

 新火种
2023-11-22
新火种
2023-11-22 


GPT-4V医学执照考试成绩超过大部分医学生,AI加入临床还有多远?
文章来源:机器之心

图片来源:由无界 AI生成
人工智能(AI)在医学影像诊断方面的应用已经有了长足的进步。然而,在未经严格测试的情况下,医生往往难以采信人工智能的诊断结果。对于他们来说,理解人工智能根据医学影像给出的判别,需要增加额外的认知成本。
为了增强医生对辅助医疗的人工智能之间的信任,让 AI 通过一个医生必须通过的资格考试或许是一个有效的方法。医学执照考试是用来评估医生专业知识和技能的标准化考试,是衡量一个医生是否有能力安全有效地护理患者的基础。
在最新的研究中,来自马萨诸塞大学、复旦大学的跨学科研究人员团队利用生成式多模态预训练模型 GPT-4V (ision) 突破了人工智能在医学问答中的最佳水平。研究测试了 GPT-4V 回答美国医学执照考试题的能力,特别是题目包含图像的考题 —— 这对医疗人工智能系统来说一直以来都是一项挑战。
该研究表明,GPT-4V 不仅超越了 GPT-4 和 ChatGPT 等前辈,还超越了大部分医学生,为人工智能能够作为辅助诊断和临床决策的工具提供了理论上的可能。该研究分析了 GPT-4V 在不同医学子领域的性能。
同时,该研究还指出了医疗人工智能在一致解释方面的局限性,强调了人机协作在未来医疗诊断中的重要性。

论文链接:https://www.medrxiv.org/content/10.1101/2023.10.26.23297629v3
测试问题收集
该研究中,用来测试人工智能医学执照考试的题型为涉及不同医学领域、难度各异的带有图像的选择题。论文作者们选择了来自美国医学执照考试(USMLE)、医学生考试题库(AMBOSS)和诊断放射学资格核心考试(DRQCE)的三套选择题,共计 226 道题(28 个医学领域),来测试 GPT-4V 的准确性。
其中 AMBOSS 和 DRQCE 的数据未公开,需要用户注册后才能获取。AMBOSS 数据集中的每个问题都设定有对应的难度。问题按难易程度分五级,1、2、3、4 和 5 级分别代表学生第一次作答时最容易答对的 20%、20%-50%、50%-80%、80%-95% 和 95%-100% 的问题。
