

 新火种
2024-09-20
新火种
2024-09-20 

Qwen2.5登全球开源王座!72B击败LIama3405B,轻松胜过GPT-4o-mini
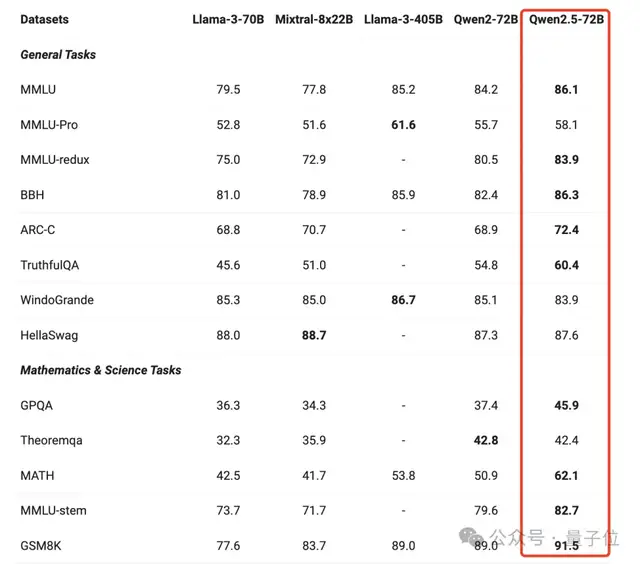
击败LIama3!Qwen2.5登上全球开源王座。
而后者仅以五分之一的参数规模,就在多任务中超越LIama3 405B。
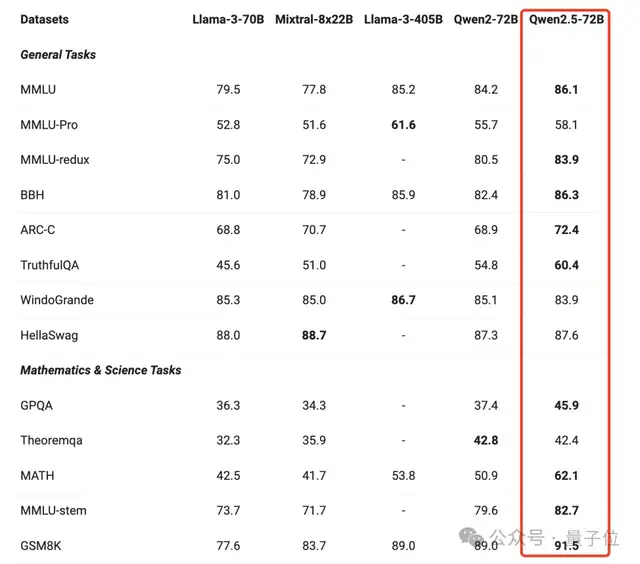
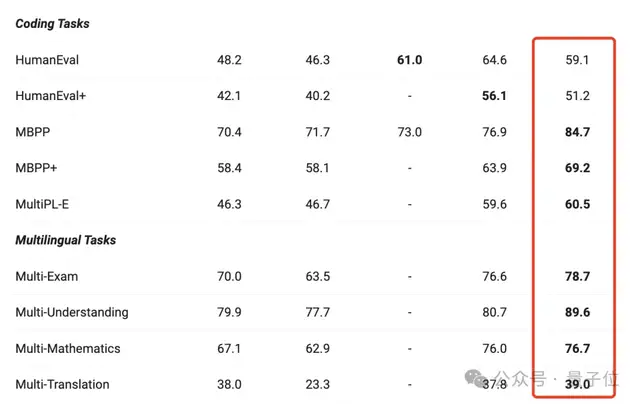
各种任务表现也远超同类别的其他模型。
跟上一代相比,几乎实现了全面提升,尤其在一般任务、数学和编码方面的能力表现显著。
值得注意的是,此次Qwen可以说是史上最大规模开源,基础模型直接释放了7个参数型号,其中还有六七个数学、代码模型。
像14B、32B以及轻量级Turbo模型胜过GPT-4o-mini。
除3B和72B模型外,此次所有开源模型均采用Apache 2.0许可。
Qwen2.5:0.5B、1.5B、3B、7B、14B、32B和72BQwen2.5-Coder:1.5B、7B和32B(on the way)Qwen2.5-Math:1.5B、7B和72B。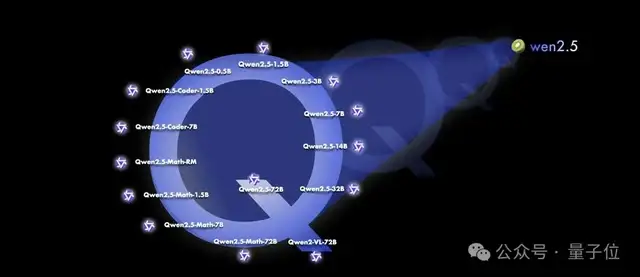
