

 新火种
2023-11-11
新火种
2023-11-11 


生成式AI落地,有没有「万能公式」?

年初看到ChatGPT掀起生成式AI热潮时,蚂蚁集团百灵代码大模型(开源名称CodeFuse)负责人技术总监李建国迫不及待地想找合作伙伴NVIDIA聊聊。
李建国所在的办公楼与NVIDIA北京办公室仅一路之隔,步行几分钟就能到达。
来到NVIDIA北京办公室,接待李建国的是NVIDIA开发与技术部门亚太区总经理李曦鹏。
两位AI圈里的资深人士一见面,就讨论起了生成式AI落地的工程化问题。更具体的说,是CodeFuse的推理加速。
与GitHub在3月份发布的代码编写助手Copilot X类似,CodeFuse是蚂蚁集团自研的代码生成专属大模型。
算法和应用优化是李建国团队擅长的。算法和应用层优化完成之后,CodeFuse的体验还是不够理想,需要擅长底层硬件和软件的NVIDIA帮忙。
自从年初的那次见面之后,李建国的团队和李曦鹏的团队不仅有了双周会,有时候问题很紧急,周末还会有临时的会议,目标就是让CodeFuse的体验达到理想状态。
靠着两个团队相互的信任和支持,CodeFuse突破了推理中的量化难题,在大幅节省推理的成本的同时,极大提升了使用体验。
如今,借助CodeFuse,简单几条文字指令就能在线制作贪吃蛇小游戏,CodeFuse距离为程序员提供全生命周期AI辅助工具的目标越来越近,变革也将悄然而至。
“传统的软件研发人员的思维需要做一些改变。”李建国认为这是生成式AI将带来的变化。
这种变化未来将发生在千行百业,“有了大模型,接下来就是如何把这些模型“变小”,让它在各种环境中应用。今年底或者明年初,会有大量AI推理的需求。”李曦鹏判断。
蚂蚁集团和NVIDIA一起摸索出了生成式AI落地的路径,这两家走在生成式AI最前列的公司同时做了一件对整个AI业界非常有价值的事情,将合作的细节和成果开源到NVIDIA TensorRT-LLM社区。
这给正在探索AI推理加速的团队提供了一个参考,即便这不是万能公式,但一定能激发AI创新,也将加速AI无处不在的进程。
单打独斗很难落地大模型
想要占领生成式AI时代的先机,即便是业界领先的公司,靠单打独斗还不够,和生态伙伴合作成了必选项。
“蚂蚁集团和业界一样,对于研发效率的提升都有非常大的诉求,这是我们研发CodeFuse的初衷。”李建国对说,“去年开始,我们就开始用插件的方式来提升研发效率,后来ChatGPT让我们意识到我们不仅可以通过插件的方式提升效率,还可以借助大模型让CodeFuse有更多的功能。”
有探索精神的蚂蚁集团去年开始自研的代码生成专属大模型,要实现根据开发者的输入,帮助开发者自动生成代码、自动增加注释、自动生成测试用例、自动修复和优化代码、自动翻译代码等,达到提升研发效率的终极目标。
简单说,CodeFuse的目的是重新定义下一代AI研发,提供全生命周期AI辅助工具。
上半年,蚂蚁从0训练了多个十亿和百亿级参数的CodeFuse代码大模型训练,CodeFuse又适配加训了一系列开源模型,比如LLaMA、LLaMA-2、StarCoder、Baichuan、Qwen、CodeLLaMA等。
图片来自github
训练好的模型到了推理落地阶段,出现了不一样的难题。
“模型的推理部署分很多层,有最底层的软件优化,往上还有算法优化和服务优化。”李建国知道,“算法和服务优化是自己团队擅长的,底层的软件优化我们也能做,但最好的选择还是NVIDIA。”
之所以说NVIDIA是最好的选择,有两方面的原因,一方面是因为李建国和他的团队在通过插件提升研发效率的时候,经过综合评估,选择了最适合他们的NVIDIA开源项目FasterTransformer。“为了实现一些定制化功能,我们为开源端口贡献了上千行代码。”李建国团队超前的需求没得到完全的满足,需要和NVIDIA有更深度的合作。
另一方面,作为GPU加速硬件提供方,NVIDIA更加擅长结合底层的硬件和软件优化,强强联合能更快速探索出AI推理的路径。
