

 新火种
2023-10-30
新火种
2023-10-30 


打破大模型的“空中城堡”,BMVC最佳论文Runner-Up得主谈多模态与具身学习
 两只新生猫的运动方式是否为主动,对视觉感知能力的影响非常大。这启发了人工智能中的具身学习范式,其中最关键的要素便是——主动。
两只新生猫的运动方式是否为主动,对视觉感知能力的影响非常大。这启发了人工智能中的具身学习范式,其中最关键的要素便是——主动。作者丨王晔
UC伯克利教授Jitendra Malik前段时间发文表示,虽然以大型语言模型(LLMs)为例的“基础模型”在机器翻译和语音识别等方面非常有用,但将这些模型称为 "基础模型",不禁让人怀疑这些模型是不是真的可以成为人工智能研究的基础。
并且,这种强烈的主张还有可能会被理解为:这些LLMs为所有的AI研究提供了一个模板。
Jitendra Malik教授认为,人工智能不一定要一味地模仿人类婴儿的发展过程,但是感知、互动、在4D世界中运动、获得常识性物理学模型、心智理论以及学习人类世界的语言显然已成为人工智能的重要组成部分。
他将这种缺乏感觉运动基础的、并且仅在“狭隘”的 AI 环境中展示了有效性的大型语言模型称作“空中城堡”。“它们是非常有用的城堡,但它们缺乏坚实的基础,仍然漂浮在空中,不太可能会创造出‘通用’的人工智能。”
类似的对“空中城堡”的批判不在少数,但很少有人通过行动来验证自己的观点。
就在不久前,BMVC最佳论文奖揭晓,由Rishabh Garg、高若涵和 Kristen Grauman共同发表的论文“Geometry-Aware Multi-Task Learning for Binaural Audio Generation from Video”获得了Best Paper Award Runner-Up。而该项研究,让我们再一次注意到了打破“空中城堡”的具体行动。
该论文一作为 Rishabh Garg,由高若涵博士以及Kristen Grauman教授共同指导。
AI科技评论有幸联系到了高若涵博士,就获奖论文以及他在打破“空中城堡”上的努力和展望进行了交流。
迈入多模态学习之路

进入德克萨斯大学后,高若涵首先接触了视觉信息处理的研究,后来又对声音信息处理感兴趣。在当时,该领域的模型普遍使用标记式的监督学习,这一点吸引了他的注意。
“这种人工标记方式存在多种局限性。首先,规模化使用需要极大的人力物力来进行标记;其次,由于是人为标记的,因此可能会带有主观性错误,这样获取的信息不够真实。”
所以,高若涵在那个时候就开始对自监督学习很感兴趣,一个想法在他脑海中浮现:AI能不能人类一样,主动地利用自己获取的数据的监督信息作为监督信号进行学习,而不是通过人工标记来学习?
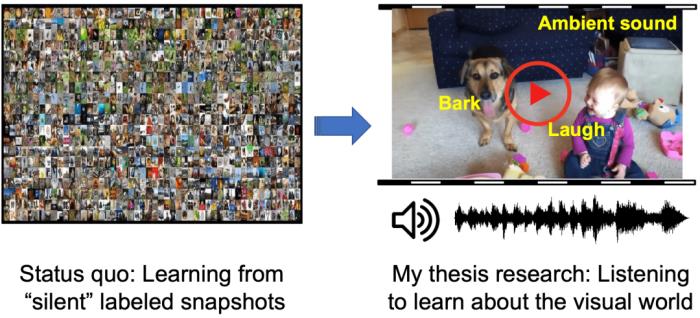
此后,高若涵对声音信息处理、多模态学习等课题进行了深入研究,在博士期间主要研究了声音的空间信息和语义信息。
提到得奖,高若涵讲到:“我是通过推特才知道我们得奖了,毕竟在虚拟会议中,大家没有足够的交流机会。”
得奖了都没注意到,那高博士他们在忙着研究什么呢?
多模态:声音空间信息的利用
人类平时是通过左右耳一起感知声音的,如果仅是听单声道的声音,就无法感知一些空间信息。
但在现实生活中,我们感受到的世界是3D立体的。比如,有一个人在说话,我们可以听出他是在我们的左边还是右边;有一辆车疾驰而过,我们也可以通过声音变化判断车的位置变化。“但是,我们平时看的很多视频中的声音都是单声道的。在这种情况下,我们感受不到立体空间,也就是丢失了一些空间信息。”
在发表于CVPR2019的论文“2.5D Visual Sound”中,高若涵及其团队将原始的单声道声音作为输入,然后分析视频中图像上的一些空间信息,将单声道的声音转化成双声道的声音。这项研究还获得了当年大会的最佳论文荣誉提名。

