

 新火种
2023-10-31
新火种
2023-10-31 


西电焦李成院士:从脑科学和认知科学到人工智能,我们能够从生物物理机理中得到什么启发?

作者 |Don
编辑 | 王晔推动认知人工智能,不仅需要“感知”也需要“认知”。在2021年中国人工智能大会(CCAI 2021)上,焦李成院士做了主题为《类脑感知与认知的挑战与思考?》的学术报告。本次报告首先对人工智能的发展经过进行了反思与梳理,在此基础上面向认知建模、自动学习和渐进演化这三个主题,汇总了其研究组近几年在相应领域的多项成果。
焦李成,工学博士,教授,博导,欧洲科学院外籍院士,俄罗斯自然科学院外籍院士。主要研究方向为智能感知与量子计算、图像理解与目标识别、深度学习与类脑计算。现任西安电子科技大学计算机科学与技术学部主任、人工智能研究院院长、智能感知与图像理解教育部重点实验室主任、教育部科技委学部委员、教育部人工智能科技创新专家组专家、“一带一路”人工智能创新联盟理事长,陕西省人工智能产业技术创新战略联盟理事长,中国人工智能学会第六-七届副理事长,IEEE/IET/CAAI/CAA/CIE/CCF Fellow,连续七年入选爱思唯尔高被引学者榜单。研究成果获国家自然科学奖二等奖及省部级一等奖以上科技奖励十余项。
以下是演讲全文,本文进行了不改变原意的整理。
目前,神经网络和深度学习快速发展,在这个新兴的领域中,最核心并且最引人注目的方向是网络的优化方法。
本文会分五个部分来和大家进行交流:人工智能和深度学习的关系、后深度学习——认知建模、自动学习、渐进演化,以及总结。
人工智能与深度学习梳理

人工智能诞生距今已有60余年,在1956年的达特茅斯会议上,麦卡锡、明斯基、罗切斯特和香农等科学家首次提出“人工智能”这个术语,从而标志着人工智能正式成为一门科学,并明确了其完整的学术路径,也标志了人工智能这一新的领域正式诞生。
他们不仅在讨论中催生了人工智能这一概念,而且具有前瞻性的工作也对后世产生了深远影响,尤其是对IT领域。
人工智能按照其自然发展的历史,可以分成四个阶段:专家系统、特征工程、语音图像和文字处理,以及以增强学习、对抗学习、自监督学习、元学习和强化学习为代表性技术的当前阶段。
在专家系统阶段(1960~1980年),人工智能较为初级,主要依赖的技术是人工设计的规则。在这个阶段,人们主要希望人工智能系统能够进行搜索工作。
在特征工程阶段(1980~2000年),人们开始对原始数据进行处理从而提取特征,并使用简单的机器学习模型进行分类、回归等任务。
在第三阶段(2000~2010年),人们开始对语音、图像和文字等自然信息进行处理。在该阶段中,人工智能系统会将原始数据和答案标签输入深度学习模型。但是基于当时传统的二值串型结构的机器学习模型无法对如此复杂的系统进行学习从而完成对应的复杂任务,因此AI进入下一阶段。
在第四阶段(2010~2020年)中,人们将数据交给机器,并希望机器能够自动在数据中间挖掘其中所蕴含的知识。但是在实际的应用中,系统仍旧依赖人类对模型和数据进行组织编排,从而指导模型进行知识的挖掘。我们虽然希望AI模型能够自动挖掘知识,但是模型的成功运行很难离开人类的监督和指导。
在这个绚烂的第四阶段中,产生了机器证明、机器翻译、专家系统、模式识别、机器学习、机器人与智能控制等多种领域。虽然他们的核心不同,但都是AI发展第四阶段中不可或缺的重要部分。
除了从时间上对人工智能进行梳理外,我们还可以将人工智能按照其核心思想分为五个学术流派:符号主义、联结主义、行为主义、贝叶斯学派和类推学派。
在人工智能发展初期,这五种学派之间并没有过多的交融与借鉴,都是各自埋头苦干、各自为营,并对自己的应用领域充满信心。
时至今日,我们发现这些学派其实都是从各自的角度出发对人工智能和机器学习进行阐释。而人工智能的发展,则需要将这五大学派相互融合借鉴。