这个合作其实是典型的双向奔赴,CodeFuse遇到落地难题的时候,NVIDIA也非常需要蚂蚁集团一起协同设计出好产品。
FasterTransformer是NVIDIA2018年推出的开源项目,目标是解决生成式AI模型推理的问题,2018年之后AI技术有了很大的进步,但FasterTransformer为了效率,很多实现写得比较固定,2023年则走到了产品转型的时期。
“蚂蚁集团非常有探索精神,从FasterTransformer到如今的TensorRT-LLM,蚂蚁集团都是我们最早的用户和贡献者,也最早提出了需求,TensorRT-LLM有很多我们的协同设计。”李曦鹏深深感受到蚂蚁集团的信任。
对于NVIDIA这家数据中心级全栈AI平台公司,面对每年各类AI国际学术会议上,成千上万篇论文讨论AI的训练和推理加速,要兼顾所有方向其实不太容易,只有和最终的用户合作,才能最大化NVIDIA软硬件的价值。
通过与客户合作,将其正向需求结合到产品迭代,NVIDIA从而在今年正式推出了加速大模型推理的开源解决方案NVIDIA TensorRT-LLM,TensorRT-LLM提供了Python接口,有灵活的模块化组件,丰富的预定义主流模型,能够极大地方便开发者在NVIDIA平台上部署基于大模型的服务。
图片来自NVIDIA官网
大模型推理落地的关键——低成本,大吞吐量
蚂蚁集团的CodeFuse从训练到推理,NVIDIA的AI推理加速方案从FasterTransformer到TensorRT-LLM,双方要一起解决的是低延迟的响应,还有能回答更长的问题。
“自动生成代码特别是在IDE里面的代码补全对延时有很高要求,如果代码一个字符一个字符蹦出来,程序员肯定受不了,一般来说代码补全的响应时间在200毫秒以下才会有好的体验,更长的时延程序员一般受不了。”李建国指出了CodeFuse落地的一个难题。
解决这个问题的一个好办法是量化。模型量化,就是将使用高精度浮点数比如FP16训练的模型,使用量化技术后,用定点数比如INT4表达。量化的关键点是对齐两个精度(FP16和INT4)的输出,或者说让两个精度输出的数据分布尽可能保持一致。量化的好处是可以有效的降低模型计算量、参数大小和内存消耗,提高处理吞吐量。
“我们内部做了一些评估,8比特量化损失的精度比较少,基本是无损,同时可以带来30%左右的加速。如果是量化到4比特,一般量化方法的精度损失会达到7-8%,但如果能把精度损失做到1%以内,可以带来2倍左右的加速。”李建国说,“要实现量化到4比特的同时精度损失小于1%,我们需要在核心的算法层面创新,也同时需要NVIDIA TensorRT-LLM的软件优化确保推理加速。”
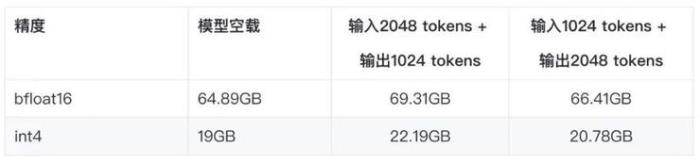
量化的价值显而易见,CodeFuse-CodeLLama-34B模型在FP16和INT8精度下,至少需要4张A10 GPU做最小配置部署。量化到INT4之后,模型占用显存从64.9G显著减小到19G,一张A10 GPU即可部署。
从需要4张A10减少到只需要1张A10,成本的降低显而易见,速度也让人满意。
使用GPTQ或者NVIDIA TensorRT-LLM early access版本量化部署,实测发现A10上的INT4优化后的推理速度,已经和A100上FP16推理速度持平。
在程序生成的HumanEval评测和几个NLP任务(CMNLI/C-EVAL)的评测中表现也非常出色。
结果让人满意,但过程中难免出现意外,李建国和团队同事将CodeFuse量化部署到A100运行正常,但部署到A10 GPU上时,输出出现了乱码,但没有找到问题根因,而此时恰逢周末。
“了解到我们的问题之后,NVIDIA的伙伴说可以马上来帮我们一起解决问题。”李建国印象深刻,“后来NVIDIA的伙伴发现其实问题很简单,就是容器的一个配置错了,物理机并没有问题,改完容器的配置就正常了。”
李曦鹏对这件事情也印象深刻,“周末一起调试,是建立在双方通过长期合作信任的基础上。彼此愿意相信,相互协同才能更快达成目标。”
