLIP 微调的主流跨模态基础模型,期待这些模型能被应用到更多有价值的场景中,挖掘出更丰富的能力。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。