IEEE神经网络先驱奖得主鉴证了人工智能的发展历程:
Shun-ichi Amari(甘利俊一)提出了神经场的动力学理论,特别在信息几何方面作出了奠基性的工作。
Paul J Werbos,他1974年在哈佛大学博士毕业。Werbos主要建立和提出了反向传播算法BP,可以说Werbos是BP算法的第一人。哪怕是如今对深度学习普及影响颇深的Geoffrey Hinton,也是当年和Werbos一起共同研究BP算法小组的成员,他也为BP算法的广泛使用和传播做出了诸多贡献。
Leon O. Chua是一位华裔科学家,人们将其奉为加州大学伯克利EE领域的三巨头之一。他创立了非线性的高阶原件,提出了蔡氏混沌电路(Chua's Circuit),促进了非线性电路理论的发展,掀起了研究非线性电路的热潮,为混沌从理论走向实际做出了卓越贡献。此外,他还提出了CA细胞神经网络,在世界上的影响力巨大,是华人的骄傲。很多杂志曾经介绍过他的CA、混沌电路等科学发现。至今,他仍活跃在中美科学交流的一线。
Fukushima是神经认知的提出者。Oja是芬兰的科学家,也是“子空间”的提出者。姚新老师对进化计算的贡献非常巨大。王钧老师也对神经网络的研究作出了重要贡献。LeCun在2014年因为其1990-1992提出的卷积神经网络而获奖;之后Bengio在2019年获奖。而今年的获奖者是广东工业大学的刘德荣老师,他也是前任IEEE Trascations on Neural Networks, TNN的主编。

历经70年发展,神经网络也进入到了一个新的阶段。从技术上来说,他有别于纯粹的“喂数据”的传统方式。其实从宏观上来讲,简单的基于BP算法的数据训练方式已经成为过去时。
如今我们面对的是海量、有噪声、小样本、非平稳、非线性数据的表达、学习和解译等场景和问题。这和传统的方法有很大区别。
人工智能已经经历了从“特征工程”、“特征搜索”到现在的“表征学习”和“学习解意”的新阶段。这为计算机视觉领域带来了大数据驱动的表征学习、识别和优化的新范式。
神经网络的学习包含很多因素。其中最根本的是科学问题的研究;再者是学习理论的理解,包括表示理论、优化理论、泛化理论。其算法基础不仅仅是网络模型结构本身(如CNN、自编吗、RNN、GAN、Attention等深度学习结构组合),更是其背后的机理,生物机理、物理原理。当然,也包括提升算法有效性和可行性和在线处理的计算方法。
模型的优化方法对神经网络起着十分重要的作用。优化不仅是以传统的梯度为基础的体系发展。其中应用最多的是以全局达尔文、局部拉马克为首的自然启发的计划算法,但该类算法要面临诸多问题,如随机、正交和收敛等。当然,从数据基础本身来讲,系统也面临着要和数据匹配的增广、领域自适应处理、归一化等问题。此外,我们现在拥有了很多强有力的平台基础框架技术,比如Pytorch、Tensorflow、Keras和Caffe等。
但是,深度学习也面临了诸多难题,包括其自身理论或技术中的固有缺陷(非线性、小样本、噪声等问题),以及现实人工智能问题面临开放的变化环境。这些瓶颈问题需要在理论上进行解决。首先,我们需要研究问题的阐述方法,来解决特征和决策间不明的关系和解释的优先级问题;此外,我们还要解决认知上的缺陷,即概念的抽象、自动学习、渐进学习、直觉和遗忘等;当然在学习的瓶颈问题中,收敛的一致性、稳定性、梯度驻点属性等数学问题也需要攻克。
目前来说,研究员们还没有针对可解释性的系统化的理论和解决工具。
我们可以将可解释性的研究分成三类:
首先,我们可以在建模之前对数据的分布特性进行理解和阐述。
其次,我们可以通过建立规则的方式来实现对模型的可解释性的探索。
最后,我们可以在建模之后,对模型的动作和功能(包括模型的生物机理和物理机理)进行有效的系统研究和解释,这是一种更加宏观的方法。
理论缺陷:不稳定性
在不稳定梯度的问题上,梯度消失和过拟合缺失问题困扰人工智能算法已久。我们通常会通过制定损失函数和范数等方法对其进行解决,但是该问题并没有因此而彻底解决。神经网络存在长时记忆和短时记忆,因此它也存在着灾难性遗忘的问题。这些灾难性遗忘的理论表征、学习方法、选择性遗忘和动力学空间的设计也是一个重要的课题。
人们所设计和部署的神经网络模型,会在很复杂的环境中运行和工作,并且这些环境中有人类的参与。因此,它们是在一种开放和动态的环境中运行的,在这种环境中可能存在多种攻击(黑盒、白盒、灰箱)。
那么其安全性就是一大问题。因此,神经网络在对抗攻击环境中的自我防御,也是一项重要的课题。
算法的效益比(即部署的代价)是一项在部署前要考虑的重要问题。我们希望设计一种绿色、资源可优化的软硬件环境。并希望算法能够利用稀疏化方法,使其体积轻量化。因此,利用关键样本和小样本的学习就显得尤为关键。
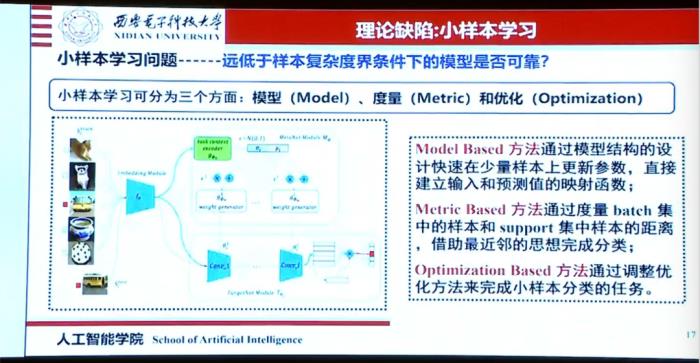
小样本学习所面临的问题可以分为模型、度量和优化三个方面。
其中模型的问题在于如何利用稀疏性、选择性和可变更新来建立稳定的模型。
度量的问题在于如何用对实际的数据集因地制宜的设计度量方法,从而使网络学习到最佳参数。
优化的问题在于通过调整优化方法来完成海量小样本的分类、回归任务。
这是“老同志”遇到了新问题,也是要让“新同志”加入到人工智能的大家庭中。
此外,还有一些其它的瓶颈问题有待解决。
深度学习的成功严重依赖于数据集。成也数据,难题也在数据。因此,高质量数据的寻找和收集,一致性决策方法的制定是其中的根本症结。而如何解决模型坍塌问题、特征同变性问题、不平衡问题、安全性问题、局部最小值问题,则都是困扰深度学习发展的瓶颈。
后深度学习——认知建模
那么在后深度学习时代,我们应该如何解决上述问题呢?
我们的思考是——认知建模。