此外,作者们还收集了医疗专业人士的偏好,用以评估 GPT-4V 的解释是否违背医学常识。当 GPT-4V 做错的时候,作者们还收集了来自医疗专业人士的反馈,用来改善 GPT-4V。
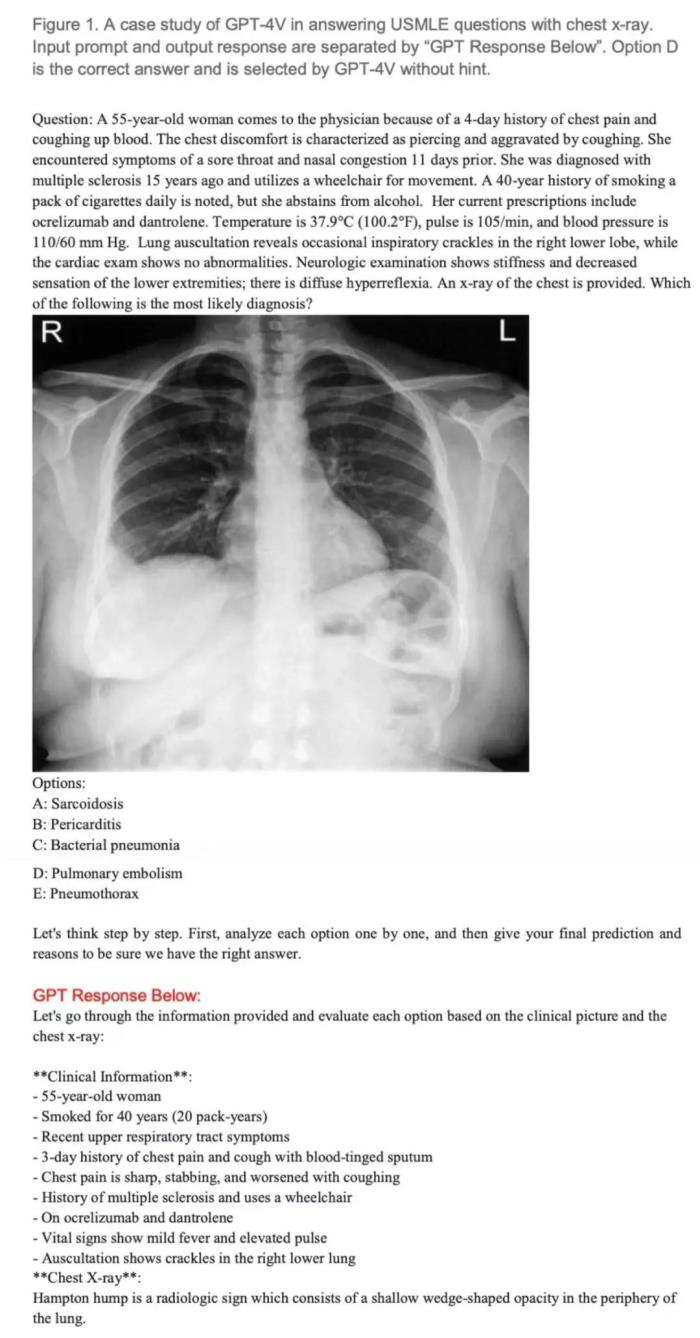
用美国医学执照考试(USMLE)中包含图像的考题测试 GPT-4V。
准确性
结果显示,GPT-4V 在带有图像的医学执照考试题上表现出了很高的准确率,分别在 USMLE、AMBOSS 和 DRQCE 上达到了 86.2%、62.0% 和 73.1%,远远超过了 ChatGPT 和 GPT-4。与准备考试的学生相比,GPT-4V 的大致排名能达到前 20-30% 的水平。
而在 2022 年,美国医学执照考试大约有前 90% 的考生通过了考试,这意味着 GPT-4V 想要获得通过,也相对较为轻松。GPT-4V 的准确率反映了它掌握大量生物医学和临床科学知识,也能够解决医患相处中遇到的问题。这些都是进入医学临床实践的必备技能。
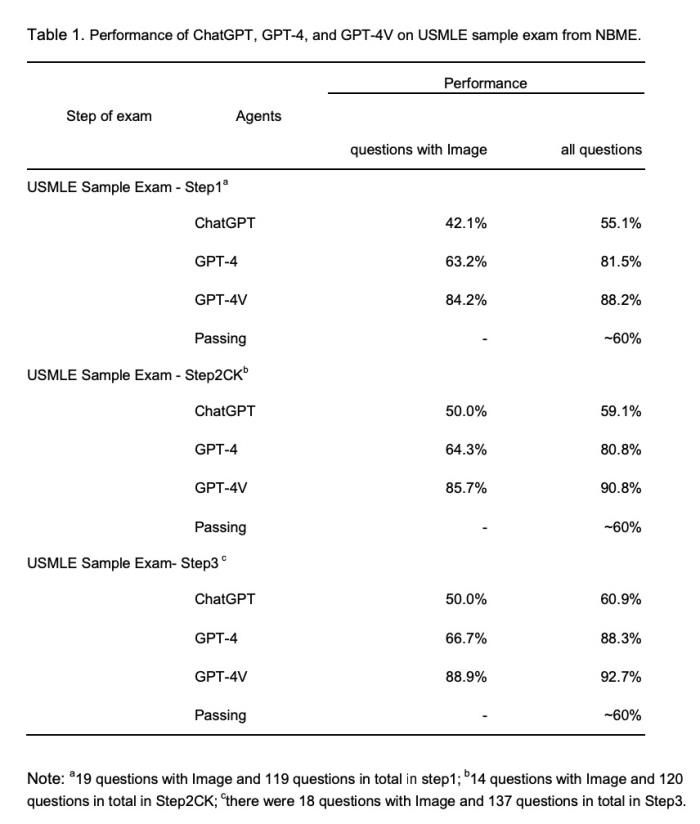
GPT-4V在美国医学执照考试(USMLE)的测试表现远远超过了 ChatGPT 和 GPT-4。
在使用提示和不使用提示的情况下,GPT-4V 在 AMBOSS 的准确率分别为 86% 和 63%。随着问题难度的增加,不使用提示时 GPT-4V 的表现呈现下降趋势(卡方检验,显著性水平 0.05)。然而,当使用提示提问时,这种下降趋势并未明显观察到。这表明,来自医疗专业人士的提示可以很好的帮助 GPT-4 做出正确的决策。
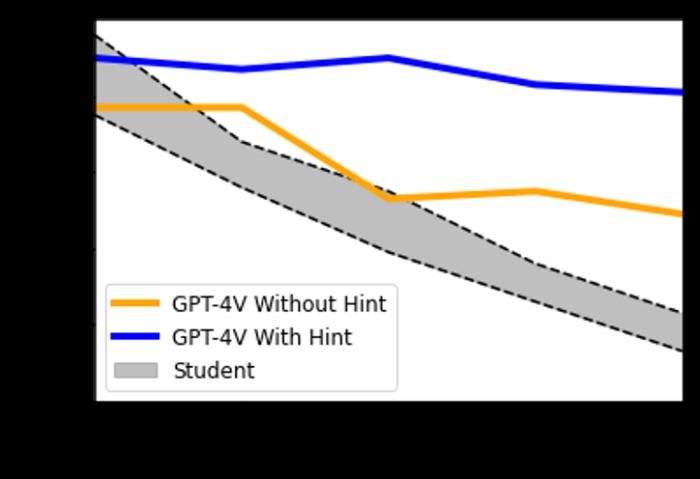
GPT-4V 和学生在不同难度 AMBOSS 考试上的准确率
解释性
在解释质量方面,作者们发现,当 GPT-4V 回答正确时,医疗专业人士对 GPT-4V 给出的解释与专家给出的解释的偏好相差不大。这说明 GPT-4V 的解释具有可信度和专业性。作者们还发现,在 GPT-4V 的解释中,有超过 80% 的回答包含了对题目中图像和文本的解读,这说明 GPT-4V 能够利用多模态的数据来生成回答。