论文地址:https://arxiv.org/pdf/1812.04204.pdf
然而,在提取图片和视频中的空间信息时,他们采取的办法是把图片用ResNet-18提取出一个视觉特征向量(visual feature vector)来表示空间信息,然后指导从单声道到双声道的预测。“但是这个特征向量有一定局限性,它相当于是一个black box,我们无从知晓它是如何提取空间信息的。”
因此在BMVC2021上发表的这项获奖研究中,他们想更为直接地学习几何等空间上的信息,而不是单纯用一个空间向量从图片里直接提取。“我们根据三个想法设计了一个多任务框架,能够更好地学到一些空间特征,从而更好地做单声道到双声道的转化。”
三个任务“通过一个多任务学习的框架,我们不但要去做从单声道到双声道的转换和预测,还要能够利用视觉特征向量预测房间的脉冲响应(room pulse response)。”
论文地址:https://vision.cs.utexas.edu/projects/geometry-aware-binaural/
高若涵解释道,脉冲响应相当于是一个房间的迁移函数,包含了空间中关于声源的信息,其中包括声源位置、3D环境信息、照相机和麦克风的位置等。如果特征向量能够很好地提取空间的信息,它就能够很好的预测房间的脉冲响应。
脉冲响应只涉及一个损失函数,团队还提出了另外两个。一个和空间连贯性相关,可以让网络预测它最后生成的声音和视觉信息是否一致。
此外,在一个视频中,每帧画面是有一定连续性的,相邻的每个视频帧之间在空间信息上的变化非常小。因此,团队就利用了这样的监督信息,提出了另一个和几何一致性相关的损失函数,更好地学习了空间向量。

模型框架图:为了从单声道音频生成准确的双声道音频,视觉效果提供了可以与音频预测共同学习的重要线索。本文提出的方法通过三个任务的设置,来学习提取空间信息(例如,吉他手在左侧)、声源位置随时间的几何一致性,以及来自周围房间推断的双耳脉冲响应的线索。
数据集短缺
在人工智能研究项目中,数据短缺是常有的事情,特别是在探索新任务的时候。在BMVC2021的项目中,高若涵也遭遇了同样的难题。当然,这并不是第一次。
在“2.5D Visual Sound”项目中,高若涵就发现:缺少双声道的视频,或者声音数据集很小,没办法训练出mono-to-binaural的模型。
最终他们决定自己收集一个数据集,并模仿具身学习自主组装了一个收集数据的仪器。

