


发布一天,CodeLlama代码能力突飞猛进,微调版HumanEval得分超GPT-4
昨天的我:在代码生成方面开源 LLM 将在几个月内击败 GPT-4 。现在的我:实际上是今天。
昨天的我:在代码生成方面开源 LLM 将在几个月内击败 GPT-4 。现在的我:实际上是今天。
就在刚刚,马斯克Grok大模型宣布重大升级。难怪之前突然开源了Grok-1,因为他有更强的Grok-1.5了,主打推理能力。来自xAI的官方推送啥也没说,直接甩链接。

10月15日消息,联发科日前发布了全新的旗舰芯片天玑9400,这是天玑第二代全大核SoC,更是业界首款旗舰5G智能体AI芯片。在苏黎世ETHZ AI Benchmark v6.0 芯片AI性能的测试中,天玑9400以6773分绝对高分的成绩一骑绝尘,几乎是骁龙8 Gen3的两倍,轻松拿下最强手机NP
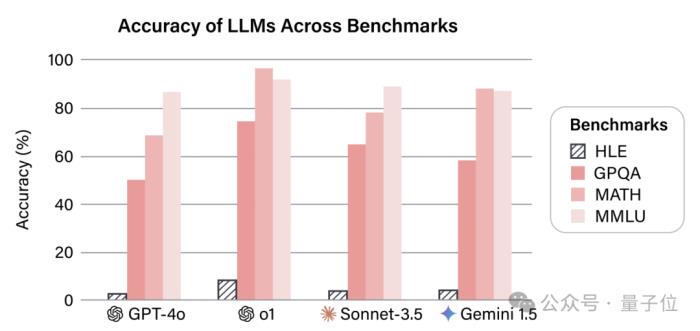
史上最难的大模型测试集来了!包括o1在内,没有任何一个模型得分超过10%。题目来自500多家机构的1000多名学者,最终入围的题目有3000多道,全部都是研究生及以上难度。入选的问题涵盖了数理化、生物医药、工程和社会科学等多种学科,按细分学科来算则多达100余个。官方更是将它称为“人类最后的考试”,

当地时间2月17日,xAI团队成员在直播中表示,在数学、科学和代码等能力表现方面,Grok-3在多项测试中均取得了比DeepSeek、GPT-4o更优的效果。
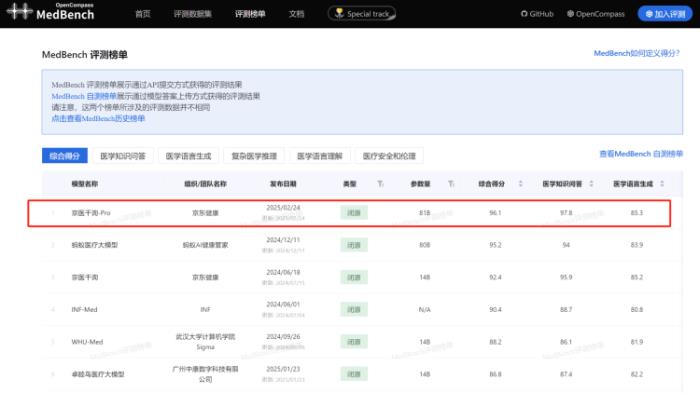
近日,京东健康旗下“京医千询”医疗大模型启动开源,成为国内医疗行业首个全面开源的垂类大模型。同时,在2月24日更新的MedBench评测榜单上,“京医千询”医疗大模型以综合得分96.1位列榜首;在权威医疗评测集MedQA上,也获得88.9的高分。此次启动全面开源,意味着“京医千询”医疗大模型的所有模

大模型趋势,给与之相关的一切来了亿点“小震撼”。人工智能/机器学习平台正是其中之一。它与大模型趋势紧密相关,能直接反映出各大云厂商的AI技术研发储备水平,以及对最新趋势的洞察和理解能力。究竟谁家实力更强?正被业内所津津乐道。而技术风向剧变之下,AI/ML平台也有了新的评价标准。国际权威机构Forre