然而,当 GPT-4V 回答错误时,它的解释中也存在一些严重的问题,例如图像误解(Image misunderstanding)、文本幻觉(Text hallucination)、推理错误(Reasoning error)等,这些问题可能会影响 GPT-4V 的可靠性和可解释性。
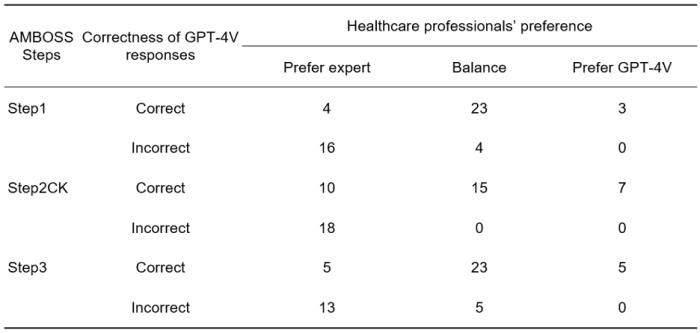
针对每道考试题,医疗专业人员从专家生成的解释和 GPT-4V 生成的解释中选择偏好。考试分为 Step1, Step2CK, Step3 共 3 个阶段。每个阶段抽取 50 道题目进行测试。
作者发现许多 GPT-4V 回答错误的解释是图像误解。在 55 个错误回答中,有 42 个回答(76.3%)是由图像理解错误所导致的。相比之下,只有 10 个回答(18.2%)错误归因于文本幻觉。
针对图像误解,作者建议使用以图像或者文字为形式的提示。例如,医生可以用箭头指示图中重要的位置,或者用一两句话来解释图像的意义来提示模型。当医生使用文字提示的时候,就有 40.5% (17/42 个) 之前错误的回答被 GPT-4V 改正了。
辅助诊断的潜力
作者还展示了使用 GPT-4V 作为影像诊断辅助工具的可能性。基于一个高血压病人的病例报告,医生对 GPT-4V 进行提问。定性分析表明,GPT-4V 能够根据 CT 扫描图像、化验单和病人症状等其他信息,提供鉴别诊断和后续检查的建议。详细分析请参考原论文。
结论与展望
作者们认为,GPT-4V 在带有图像的医学执照考试题上展现了非凡的准确率,在临床决策支持方面,GPT-4V 具备无穷的潜力。然而,GPT-4V 还需要改进它的解释质量和可靠性,才能真正适用于临床场景。
论文中尝试使用提示来改进 GPT-4V 的判断,取得了不错的效果,这为未来的研究提出了一个有希望的方向:开发更精细的人类人工智能协作系统,使得其成为临床环境中更可靠的工具。随着技术的不断进步和研究不断深入,我们有理由相信,AI 将在提高医疗质量、减轻医生工作负担和促进医疗服务普及化方面继续发挥重要作用。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章