神经网络源于脑神经的计算,但是当我们回顾生物学中脑神经的过程会发现,真实的生物大脑中并不是用简单的计算来实现大脑认知的。
类脑结构中所有的建模均具有稀疏性、学习性、选择性和方向性。然而可惜的是,这些自然的生物特性在我们目前的神经网络设计中并没有被充分考虑进去。
这是遗憾,也是机遇。
当前的深度学习技术仅利用并行输入,输出和海量神经元来解决所遇到的问题。
因此,仔细地回顾人脑的结构,有益于指导研究人员设计出更加优秀的神经网络结构。
可以说,类脑感知和脑认知的生物学基础,为实现高效准确的复杂感知和解译提供了新的思路。
神经网络的思路是:感,知,用。
宏观上来说,神经网络模型需要首先对人类的认知特征进行建模,结合对深层结构、多源综合的宏观模拟、神经元稀疏认知、方向选择的微观模拟,以及神经元间显著注意、侧抑制等介观模拟信息,设计具有稀疏性、选择注意、方向性等特点的单元,构建新型深度学习模型。通过认知特性的建模提升对复杂数据的表征、处理与信息提取的能力。实现这样的思路则这是我们的重要任务。
总结来说,认知建模就是对人脑认知过程中地微观、介观、宏观特性进行分析与模拟。
但是我们在该方面的工作还远远不够。
例如,早在1996年就已经有人在神经元的稀疏性方面提出了相应的生理学发现和论著。并且发表在Nature、Science等著名期刊上。这些工作已经面世二三十年了,但是我们至今仍旧未完全将其利用起来。认知的稀疏性建模,是我们迫切需要解决的问题。从技术上来说,稀疏性建模是指模拟基于生物视网膜机理的高效场景信息稀疏学习、初级视皮层各类神经元动态信息加工与稀疏计算,以及中/高级视觉皮层神经元特性的稀疏识别特点,发展的稀疏认知学习、计算与识别的新范式。我们已经将这些思想和发现发表在2015年的计算机学报中。
在认知建模和稀疏性的利用方面,我们将稀疏性的表征和深度学习,以及考虑数据的随机性特征结合起来,提出了多种神经网络模型。这不仅仅表现在训练过程的调参、训练的技巧和性能的提升,更是表现在研究深度学习和各类传统机器学习模型之间的内在关系,以期理解深度学习的工作原理,构建更加强劲、鲁棒的理论架构等方面。
模型稀疏性不光表现在激活函数的逼近,更表现在分类器的设计,也表现在对随机特性的处理上。我们提出的研究结果,包含了结构的处理,也包含了稀疏的正则化,连接结构的剪枝、低秩近似,和稀疏自编码模型。这些方法在实际的运行中都十分有效。
此外,我们还提出了快速稀疏的深度学习模型、稀疏深度组合神经网络、稀疏深度堆栈神经网络、稀疏深度判别神经网络,和稀疏深度差分神经网络。在实际中也验证了这些方法的有效性和先进性。
在类脑学习性和深度学习的结合方面,我们发现人类能够从少量的数据中学到一般化的知识,也就是具有“抽象知识”的学习能力。我们能希望将这种特性在神经网络中表示出来。
举一个典型的例子。
在这项工作中,我们将极化SAR数据的Wishart分布特性和DBA结合起来,同时利用数据局部空间信息编码的特性,建立了快速的极化SAR分类模型,其实现效果良好。
其核心是物理的机理和深度学习的模型的结合。这篇文章发表在IEEE Transcation on Geosciences and Remote Sensing上,受到了广泛关注。