直接一整个眼花缭乱,已经有网友开始用上了。
 Qwen2.5 72B与LIama3.1 405B水平相当
Qwen2.5 72B与LIama3.1 405B水平相当相比于Qwen2系列,Qwen2.5系列主要有这么几个方面升级。
首先,全面开源。
他们研究表明,用户对于生产用的10B-30B参数范围以及移动端应用的3B规模的模型有浓厚兴趣。
因此在原有开源同尺寸(0.5/1.5/7/72B)基础上,还新增了14B、32B以及3B的模型。
同时,通义还推出了Qwen-Plus与Qwen-Turbo版本,可以通过阿里云大模型服务平台的API服务进行体验。
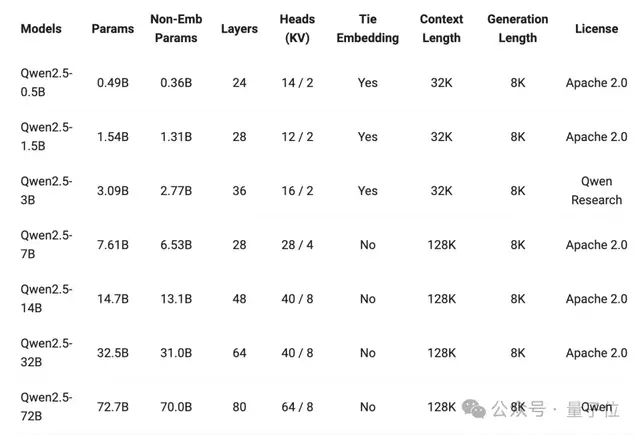
可以看到,超半数模型都支持128K上下文,最多可生成8K上下文。
在他们的综合评测中,所有模型跟上一代相比实现了能力的跃迁,比如Qwen2.5-32B胜过Qwen2-72B,Qwen2.5-14B胜过Qwen2-57B-A14B。
其次,预训练数据集更大更高质量,从原本7万亿个token扩展到最多18万亿个token。
然后就是多方面的能力增强,比如获得更多知识、数学编码能力以及更符合人类偏好。
此外,还有在指令跟踪、长文本生成(从1k增加到8K以上token)、结构化数据理解(如表格)和结构化输出生成(尤其是JSON)方面均有显著提升。
来看看实际效果。