“它有一个假人头,有像人耳朵形状的左耳和右耳,左右耳的间距大概也跟人类的间距差不多。它的耳朵里面还有麦克风,可以录声音,我们又在上面放了一个专业摄像机 ,模仿人的眼睛。然后,我们就邀请了一些志愿者到音乐室里面弹各种乐器,收集了一个数据集。”
团队利用了这个数据集训练出了模型,但还存在局限性,“收集这种数据集其实很难,我们最后也只收集了5个多小时的视频。”
在BMVC2021的项目中,此前收集的5个多小时的数据集已不足以支持继续研究。
“要解决数据集问题,要么我们就从现实生活自己收集,它的优点是很真实,但是这样收集成本很高。或者我们可以在一个虚拟模拟器上直接得到这样的数据集,但是可能会没有现实生活中那么真实。”
因此,高若涵和合作者们收集了一个虚拟数据集。“我们在一个虚拟环境里随意地放一些声源,还放了智能体,它在里面到处走动,然后进行搜集。我们录了一些视频下来,这样的数据大概能达到100多个小时,比之前的数据大了20多倍,这样就能够更好地帮助我们做算法的测试或者训练。”
多模态:声音语义信息的利用
“我们人不但能看还能听,如果看和听同时进行,那会让很多任务变得更加简单。”
上述研究中列举了高博士对声音空间信息的一些研究,而高博士的博士论文中除了研究声音的空间信息,还重点研究了声音的语义信息,探讨了如何同时利用声音和视觉更好地辅助学习视觉任务。那么如何理解声音的语义信息呢?
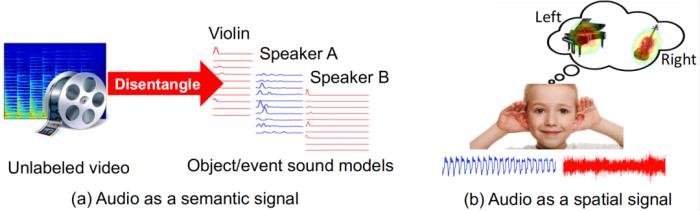
关于声音的语义信息,高博士研究过的声源分离(audio-visual source separation),就是一个典型例子。
他分享了一个著名现象——McGurk Effect,大概意思是视觉能够影响声音的感知。视频中人物发音是一样的,但由于人的嘴唇运动方式不相同,我们在看视频时所感知到的声音竟然不一样。这种效应有什么意义呢?高若涵解释到,“比如说在一个很嘈杂的环境里,我们的声音与其它声音有重叠,以至于听不到对方在说什么。那么怎么能把一个人的声音单独分离出来呢?或是在一个乐队演奏中,有人在弹钢琴,有人在拉小提琴,他们演奏出来的曲子是很多乐器声音的重叠结合,那么能不能把其中一种乐器的声音单独分离出来呢?”高若涵表示,此前已有一些研究直接基于声音信息进行分离,但难度很大。“如果是在一个视频里面,我们就可以利用视觉信息,比如嘴唇的运动,帮助分离出声源。”
这种思路可以联系到认知科学里面的“鸡尾酒会效应”,“我们在参加一个鸡尾酒宴会的时候,环境可能会很嘈杂,但是我们的注意力会很容易集中在与你进行谈话的那个人身上。同样,如果两个人在谈话,他们的声音可能是混在一起的,但如果通过结合人脸的视觉信息,就可以更好地将声音分离出来。”
高若涵的博士论文中也涉及了通过视觉信息进行声源分离,包括分离人说话的声音、乐器的声音,而这些就是对声音的语义信息的利用。
除此之外,在高若涵的“Listen to Look: Action Recognition by Previewing Audio”这篇论文中,他们还研究了“声音如何帮助动作识别”,这也是对声音语义信息的利用。
论文地址:https://vision.cs.utexas.edu/projects/listen_to_look/
“比如给我一个没有处理过的很长的视频,我们要预测里面的动作,比如滑水、滑雪等等。之前在计算机视觉领域,人们一般通过分析提取视觉特征来进行预测。但如果视频非常长,就需要很多的计算资源。”
所以高若涵想到:其实声音也可以告诉我们语义上的信息。
在一个很长的视频里面,可以通过动作的声音信息识别,把注意力集中到某一个片段里,然后跳到这个片段去进行视觉识别。这样就可以极大提高视频动作识别的效率。
简言之,视觉和听觉可以进行交互达到感知增益。而无论是视觉感知还是听觉感知,都根植于身体行动,经验建构于具身交互。身体及其与环境的交互对学习活动具有重要的意义和影响,多模态学习离不开具身理论支撑。
在具身环境下促进多模态交互
人类在感知世界时,并不是通过天天看视频来进行学习。婴儿在成长过程中也并不是一直看视频学习,而是通过具身学习,用自己的双耳、双眼和触摸等来感知这个世界,并基于反馈来学习技能。具身学习实际上也出现在高若涵研究的方方面面。
首先,他和合作者们研究过一个听觉-视觉-导航三者结合的AI算法。“就是让一个智能体比如机器人在一个空间里通过听觉和视觉信息来找东西。比如有一个电话铃响了,机器人通过声音和视觉的感知,巡航到声音发生的地点。”

