新火种
2024-10-27
新火种
2024-10-27 


事件相机+AI视频生成,港大CUBE框架入选ICIP,无需训练实现可控视频生成
在这个信息爆炸的时代,如何让AI生成的视频更具创意,又符合特定需求?
来自香港大学的最新研究《基于事件、无需训练的可控视频生成框架 CUBE》带来一个全新的解决方案。
这一框架利用了事件相机捕捉动态边缘的能力,将AI生成的视频带入了一个新的维度,精准又高效。论文原标题是“Controllable Unsupervised Event-based Video Generation”,
发表于图像处理盛会ICIP并被选为Oral(口头报告),并受邀在WACV workshop演讲。
 什么是事件相机?
什么是事件相机?在深入了解CUBE框架之前,先来认识一下事件相机。
不同于传统相机的定时捕捉,事件相机模仿生物的视觉系统,只捕捉像素点亮度变化的“事件”,就像是只记录画面的精华部分。
这样不仅可以有效减少冗余数据,还可以显著降低耗能。
尤其是在高速动态或光线变化大的场景下,事件相机比传统相机更有优势。而这些独特的“事件数据”正是CUBE框架的核心。

△左:普通相机拍的;右:事件相机拍的
简单说,事件相机和普通相机不同,捕捉的是物体边缘的动态细节,就像你脑中一闪而过的灵感,节省了大量带宽还能省电。
CUBE框架结合了这些“闪现”的边缘数据和文字描述,无需训练就能合成符合需求的视频!这不仅能让你生成的场景更“合胃口”,还能让视频质量、时间一致性和文本匹配度都蹭蹭上涨。
为什么要用CUBE?其他方法或是需要大量训练数据,或是生成效果欠佳。CUBE框架不仅解决了这些问题,还在多项指标上表现出色。
无论是视觉效果、文本匹配度还是帧间一致性,CUBE都表现优异。
可以这样想:CUBE就像给事件相机配上了智能“滤镜”,让生成的视频不仅生动还符合描述,比如让铁人也能在马路上跳起月球舞步!
CUBE框架是如何工作的?CUBE的全称是“Controllable, Unsupervised, Based on Events”,直译过来就是“可控的、无需训练的、基于事件的”视频生成框架。
它通过提取事件中的边缘信息,再结合用户提供的文字描述生成视频。在方法上,CUBE主要依赖扩散模型生成技术。
扩散模型通过向图像添加随机噪声并逐步还原来生成图片,但团队进一步优化了这个过程,能让它根据“事件”提供的边缘数据生成视频。
CUBE的核心方法1. 边缘提取:事件流记录了物体运动的轨迹,而CUBE的首要任务就是将这些事件转换成边缘信息。团队设计了一个边缘提取模块,把事件数据分成多个时间段,提取出关键的空间位置,从而形成精确的边缘图。这些边缘图不仅保留了运动物体的轮廓,还能让视频生成更流畅。

2. 视频生成:有了边缘数据之后,CUBE结合了文字描述生成视频。通过扩散模型的逐步还原过程,可以生成多个与描述相匹配的图像帧,并用插帧技术让视频更加平滑一致。这个过程不需要大量的训练数据,因为CUBE直接调用了预训练的扩散模型来实现高质量生成。

3. 控制性与一致性:采用了ControlVideo框架,这一框架具有优秀的可控性,通过文字描述来控制生成的视频内容,使每帧的生成都符合特定的要求。ControlVideo和CUBE的组合解决了传统方法中视频生成一致性不足的问题,让内容更生动、更贴合描述。

 CUBE的性能表现
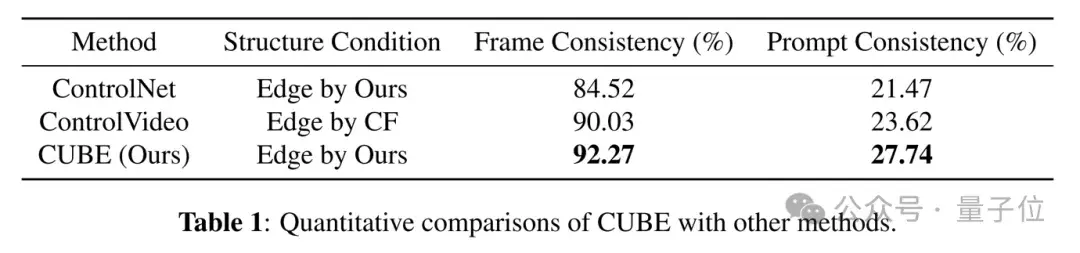
CUBE的性能表现在实验中,CUBE的表现远超现有方法。在视频质量、文本匹配度和时间一致性等多个指标上,CUBE都取得了优异的成绩。
定量实验显示,CUBE生成的帧间一致性和文本匹配度都比ControlNet、ControlVideo等方法更优。此外,团队还做了用户偏好测试,结果显示参与者普遍更喜欢CUBE生成的视频。
 未来展望
未来展望当然,CUBE还有提升的空间。未来团队希望将边缘信息和纹理信息结合,使视频更具细节和真实感,同时探索更多领域适用性,甚至将其应用在实时场景中。这一技术不仅适合电影、动画生成等领域,还可以用于自动驾驶、监控等需要快速识别动态环境的场景。
CUBE不仅是一项技术,更是一次在事件相机与AI生成视频领域的新探索。
如果你也对AI生成视频感兴趣,可进一步参考完整论文和开源代码。
论文地址:https://ieeexplore.ieee.org/abstract/document/10647468代码已开源:https://github.com/IndigoPurple/cube
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。