


语言对齐多模态信息,北大腾讯等提出LanguageBind,刷新多个榜单
机器之心专栏机器之心编辑部北京大学与腾讯等机构的研究者们提出了多模态对齐框架 ——LanguageBind。该框架在视频、音频、文本、深度图和热图像等五种不同模态的下游任务中取得了卓越的性能,刷榜多项评估榜单,这标志着多模态学习领域向着「大一统」理念迈进了重要一步。在现代社会,信息传递和交流不再局限
机器之心专栏机器之心编辑部北京大学与腾讯等机构的研究者们提出了多模态对齐框架 ——LanguageBind。该框架在视频、音频、文本、深度图和热图像等五种不同模态的下游任务中取得了卓越的性能,刷榜多项评估榜单,这标志着多模态学习领域向着「大一统」理念迈进了重要一步。在现代社会,信息传递和交流不再局限

1月4日消息,北京大学官网消息,近日,“北大-智元机器人联合实验室”正式成立。智元联合创始人彭志辉、北京大学科技开发部部长姚卫浩,计算机学院院长胡振江,前沿计算研究中心执行主任邓小铁等嘉宾出席。

世界模型是当前的热点话题。我这里分享的题目是 “图形计算到世界模型”,作为抛砖引玉,试图挖掘和展示图形计算和世界模型两者之间可能建立的紧密内在联系。GAMES 这个平台上的报告,主要是为了交流,鼓励大胆提出想法,引发讨论,而不是单纯的宣读一些既有成果。所以,我为此做了一些调研和思考,期待通过这个报告

ChatGPT出圈New Bing走红AI“黑科技”日益成为社会热点话题面对人工智能日新月异的发展你或许会问我们该怎样认识智能学科?智能学科的研究现状如何?发展趋势又有哪些?北京大学智能学科(智能学院、人工智能研究院、王选计算机研究所)联合北京通用人工智能研究院推出“立心之约——中学生AI微课十讲”

训完130亿参数通用视觉语言大模型,只需3天!北大和中山大学团队又出招了——在最新研究中,研究团队提出了一种构建统一的图片和视频表征的框架。利用这种框架,可以大大减少VLM(视觉语言大模型)在训练和推理过程中的开销。具体而言,团队按照提出的新框架,训练了一个新的VLM:Chat-UniVi。

毫无疑问,具身智能已成为时下最流行的技术趋势之一。但相较于人类基础能力,如大脑、耳目和四肢的协同,机器人执行物理任务时仍然显得笨拙。△来源新火种智库《中国AIGC产业全景报告》如何让机器人更灵活的「动」起来?作为一切行为的起点,感知系统就显得尤为关键。

北京大学与腾讯等机构的研究者们提出了多模态对齐框架 ——LanguageBind。该框架在视频、音频、文本、深度图和热图像等五种不同模态的下游任务中取得了卓越的性能,刷榜多项评估榜单,这标志着多模态学习领域向着「大一统」理念迈进了重要一步。在现代社会,信息传递和交流不再局限于单一模态。

混合专家(MoE)架构已支持多模态大模型,开发者终于不用卷参数量了!北大联合中山大学、腾讯等机构推出的新模型MoE-LLaVA,登上了GitHub热榜。它仅有3B激活参数,表现却已和7B稠密模型持平,甚至部分指标比13B的模型还要好。
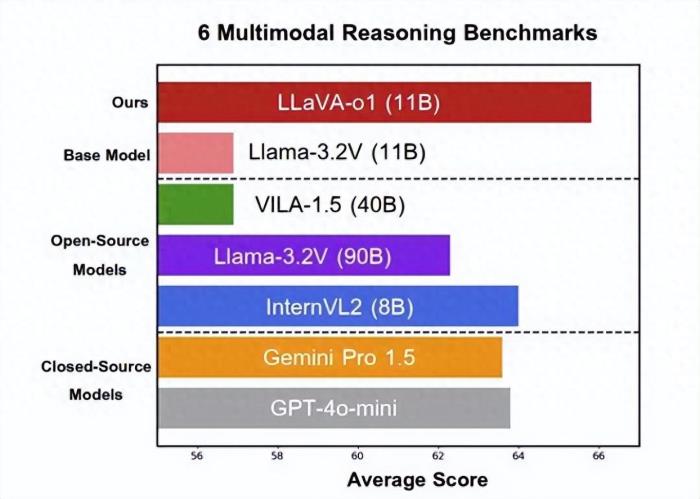
北大等出品,首个多模态版o1开源模型来了——代号LLaVA-o1,基于Llama-3.2-Vision模型打造,超越传统思维链提示,实现自主“慢思考”推理。在多模态推理基准测试中,LLaVA-o1超越其基础模型8.9%,并在性能上超越了一众开闭源模型。新模型具体如何推理,直接上实例,比如问题是:传统

AI 科技评论报道编辑 | 陈大鑫近日,由北京大学崔斌教授数据与智能实验室( Data and Intelligence Research LAB, DAIR)开发的通用黑盒优化系统 OpenBox 开源发布!相比于SMAC3,Hyperopt等现有开源系统,OpenBox支持更通用的黑盒优化场景,










