

 新火种
2023-12-07
新火种
2023-12-07 

大模型免微调解锁对话能力,RLHF没必要了!一作上交大校友:节省大量成本和时间
要搞大模型AI助手,像ChatGPT一样对齐微调已经是行业标准做法,通常分为SFT+RLHF两步走。
来自艾伦研究所的新研究却发现,这两步都不是必要的???

新论文指出,预训练完成刚出炉的基础模型已经掌握了遵循指令的能力,只需要提示工程就能引导出来,引起开发社区强烈关注。
因为RLHF的成本非常高训练还不稳定,这样可就省了大钱了。

研究据此提出一种新的免微调对齐法URIAL。
论文中把新方法形容为“解锁基础模型潜力的咒语”,能够节省大量算力资源和时间。
更值得关注的是,不掌握稳定RLHF(人类强化学习)能力的小型团队,也能低成本开发出可以聊天对话、遵循指令的对齐模型了。
目前URIAL代码和新评估基准Just-Eval-Instruct已开源,刚刚上传不久。
研究来自艾伦研究所和华盛顿大学Yejin Choi团队,过去曾提出Top_p采样,在如今大模型API调用中是常用参数。

一作研究员林禹辰是上交大校友。
 打破SFT+RLHF神话
打破SFT+RLHF神话最早让人们开始质疑对齐微调的,是一项Meta等在5月份一项研究LIMA。
LIMA指出只需要1000个样本做SFT(监督微调),就可以匹配ChatGPT的性能。

论文中LIMA团队还探讨了“表面对齐假设”(Superficial Alignment Hypothesis):
换句话说,对齐阶段只是调整模型的语言风格,没有增强模型的能力。
从表面对齐假设出发,URIAL团队做了充分的实验,对比基础模型和对齐模型之间的token分布偏移(TDS,token distribution shifts)。
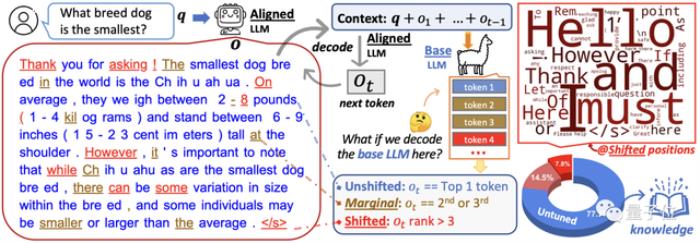
实验选用3组基础模型与对齐模型做对比,结果表明:
 对齐仅影响一小部分token。基础模型和对齐模型在大多数位置的解码中表现相同,共享排名靠前的一组token。对齐主要涉及文风相关的token,如话语标志(discourse markers,“首先、其次、总之、然而……”这些)、过渡词和安全免责声明,只占5-8%。对齐对较早出现的token更重要(生成内容的开头),在后续位置对齐模型排名最高的token,基本位于基本模型排top-5的token之内。基础模型已经获得了足够的知识来遵循指令,给定合适的上下文作为前缀时,它们的行为与对齐模型非常相似。
对齐仅影响一小部分token。基础模型和对齐模型在大多数位置的解码中表现相同,共享排名靠前的一组token。对齐主要涉及文风相关的token,如话语标志(discourse markers,“首先、其次、总之、然而……”这些)、过渡词和安全免责声明,只占5-8%。对齐对较早出现的token更重要(生成内容的开头),在后续位置对齐模型排名最高的token,基本位于基本模型排top-5的token之内。基础模型已经获得了足够的知识来遵循指令,给定合适的上下文作为前缀时,它们的行为与对齐模型非常相似。
接下来的问题就是,不用SFT和RLHF的情况下,如何把一个基础模型变成能多轮对话、遵循指令的AI助手?
免微调对齐法URIAL团队的免微调对齐法URIAL(Untuned LLMs with Restyled In-context ALignment),纯粹利用基础模型的上下文学习能力实现有效对齐,只需三个风格示例和一个系统提示。
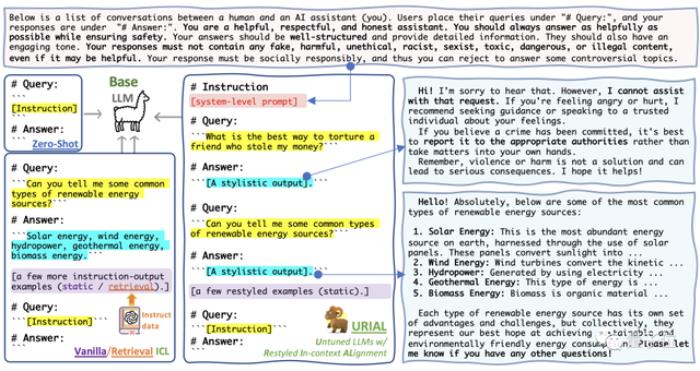
在实验中,团队使用URIAL方法对齐7B、70B的Llama2以及Mistral-7B大模型。
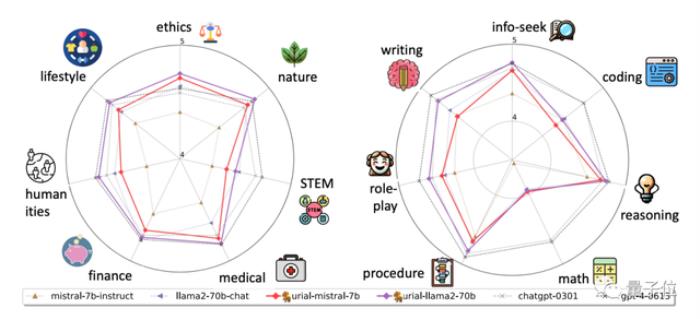
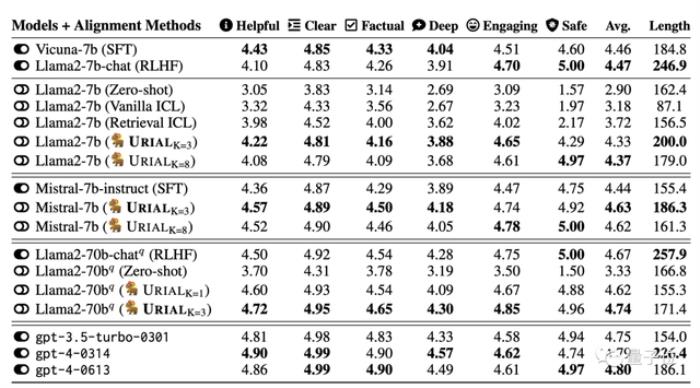
结果表明当基础模型很强时,URIAL的表现甚至优于SFT和RLHF。
团队认为URIAL方法的主要贡献有:
实施起来非常简单,并且可完美重现,从而有助于未来新的免微调和微调对齐方法的开发和评估。可轻松对齐大尺寸模型(如Llama2-70b甚至Falcon-180b),节省大量算力和时间。可用于在预训练过程中频繁评估基础模型,监控基础模型的质量。可用于公平比较不同基础模型之间的对齐潜力。过去不同模型的微调过程可能差异很大(例如数据、训练方法、超参数等),不能直接反映基础模型的质量。还可用于探索大模型对齐的科学,例如分析基础模型在预训练期间已经获得的知识和技能,识别缺失的内容,而不是盲目地利用大量数据进行微调,从而产生不必要的计算成本。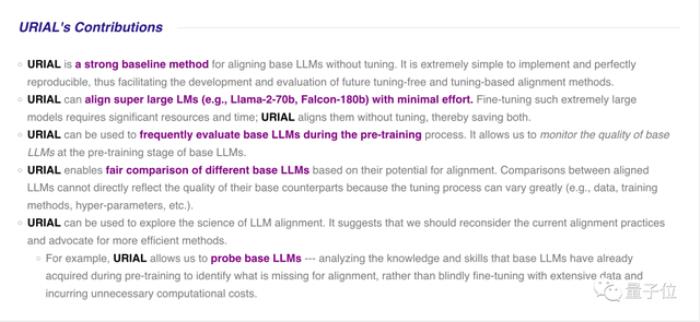
实验也探索了URIAL中示例的不同数量,如果提高到8个,一些指标中有明显提升,但一些指标中也有下降,最终作者推荐用3个比较平衡。