论文地址:https://arxiv.org/pdf/2008.09622.pdf
具体而言,智能体学习多模态输入的编码以及模块化导航策略,以通过一系列动态生成的视听航点找到探测目标(例如,左上角房间的电话铃声)。例如,智能体首先在卧室里,听到电话铃响后,识别出它在另一个房间,并决定先离开卧室,然后它可以将电话位置缩小到餐厅,决定进入餐厅,然后找到电话。已有的分层导航方法依赖于启发式方法来确定子目标,而高若涵和合作者们提出的模型学习了一种策略来与导航任务联合设置航点。
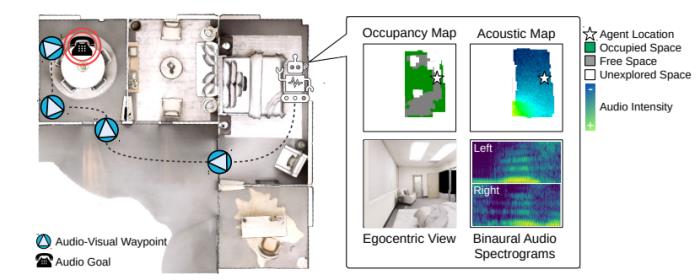
图注:视听导航的航点:给定以自我为中心的视听传感器输入(深度和双耳声音),智能体在新环境中移动时建立几何和声学地图(右上)。
此外,他研究的回声响应也与具身学习有关。一些动物像蝙蝠、海豚和鲸鱼,或者是视力受损的人类都具有非凡的回声定位能力,这是一种用于感知空间布局和定位世界上物体的生物声纳。

论文地址:https://vision.cs.utexas.edu/projects/visualEchoes/gao-eccv2020-visualechoes.pdf
在ECCV 2020年的论文“VisualEchoes: Spatial Image Representation Learning through Echolocation”中,他们在一个逼真的 3D 室内场景里,让机器人自己发出一些声音,得到此环境的回声。然后,他们设置了一个自监督学习的框架,通过回声定位学习有用的视觉特征表示,这些特征对于单目深度估计、表面法线估计和视觉导航等视觉任务很有帮助。
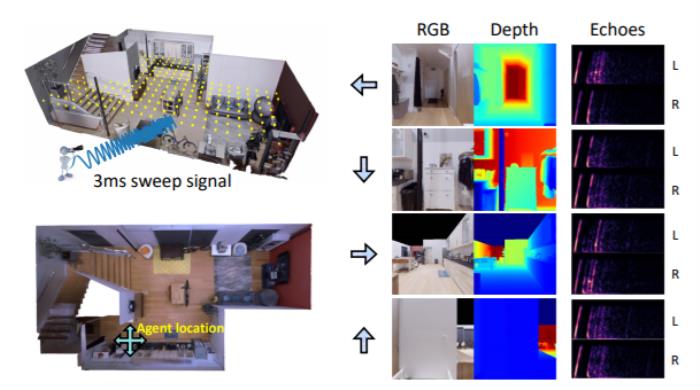
图注:真实世界扫描环境中的回声定位模拟。在训练期间,智能体会前往用黄点标记的密集采样位置。智能体主动发出 3 ms 全向扫描信号以获取房间的回声响应。
“除了听和看我们还可以触碰,触觉其实也是一种模态,同时也是具身学习的重要方面,很多时候我们都是通过触碰东西来感知世界的。”
因此,高若涵在最新的一篇文章“ObjectFolder: A Dataset of Objects with Implicit Visual, Auditory, and Tactile Representations”中,除了研究视觉、听觉,还延展到了另一种感官知觉——触觉。

