新火种
2024-09-22
新火种
2024-09-22 


o1核心作者分享:激励AI自我学习,比试图教会AI每一项任务更重要
“o1发布后,一个新的范式产生了”。
其中关键,OpenAI研究科学家、o1核心贡献者Hyung Won Chung,刚刚就此分享了他在MIT的一次演讲。
演讲主题为“Don’t teach. Incentivize(不要教,要激励),核心观点是:

思维链作者Jason Wei迅速赶来打call:

在演讲中,Hyung Won还分享了:
技术人员过于关注问题解决本身,但更重要的是发现重大问题;硬件进步呈指数级增长,软件和算法需要跟上;当前存在一个误区,即人们正在试图让AI学会像人类一样思考;“仅仅扩展规模” 往往在长期内更有效;……下面奉上演讲主要内容。
对待AI:授人以鱼不如授人以渔先简单介绍下Hyung Won Chung,从公布的o1背后人员名单来看,他属于推理研究的基础贡献者。

资料显示,他是MIT博士(方向为可再生能源和能源系统),去年2月加入OpenAI担任研究科学家。
加入OpenAI之前,他在Google Brain负责大语言模型的预训练、指令微调、推理、多语言、训练基础设施等。

在谷歌工作期间,曾以一作身份,发表了关于模型微调的论文。(思维链作者Jason Wei同为一作)

回到正题。在MIT的演讲中,他首先提到:
在他看来,AI领域正处于一次范式转变,即从传统的直接教授技能转向激励模型自我学习和发展通用技能。
理由也很直观,AGI所包含的技能太多了,无法一一学习。(主打以不变应万变)
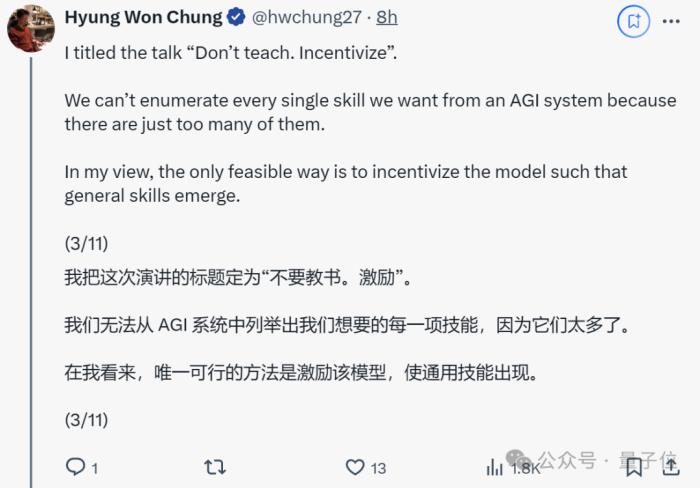
具体咋激励呢??
他以下一个token预测为例,说明了这种弱激励结构如何通过大规模多任务学习,鼓励模型学习解决数万亿个任务的通用技能,而不是单独解决每个任务。
他观察到:

对此他打了个比方,“授人以鱼不如授人以渔”,用一种基于激励的方法来解决任务。
然后AI就会自己出去钓鱼,在此过程中,AI将学习其他技能,例如耐心、学习阅读天气、了解鱼等。
其中一些技能是通用的,可以应用于其他任务。
面对这一“循循善诱”的过程,也许有人认为还不如直接教来得快。
但在Hyung Won看来:

换句话说,面对有限的时间,人类也许还要在专家 or 通才之间做选择,但对于机器来说,算力就能出奇迹。
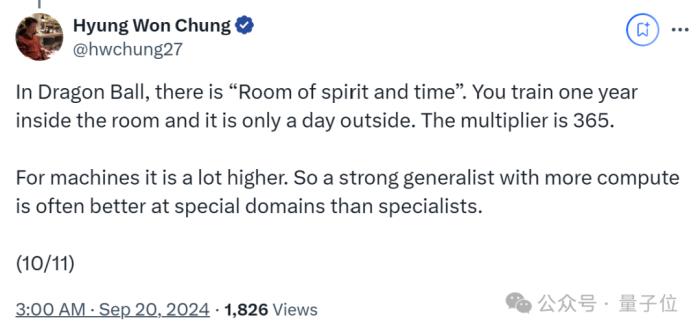
他又举例说明,《龙珠》里有一个设定:在特殊训练场所,角色能在外界感觉只是一天的时间内获得一年的修炼效果。
原因也众所周知,大型通用模型能够通过大规模的训练和学习,快速适应和掌握新的任务和领域,而不需要从头开始训练。
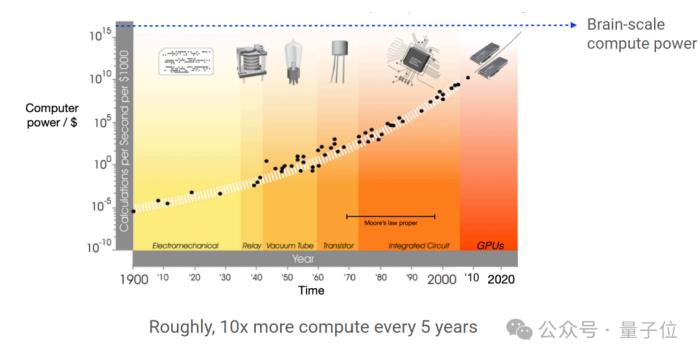
他还补充道,数据显示计算能力大约每5年提高10倍。
总结下来,Hyung Won认为核心在于:
模型的可扩展性算力对加速模型进化至关重要此外,他还认为当前存在一个误区,即人们正在试图让AI学会像人类一样思考。
但问题是,我们并不知道自己在神经元层面是如何思考的。
在他看来,一个系统或算法过于依赖人为设定的规则和结构,那么它可能难以适应新的、未预见的情况或数据。
造成的结果就是,面对更大规模或更复杂的问题时,其扩展能力将会受限。
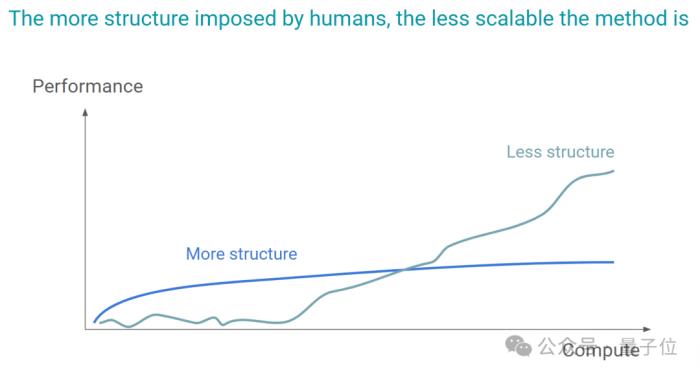
回顾AI过去70年的发展,他总结道:
与此同时,面对当前人们对scaling Law的质疑,即认为仅仅扩大计算规模可能被认为不够科学或有趣。
Hyung Won的看法是:
举个例子,在机器学习中,一个模型可能在小数据集上表现良好,但是当数据量增加时,模型的性能可能会下降,或者训练时间会变得不可接受。
这时,可能需要改进算法,优化数据处理流程,或者改变模型结构,以适应更大的数据量和更复杂的任务。
也就是说,一旦识别出瓶颈,就需要通过创新和改进来替换这些假设,以便模型或系统能够在更大的规模上有效运行。
训练VS推理:效果相似,推理成本却便宜1000亿倍除了上述,o1另一核心作者Noam Brown也分享了一个观点:
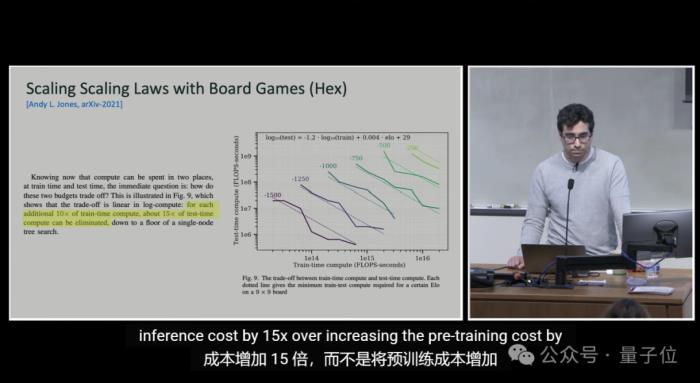
这意味着,在模型开发过程中,训练阶段的资源消耗非常巨大,而实际使用模型进行推理时的成本则相对较低。
有人认为这凸显了未来模型优化的潜力。
不过也有人对此持怀疑态度,认为二者压根没法拿来对比。
对此,你怎么看?
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。