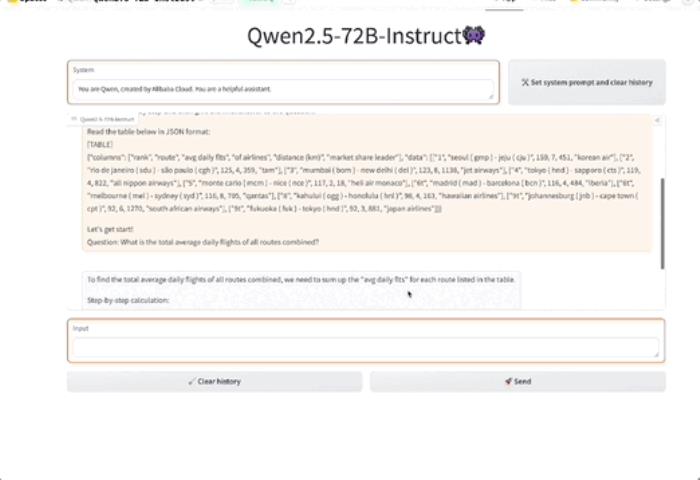
表格理解
生成JSON输出
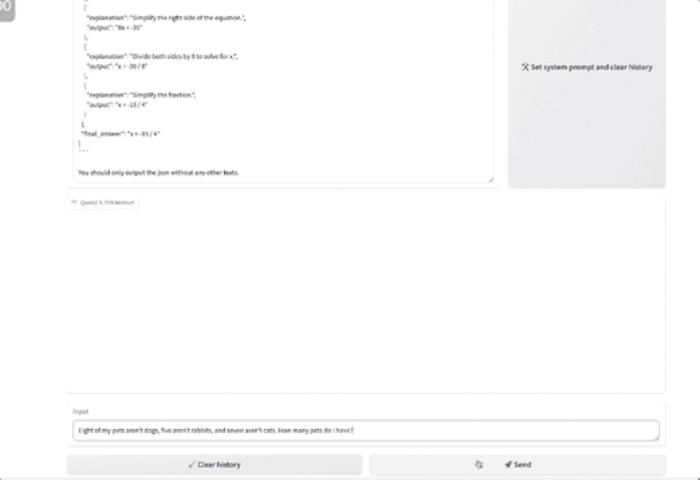
此外,Qwen2.5模型总体上对系统提示的多样性具有更强的适应能力,增强了聊天机器人的角色扮演实现和条件设定能力。
那么就来看看具体模型能力如何。
旗舰模型在前文已经看到,它在各个任务都有明显的进步。
而像0.5B、1.5B以及3B这样的小模型,性能大概是这样的:
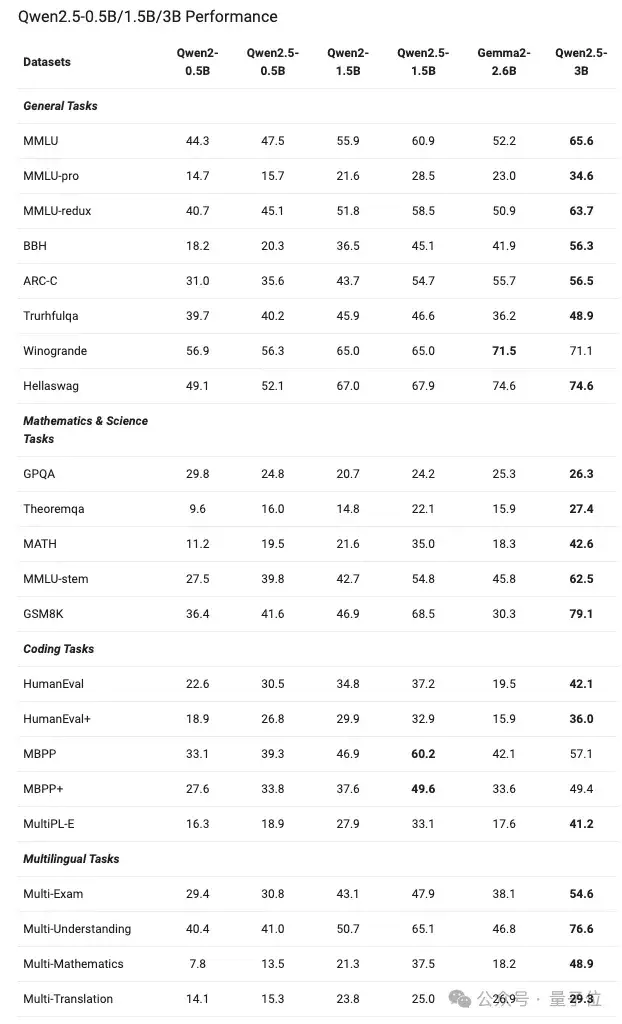
值得注意的是,Qwen2.5-0.5B型号在各种数学和编码任务上的表现优于Gemma2-2.6B。
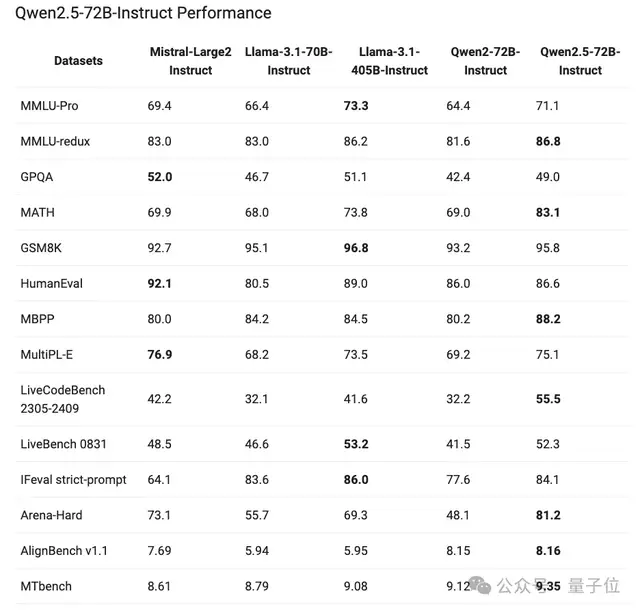
除此之外,Qwen2.5还展现了指令调优之后的模型性能,72B-Instruct在几项关键任务中超越了更大的Llama-3.1-405B,尤其在数学(MATH:83.1)、编码(LiveCodeBench:55.5)和聊天(Arena-Hard:81.2)方面表现出色。
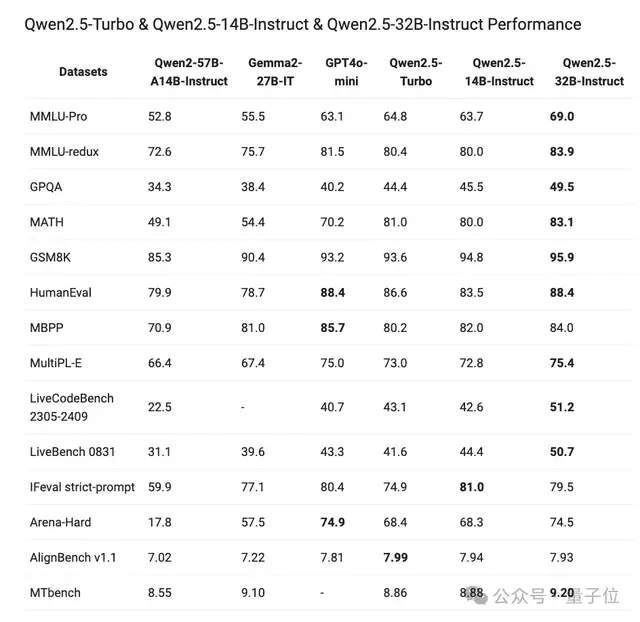
还有像32B-Instruct、14B-Instruct以及Qwen2.5-Turbo,展现了与GPT-4o-mini相当的能力。
 Qwen史上最大规模开源