想要达到双方技术团队默契配合,必须要有充分的沟通和信任,还要有优先级。
“为了快速响应蚂蚁集团的需求,以前我们的软件更新一般3个月才更新一次,现在不到一个月就会给他们一版。”李曦鹏感叹这种变化,“我们的代码拿过去也会有bug,蚂蚁的伙伴给了我们包容。”
至于如何适应客户的快节奏,李曦鹏认为关键在于要有优先级,“NVIDIA所有产品,最重要的优先级都来自于客户的需求。”
对于AI推理来说,与量化一样影响体验的是推理长度。
更大的推理长度意味着用户可以一次性输入更长的文档,也可以实现多轮对话,目前业界标准的推理输入长度是4K、16K,并朝着1Million的长度在努力。
CodeFuse-CodeLLama-34B模型目前在A10上,4比特量化支持总长为3K+长度的输入和输出。
“如果只是单纯加长输入长度,挑战非常大,因为计算量需求会出现O(n^2)增长。”李曦鹏介绍。
要解决客户的问题,还要求NVIDIA有极强的技术敏感度和技术创新能力。“最近有一个Flash-Decoding的技术,可以更好的加速长序列的推理。而实际上,我们早已经在TensorRT-LLM中独立的实现了这个特性,叫做multi-block mode,目前还在对更多模型进行测试,下个版本会放出来。”李曦鹏表示。
李建国有些惊喜,“上周末知道TensorRT-LLM已经支持Flash-decoding时非常开心,NVIDIA有前瞻性,能够快速支持最新的技术,这对于提升CodeFuse的体验非常重要。”
蚂蚁集团和NVIDIA依旧在继续优化CodeFuse的部署,目标就是提供低成本、低时延、高吞吐量的AI大模型使用体验。
CodeFuse正在变得越来越强大,这会带来一个问题,AI会带来怎样的变革?
大模型落地没有万能公式,但很快会无处不在
就像电刚发明的时候人们会担心会产生事故一样,大模型也处于这样的时刻。“未来五年或者十年,人工智能大模型会深入我们生活的各个角落。”这是李建国的判断。
就拿他在负责的CodeFuse来说,软件研发人员的思维需要前移或者后移,前移的意思是要考虑整个APP的概念设计、创意,后移是考虑APP后续的运维和增长。
“当写重复代码的工作被AI提效之后,软件研发人员有更多时间需要思考更复杂、更有创意的东西。而不仅仅只是关心算法、数据,要去兼顾更多内容,要有技能的增长。”李建国观察认为,“前端设计比较标准化,可能会更快受到影响。”
“但现在看来AI依旧是提升效率的辅助工具。”李建国和李曦鹏都认为。
这种影响会随着AI模型的成熟逐步影响到越来越多行业和领域。蚂蚁集团和NVIDIA就将其在CodeFuse方面的合作进行了非常细节的开源,这对于TensorRT-LLM开源社区来说是一个巨大的贡献,也将深刻影响生成式AI的落地和普及。
比如生成式AI落地部署非常关键的量化,有NVIDIA和蚂蚁集团实践开源的例子,基于TensorRT-LLM量化就会更加容易。
“论文介绍了一些方法,但还需要算法工程师针对具体的场景和模型去做调整和测试的。”李曦鹏说,“NVIDIA要做的是做好绝大部分底层的工作,让整个业界在此基础上做更多的创新。”
李建国看到了开源对于AI无处不在的重要价值,“就像数学分析里有个万能公式,它不是所有场景都能用,但开源可以让更多的场景使用,相当于普惠大众。”
李曦鹏表示,TensorRT-LLM开源两周,就有超过200个issue,大家热情非常高涨。
NVIDIA也在通过2023 TensorRT Hackathon生成式AI模型优化赛这样的赛事完善TensorRT-LLM,加速生成式AI的落地和普及。
比尔·盖茨曾说,“我们总是高估未来两年的变化,低估未来10 年的变革。”
以CodeFuse为例,NVIDIA和蚂蚁集团的合作和成果,将会对未来10年的变革产生深远影响。
相关推荐


- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章










