新火种
2024-08-22
新火种
2024-08-22 


视频生成赛道再添“猛将”,智谱清影正式上线
年初Sora横空出世,验证了Scalling Law在视频生成方面的有效性。但Sora始终止步于公开的60秒demo,产品落地计划迟迟未有公开。
随后的半年时间,不少“玩家”继续在AI视频生成赛道展开角逐,并逐步实现落地。今年6月,快手打“前锋”,发布即可用的“可灵”成为国内视频生成赛道的“黑马”。
紧随其后,国外知名3D建模平台Luma AI也高调入局,发布文生视频模型 ,并宣布对所有用户免费开放使用,再掀波澜。
昨日,快手进一步宣布全面开放内测,同时推进商业化,上线了会员付费体系。
而就在今日,智谱也正式上线了AI视频生成功能清影(Ying),正式入局文生视频及图生视频赛道,生成6秒视频仅需30秒的时间。首发测试期间,可以免费试用。
值得关注的是,智谱是目前国内超200亿估值的大模型公司中、第一家发布视频生成成果的创业团队。
此前,智谱在外界传递的技术优势以文本、检索为先,Tier 1中多模态能力被寄予众望的两家是月之暗面、MiniMax,但在视频生成上,智谱却先人一步,率先亮出了耀眼的成绩。
快速的多模态能力成长,不仅得益于行业的技术进步,展露了智谱在多模态算法、算力储备上少为人关注的“肌肉”,更归功于智谱的扎实积累:
实际上,智谱在all in大模型之初就开始布局多模态,且在2022年率先发布了基于大模型的文本到视频生成模型CogVideo。
智谱清影便是基于这一模型的升级版——CogVideoX实现的。
“CogVideoX能将文本、时间、空间三个维度融合起来,参考了Sora的算法设计,它也是一个DiT架构,通过优化,CogVideoX相比前代(CogVideo)推理速度提升了6倍。我们将继续努力迭代,在后续版本中,陆续推出更高分辨率、更长时长的生成视频功能。”智谱AI CEO张鹏说道。
智谱“清影”正式上线
今日,智谱在Open Day上正式发布“清影”后,当前,在智谱清言平台上,该功能已正式开放内测,支持PC、APP及小程序。
目前,清影所能生成的视频时长为6s,渲染时长在30s左右。此外,所生成视频的分辨率已达1440p。
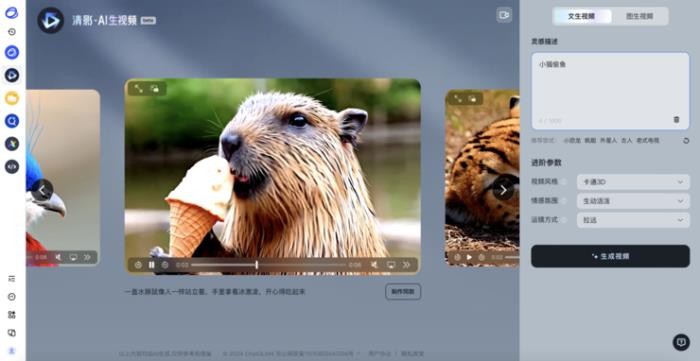
(链接:https://chatglm.cn/video)
从文生视频的具体操作来看,输入一段文字后(俗称“Prompt”),便可以自主选择想要生成的风格,包括卡通3D、黑白、油画、电影感等,再叠加清影自带的音乐,随即生成视频。
同步上线的还有图生视频功能,包括表情包梗图、广告制作、剧情创作、短视频创作等。同时,基于清影的“老照片动起来”小程序也将上线,清影在让老照片“复活”方面表现可观,且能够自动实现上色:

