

 新火种
2024-04-01
新火种
2024-04-01 


马斯克突发Grok1.5!上下文长度至128k、HumanEval得分超GPT-4
就在刚刚,马斯克Grok大模型宣布重大升级。
难怪之前突然开源了Grok-1,因为他有更强的Grok-1.5了,主打推理能力。
来自xAI的官方推送啥也没说,直接甩链接。主打一个“字少事大”(旺柴)
新版本Grok有啥突破?
一是上下文长度飙升,从8192增长到128k,和GPT-4齐平。
二是推理性能大幅提升,数学能力直接涨点50%之多、HumanEval数据集上得分超过GPT-4。
消息一出,评论区立刻就躁起来了。
具体跑分结果如何,咱们立马来看。
Grok-1.5来了
首先,对于上下文窗口。
这次是一把直接提升到之前的16倍,来到128k量级。
这也就意味着Grok可以处理更长和更复杂的提示,同时保持其遵循指令的能力。
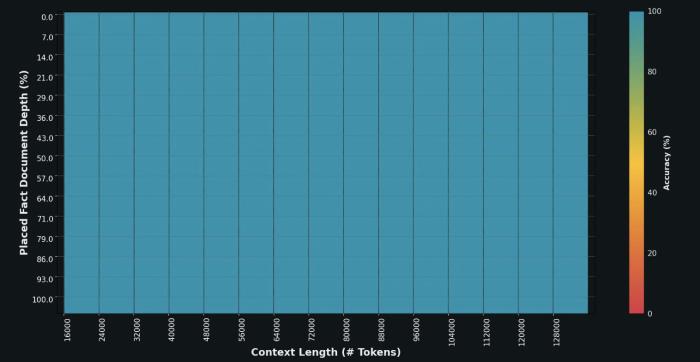
在“大海捞针”(NIAH)测试中,Grok-1.5在128K token的上下文中完美检索嵌入的文本。
整个图一水儿的蓝色(100%的检索深度):
其次,推理方面。
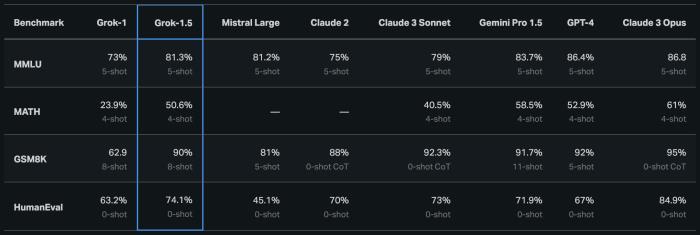
Grok-1.5处理编程和数学相关任务的能力大幅提升,全面超越Grok-1、Mistral Large、Claude 2。
数学方面,Grok-1.5在MATH基准测试上得分50.6%,超越中杯Claude 3 Sonnet;GSM8K上得分90%。
编程方面,Grok-1.5在HumanEval基准测试上得分74.1%,超越中杯Claude 3 Sonnet、Gemini Pro1.5、GPT-4,仅次于大杯Claude 3 Opus。
看起来,Grok这次的实力也是不可小觑。
Grok系列与其他大模型相比还有一个特色,不使用通用的Python语言+Pytorch框架。
据官方介绍,Grok 1.5采用分布式训练架构,使用Rust、JAX、Kubernetes构建。
为了提高训练可靠性和维持正常运行时间,团队提出了自定义训练协调器,可自动检测到有问题的节点,然后剔除。
除此之外,他们还优化了checkpointing、数据加载和训练重启等流程,最大限度地减少故障停机时间。
这,才速速有了现在的Grok 1.5~
更多信息官方也暂时还没有披露。
可以确定的是,新版本未来几天会先推送给早期测试者。并按照“老规矩”,很快将在平台上线。
有网友表示,Grok进步真的相当迅速。
有人甚至称马斯克这是发了另一个“GPT-4等效模型”,喊着:
你期待新版本的Grok吗?
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章