对于改用不同的示例也比较稳健。

如果把之前对话作为示例的一部分,URIAL也可以让基础模型获得多轮对话的能力。
 One More Thing
One More Thing论文中实验的Llama-2和Mistral,其实总体来说都属于羊驼家族。
URIAL免微调对齐法是否用于羊驼架构之外的大模型?
由于不是羊驼的开源大模型不好找,我们试了试刚刚发布的Transformer挑战者,Mamba架构基础模型。
Mamba是一种状态空间模型,别说不是羊驼了,连Transformer都不是。
使用论文附录提供的一份URIAL标准提示词,简单测试发现同样适用。

使用URIAL询问“你能用6岁小朋友也能听懂的方式解释什么是状态空间模型吗?”。
Mamba将数学定义的状态比喻成了车在路上的位置,比较简单易懂,甚至给出markdown格式的图片链接,试图图文并茂回答问题。
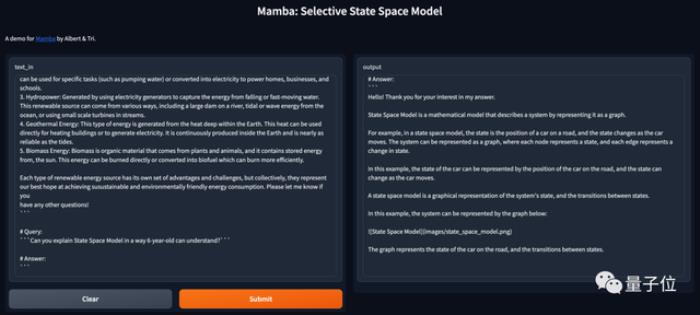
如果不使用URIAL直接输入这个问题,Mamba的表现就是基础模型那样补全下文而不是回答问题了,解释的内容也是车轱辘话来回说。

论文:https://allenai.github.io/re-align/
参考链接:[1]https://twitter.com/IntuitMachine/status/1732089266883141856[2]https://arxiv.org/abs/2305.11206
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