Qwen史上最大规模开源除了基础模型,此次Qwen还放出了代码和数学专业模型。
Qwen2.5-Coder提供了三种模型大小:1.5B、7B和32B版本(即将推出)。
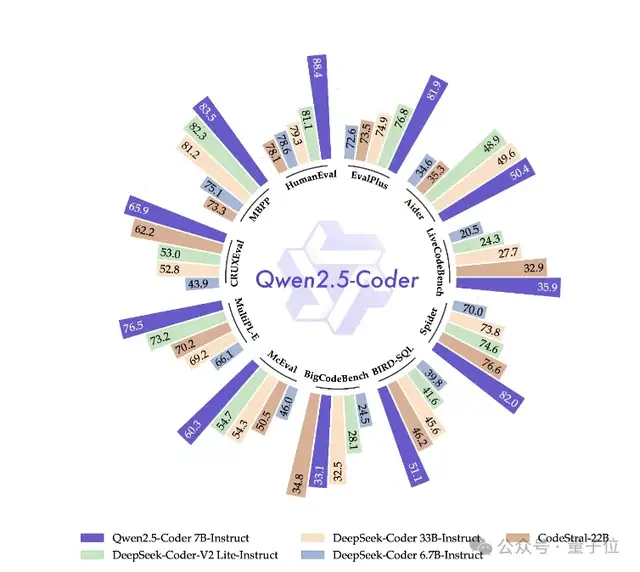
主要有两点改进:代码训练数据规模的扩大以及编码能力的增强。
Qwen2.5-Coder在更大规模的代码数据上进行训练,包括源代码、文本代码基础数据和合成数据,总计5.5万亿个token。
它支持128K上下文,覆盖92种编程语言。开源的7B版本甚至超越了DeepSeek-Coder-V2-Lite和Codestral等更大型的模型,成为目前最强大的基础代码模型之一。
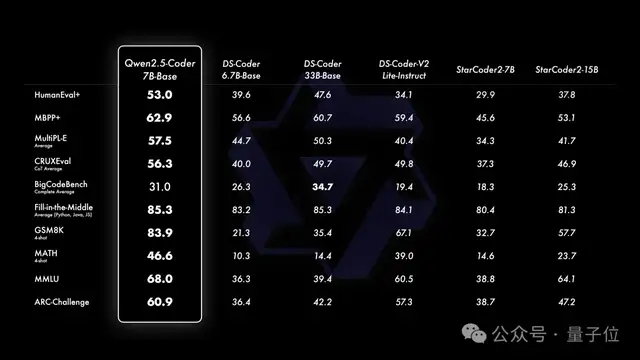
而数学模型这边,Qwen2.5-Math主要支持通过CoT和TIR解决英文和中文数学问题。
目前不建议将此系列模型用于其他任务。
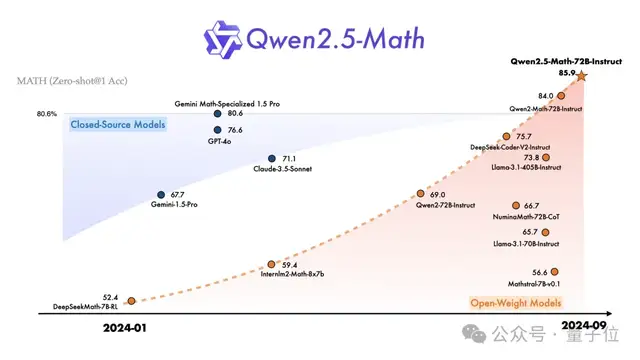
Qwen2.5-Math这一系列开源了包括基础模型Qwen2.5-Math-1.5B/7B/72B、指令调优模型Qwen2.5-Math-1.5B/7B/72B-Instruct,以及数学奖励模型Qwen2.5-Math-RM-72B。