同样,为了使模型结构更加高效,我们将堆栈和模型进行结合,提出了一种速度快、自动化成都高、鲁棒性好的深度学习快速模型。
其通过对目标数据的自动高层语意的特征提取,实现了自动、高效和精准的分类。这篇工作发表在IEEE Transactions on Image Processing上。这项工作的速度很快,因为它能将物理特性结合到深度学习的并行处理模型当中。
我们同样利用类脑的选择性进行研究。其生物机理是发表在2011年的Science科学杂志,以及2012的Neuron神经杂志上。它的生物原理表明视觉信息的加工具有显著的注意力机制。这个注意机制和人脑的注意机制相同。
人脑中的注意机制建模会增强概念学习和认知学习的能力。注意力是人类认知功能的重要组成部分。人类在面对海量信息时,可以在关注一些信息的同时,选择性忽略部分信息。计算机视觉领域的注意力机制和大脑的信号处理机制也是类似的。例如最近大火的Transformer技术,也是类似的原理。
在类脑的方向性结合研究方面,我们所基于的胜利机制发表在2015年的Nature自然杂志上。它指出生物大脑中存在能感知方向与位置的方向角和倾斜角的细胞。而在人工智能计算机视觉领域中,实际处理的图像和视频信息也都有方向和方位的变化性信息,它和人脑的背景相同。
在考虑方向性的工作中,我们建模了几何结构,设计具备方向性的多尺度张量滤波器。
这项工作在军用的产品中表现出很好的使用效果。

