新火种
2023-11-30
新火种
2023-11-30 


训练130亿大模型仅3天,北大提出Chat-UniVi统一图片和视频理解
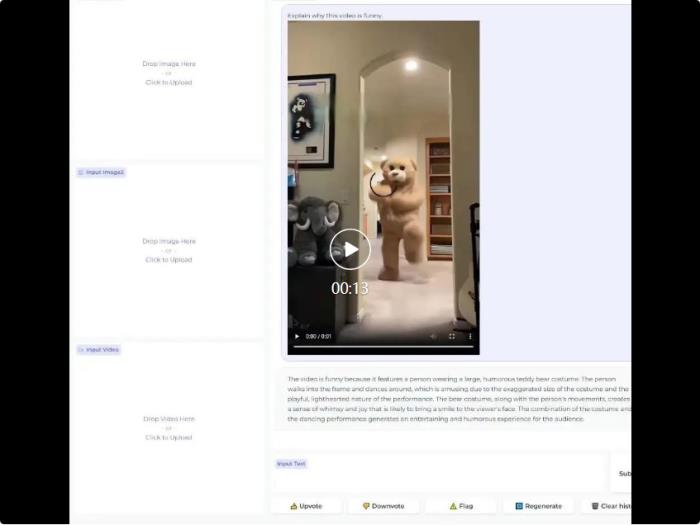
北京大学和中山大学等机构研究者提出了统一的视觉语言大模型 ——Chat-UniVi。通过构建图片和视频统一表征,该框架使得一个 LLM 能够在图片和视频的混合数据下训练,并同时完成图片和视频理解任务。更重要的是,该框架极大降低了视觉语言模型训练和推理的开销,使得在三天以内即可训练出具有 130 亿参数的通用视觉语言大模型。Chat-UniVi 模型在图片和视频的下游任务中都取得了卓越的性能。所有代码、数据集和模型权重均已开源。

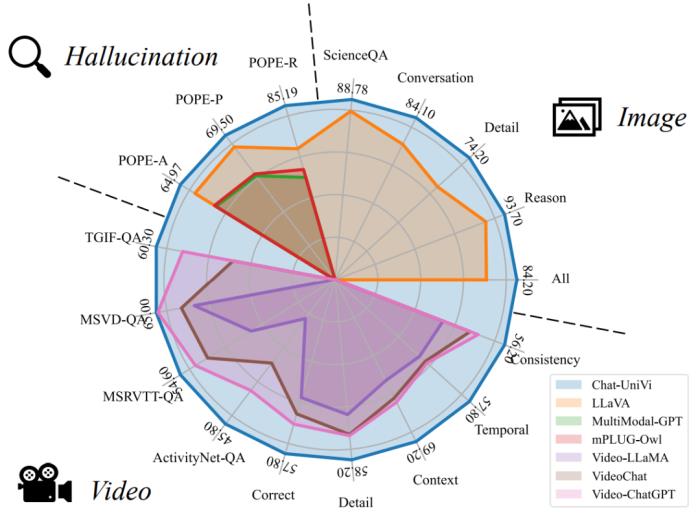
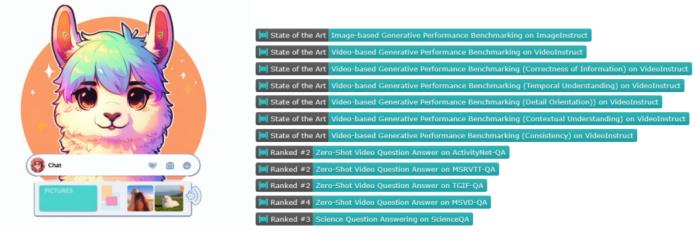 在介绍本文方法之前,我们先看一下 Demo 展示:
在介绍本文方法之前,我们先看一下 Demo 展示: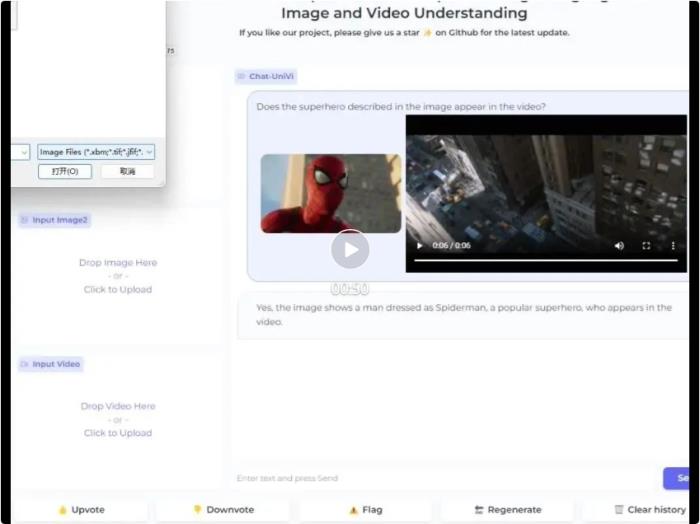
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。