与Qwen2-Math系列仅支持使用思维链(CoT)解决英文数学问题不同,Qwen2.5-Math 系列扩展支持使用思维链和工具集成推理(TIR)解决中英文数学问题。
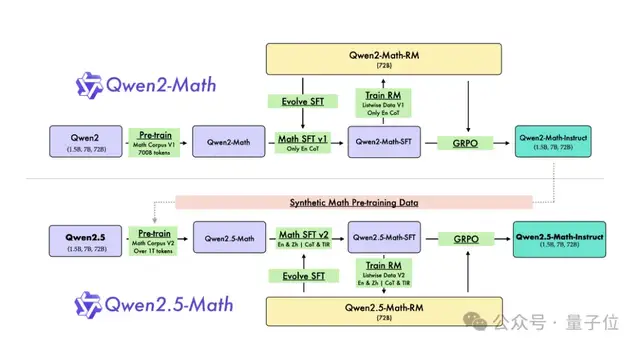
跟上一版本相比,他们主要干了这三件事来实现基础模型升级。
利用Qwen2-Math-72B-Instruct模型来合成额外的高质量数学预训练数据。
从网络资源、书籍和代码中收集更多高质量的数学数据,尤其是中文数据,跨越多个时间周期。
利用Qwen2.5系列基础模型进行参数初始化,展现出更强大的语言理解、代码生成和文本推理能力。
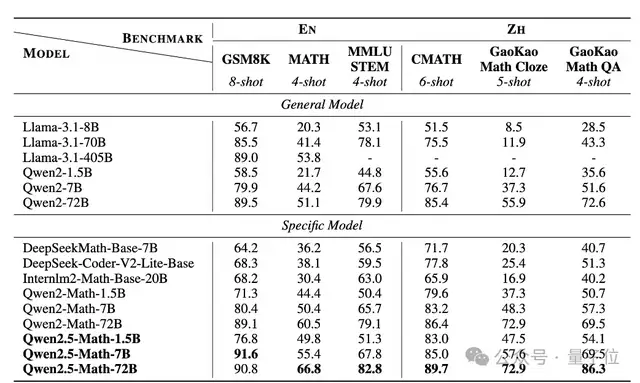
最终实现了能力的提升,比如1.5B/7B/72B在高考数学问答中分别提升了 3.4、12.2、19.8 分。
好了,以上是Qwen2.5系列一整套堪称「史上最大规模」的开源。
不叫草莓叫猕猴桃阿里通义开源负责人林俊旸也分享了背后的一些细节。
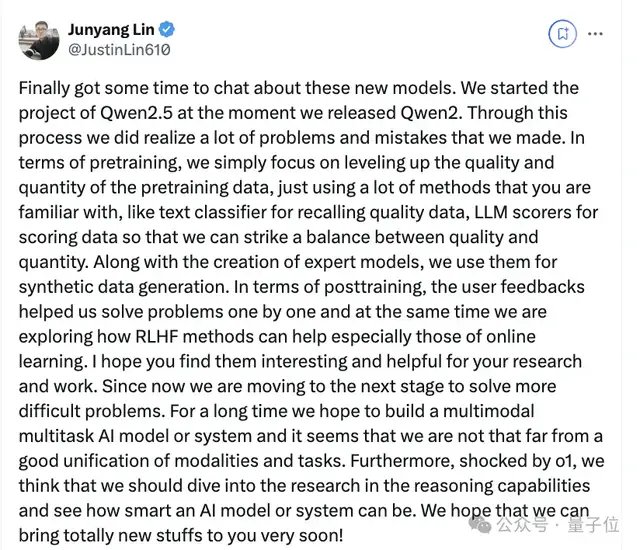
他首先表示,在开源Qwen2的那一刻就开始了Qwen2.5项目。
在这过程中,他们认识到了很多问题和错误。
比如在预训练方面,他们们只是专注于提高预训练数据的质量和数量,使用了很多大家熟悉的方法。
比如文本分类器用于召回高质量数据,LLM 评分器用于对数据进行评分,这样就能在质量和数量之间取得平衡。