此外,我们还利用20多年前的多尺度几何理论,建立了新一代可分解重构的深度学习理论。我们不仅能构建层级的差分特征,也能使不同层级抽象层级的差分特征形成一种新的信号表示,成为一种新的深度分解的重构模型。上述这些工作都是基于多尺度几何与深度学习的研究历程和发展惯性展开的。
回顾起来,在90年代初我们便提出了多小波网络理论,然后提出小波SVM支持向量机,多尺度Ridgelet网络,再到最近的深度Contourlet网络。
我们将Countorlet的方向性、逼近能力和卷积神经网络相结合,从而形成新的工作达到较好的实验效果。这篇工作也被IEEE Transcations on Neural Networks And Learning System 20录用。
我们提出的Rigelet网络,也就是脊波网络,其自身可以将斑点及波正则化。我们将其与脊波网络相结合,在SAR图像的分类场景中达到了极佳结果。
我们还将突触结构进行了模型研究。突触是一种生理结构,其具有记忆和存储等多种功能,而这种功能目前没有得到完全的利用。我们主要的研究结果包括长时程增强和抑制,它们都是先有工作中鲜有体现的。
为了有效而高效的处理海量的数据,后深度学习时代的另一个问题是数据的自动学习和处理。
学习模式的演化经历了数十年的发展:从1960年代的浅层神经网络,到70年代的反向传播的发现、80年代的卷积网络,到1990、2000年左右的无监督、监督深度学习的卷土重来,直到现在的网络模型。回顾该演化历程我们发现,应该更加努力地研究自适应深度学习。
在自适应深度学习方面,我们还有很多难题和课题需要解决。这些问题在于,我们要在特征工程、特征学习、感知+决策和环境适应的基础上,让机器能够学会学习,学会适应环境,学会感知决策。我们不仅要让机器能够生成对抗、架构搜索和迁移学习,更要让模型能够自动学习,能够从结构上进行新的探索。
此图梳理了国际上的一些深度学习结构和能力上的工作。梳理这些工作的脉络后,我们可以发现,这些工作都是在解决深度学习中的一些基础性问题。当然,这也是在构建一些新的处理结构,包括知识与知识的有效利用,与边云端的有效结合。
尽管我们有了模型在结构上的发展概况,但自动学习仍旧面临了很大的挑战。尤其是在自动确定网络结构超参数上遇到了相当大的问题。在此问题上,很多人都陷入了超参工程这一领域中。但在我看来,这项工作并没有太多的科学思考,都是一些“码农调参”的常规工作。这是最低级、辛苦、低效且无意义的工作。神经网络的架构搜索NAS,是解放人力的一种新途径。我们现在的问题是如何针对需要解决的问题搜索到最佳的结构。
对于自适应神经树模型,我们采用了神经网络与决策树相结合方法进行组建。此工作最早是由UCL、帝国理工和微软的研究人员提出的。他们提出了一种雏形的自适应神经树模型ANT,它依赖于各种数据的模式。那么对于复杂、活的和变化的数据,应该如何设计一种自适应、快速、可微分、系统可通过BP进行训练的训练算法是一项挑战。
另一个问题是概率生成的确定性推理。在模型学习的过程中,很多时候需要“灵感“。记忆和学习永远是有效的、可逆的。这不仅是矛盾,更是矛盾的两面体。因此我们如何在模型学习的过程中利用这种关系呢?同样,在函数的逼近论下的架构搜索,我们提出深度泰勒分解网络来解决求导难的问题。它采用逐层拆解的方法来解决深度网络过于复杂从而无法求导的问题。
后深度学习——渐进演化
后深度学习时代面临的另一个问题是“渐进演化”。我们为什么会提出这个概念?这是因为我们从认知建模、自动学习,再到渐进演化,不仅是要对场景和设备的噪声、非线性变换等脆弱问题进行定位,更重要的是要解决面对海量、小样本的数据的复杂性所产生的问题。
渐进演化本质是受到了前文所述的人工智能、生物智能和计算智能的启发。我们希望网络能够进行充分的感知、全面的认知,进而进行感知和认知协同发展。渐进演化的基本观点是进行动态进化优化、学习时刻之间的相似性,最终进行领域适应的学习。
也就是将现在以梯度学习为基础的机器学习算法,和以自然演化的达尔文进化计算结合起来构造高效的算法。这便是渐进演化的基本含义。
人脑的感知和认知是进化和优化的核心。其中包括权重优化、结构优化、稀疏网络优化、网络剪枝方法。他们都依赖于传统梯度算法和演进计算的结合。因此,我们要在网络模型和学习算法的结合上考虑协同进化的优化。这是我们需要考虑的重要问题之一。我们也将深度学习算法部署到时FPGA系统当中,并且取得了非常好的效果。
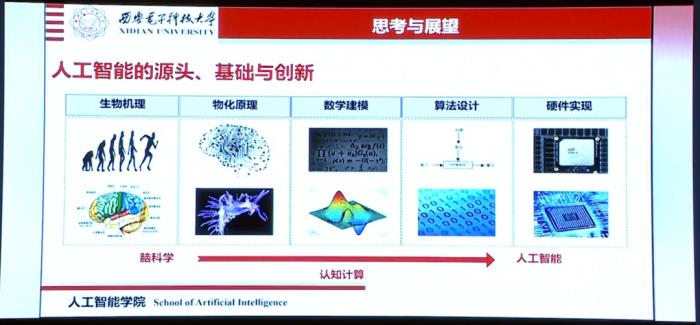
我们再次回过头来看人工智能的源头、基础和创新。这是一项需要从源头上突破卡脖子技术的研究方向,我们要将生物机理、物化机理、数学机理、算法设计和硬件环境结合起来,来实现从脑科学到认知计算,再最终到人工智能的良性闭环。
其实,深度学习和人工智能的发展也经历了类似的过程。脑科学的诺贝尔奖、人工智能的图灵奖和认知科学的诺贝尔奖的重要发展,都是人工智能发展的基础。
因此,脑科学、人工智能和认知科学的有机结合是人工智能下一阶段发展的重要方向。
从类脑感知到认知的人工智能,要求我们不光要对事情进行感知,更是要进行认知,而且需要学会思考、决策以及行动。这涉及到心理学、哲学、语言学、人类学、人工智能和神经科学等多种学科。
谢谢大家。

雷锋网雷锋网

相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