原图为未上色黑白版
https://sfile.chatglm.cn/testpath/video/6954cc06-7293-5144-a410-dc53c980a9b6_0.mp4
生成后视频(指令为:图中的奶奶带上头戴式耳机)
从生成视频的类型维度上看,清影主要在风景、动物、超现实、人文历史类需求上表现更好;在视频风格维度上,皮克斯风格、卡通风格、摄影风格、动漫风格均能够自主选择;镜头画面实现效果最好的是近景。
需要注意的是,在实操过程中,提示词作为重要一环,会对生成视频的效果产生一定影响。
例如,描述为“小男孩喝咖啡”与“摄影机平移,一个小男孩坐在公园的长椅上,手里拿着一杯热气腾腾的咖啡。他穿着一件蓝色的衬衫,看起来很愉快,背景是绿树成荫的公园,阳光透过树叶洒在男孩身上。”所达成的效果便不尽相同。
此外,为了使提示词更加清晰可执行,智谱还相应地提供了文生视频及图生视频的prompt智能体,辅助达成更好的视频生成效果。在图生视频界面,直接点击“帮我想一条”即可快速获得提示词。
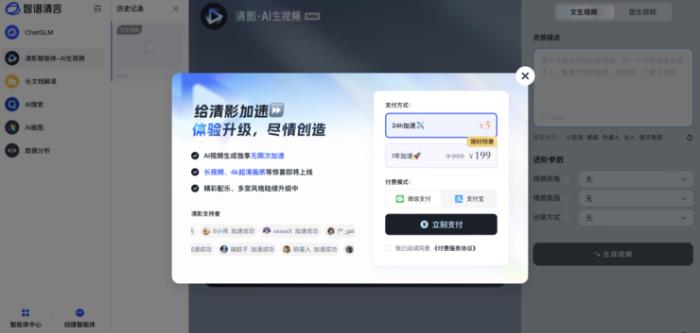
从价格上来看,此次首发测试期间,所有用户均可免费使用。
当前,清影生成视频需要排队等待1分钟以上,而如需走VIP通道快速“提货”,则需要购买加速包。清影界面显示,解锁一天(24小时)的高速通道权益收费5元,付费199元解锁一年付费高速通道权益。
值得一提的是,智谱还将成为国内首个面向开发者开放视频生成大模型的厂商。在CogVideoX上线开放平台后,开发者可以通过调用API的方式,体验和使用文生视频以及图生视频的模型能力。
依托自研提质增效
清影主要依托于智谱团队自研的视频生成大模型CogVideoX。
而从技术维度进行深度剖析来看,首先,智谱自研了一个高效的三维变分自编码器结构(3D VAE)来解决内容连贯性的问题,将原视频空间压缩至2%大小,以减少视频扩散生成模型的训练成本及训练难度。
模型结构方面,采用因果三维卷积(Causal 3D convolution)为主要模型组件,移除了自编码器中常用的注意力模块,使得模型具备不同分辨率迁移使用的能力。
同时,在时间维度上因果卷积的形式也使得模型具备视频编解码具备从前向后的序列独立性,便于通过微调的方式向更高帧率与更长时间泛化。
从工程部署的角度,基于时间维度上的序列并行(Temporal Sequential Parallel)对变分自编码器进行微调及部署,使其具备支持在更小的显存占用下支持极高帧数视频的编解码的能力。
其次,针对目前的视频数据大多缺乏对应的描述性文本或者描述质量低下的情况,智谱自研了一个端到端的视频理解模型,用于为海量的视频数据生成详细的、贴合内容的描述,增强模型的文本理解和指令遵循能力,使生成的视频更符合用户的输入,能够理解超长复杂prompt指令。
最后,智谱还自研了一个将文本、时间、空间三个维度全部融合起来的transformer架构,摒弃了传统的cross attention模块,在输入阶段就将文本embedding和视频embedding concat起来,以便更充分地进行两种模态的交互。
由于两种模态的特征空间存在很大差异,智谱进一步通过expert adaptive layernorm对文本和视频两个模态分别进行处理来弥补,更有效地利用扩散模型中的时间步信息,使得模型能够高效利用参数来更好地将视觉信息与语义信息对齐。
其中,注意力模块采用了3D全注意力机制,先前的研究通常使用分离的空间和时间注意力,或者分块时空注意力,需要大量隐式传递视觉信息,大大增加了建模难度,同时,也无法与现有的高效训练框架适配。位置编码模块设计了3D RoPE,更有利于在时间维度上捕捉帧间关系,建立起视频中的长程依赖。
多模态领域厚积薄发
多模态大模型技术底座的支撑,让智谱发布“清影”,成为积淀已久的使然。2021年,智谱正式发布文生图大模型CogView,次年迭代至CogView2,并在今年发布CogView3。
而实际上,早在2022年,基于CogView,智谱团队便已正式推出了文生视频大模型CogVideo。
据介绍,CogVideo采用多帧率分层训练策略生成高质量的视频片段,提出一种基于递归插值的方法,逐步生成与每个子描述相对应的视频片段,并将这些视频片段逐层插值得到最终的视频片段。
过去一年多,智谱在多模态大模型发展上一路狂飙。2023年3月,智谱推出了千亿开源基座对话模型ChatGLM,5月,又发布了图文对话大模型VisualGLM,随后,迅速在6月、10月推出迭代版的ChatGLM2与ChatGLM3,并在今年1月迭代至GLM-4。
去年年末,智谱还推出了多模态对话模型CogVLM,今年逐步迭代至CogVLM2。
智谱GLM大模型团队认为,“文本是构建大模型的关键基础,下一步则应该把文本、图像、视频、音频等多种模态混合在一起训练,构建真正原生的多模态模型。”未来大模型的技术突破方向之一就是原生多模态大模型。
当前,“多模态模型的探索还处于非常初级的阶段”。从生成视频的效果看,对物理世界规律的理解、高分辨率、镜头动作连贯性以及时长等,都有非常大的提升空间。而从模型本身角度看,需要更具突破式创新的新模型架构,能够更高效压缩视频信息,更充分融合文本和视频内容,贴合用户指令的同时,让生成内容真实感更高。
而在生成式视频模型的研发中,Scaling Law将继续在算法和数据两方面发挥作用。“我们积极在模型层面探索更高效的scaling方式。”张鹏表示,“随着算法、数据不断迭代,相信Scaling Law将继续发挥强有力作用。”

相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章