还有在创建专家模型的同时,团队还利用它们生成合成数据。
在后期训练时候,用户的反馈来帮助他们逐一解决问题,同时他们也在探索RLHF 方法,尤其是在线学习方法。
对于之后的升级和更新,他表示受o1启发,认为应该深入研究推理能力。
值得一提的是,在Qwen2.5预热之时,他们团队就透露不叫草莓,叫猕猴桃。
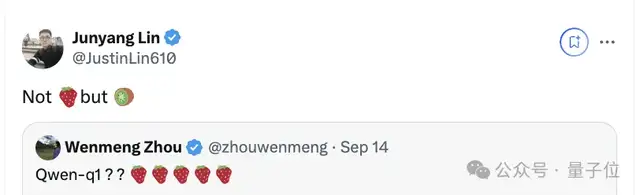
好了,现在猕猴桃可以快快用起来了。
参考链接:[1]https://x.com/JustinLin610/status/1836461575965938104[2]https://x.com/Alibaba_Qwen/status/1836449414220779584[3]https://qwenlm.github.io/blog/qwen2.5/
[4]https://qwenlm.github.io/blog/qwen2.5-llm/
[5]https://qwenlm.github.io/blog/qwen2.5-coder/
[6]https://qwenlm.github.io/blog/qwen2.5-math/
相关推荐


- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章