论文链接:https://arxiv.org/pdf/2109.07991.pdf
高博士用盘子举了一个例子。从视觉上来讲,如果桌子上放了一个盘子,我们可以从各个方向来看它,受盘子形状、光源等影响,我们从各个方向看到的图像是不一样的。从听觉上来讲,如果桌子上有盘子,我们用小棒去敲打它,受材质、形状、大小等影响,我们听到的声音也是不同的。从触觉感知这个盘子,盘子的不同位置的形状不一样,我们用手指触碰的时候每个地方得到的感觉也是不一样的。因此,高若涵所在团队就想要建立一个基于三种感官知觉的数据集。
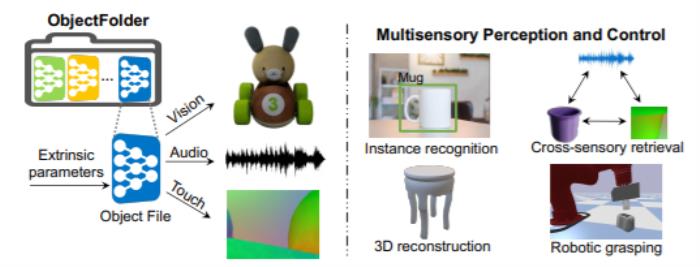
“之前其实有一些这样的3D物品数据集,但主要是与物体的形状有关,不涉及触觉、听觉信息,所以不够真实。在机器人领域也有类似数据集,只是规模很小。”
总而言之,要使用这种数据集需要考虑版本、成本等各种因素。因此,高若涵团队建立了一个有100个用神经网络隐式表示的物体的数据集。
“我们把这100个物体以一种多模态的方式进行表示。对于每一个物体,通过视觉观察获得图像,通过敲打等方式获得声音信息,通过触摸某一个点获得触觉信息。这个数据集可以帮助进行多模态学习的研究,并且应用在具身学习的研究中。”
在上述讨论中,高若涵重点分享了通过一系列基于多模态交互来改进感知效果的研究,包括声音的空间信息和语义信息理解,触觉信息的利用,并将具身学习融入到研究过程中,让智能体通过交互来获取数据,并同步地进行学习。这些进展都在反反复复强调:人并不是被动的感知外界的刺激,而是身体的多模态感知经验和外界刺激的交互以促进我们对概念的理解,要训练出更好的模型亦是如此。
以上成果都凝聚在高若涵的博士论文中,该论文后来还获得了2021 年 Michael H. Granof 大学最佳论文奖。该奖项由德克萨斯大学奥斯汀分校设立于 1979 年,旨在表彰出色的研究以及鼓励最高的研究、写作、学术水平。
论文地址:https://repositories.lib.utexas.edu/handle/2152/86943
多模态互补打破“空中城堡”
回到文章开头的问题,对于Jitendra Malik教授的观点,高若涵表示,“我的理解是,智能体不单是能够被动地感知这个世界,它需要自主运动,要和环境进行交互,才能更好地学习,这应该是未来智能体学习的一个发展方向。”问及该思想的科学依据或启发来源,高博士分享了一个实验:
1963年,心理学家Richard Held(1922-2016)和Alan Hein在“Movement-produced stimulation in the development of visually guided behavior”这项研究中进行了一个小猫“旋转木马”的实验,了解小猫是如何进行视觉学习的。于是,他们就设计了一个类似于旋转木马的装置,把两个小猫放在该装置的两边。
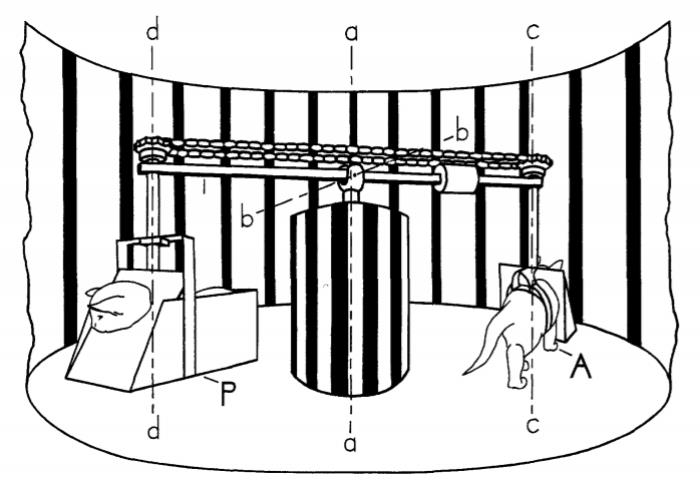
在小猫出生后的前八周内,它们被放在一个黑暗环境里面喂养。每一天,心理学家都把两只小猫同时拿出来放在该装置上。其中一只小猫可以把四肢展开运动,它迈腿的时候这个“旋转木马”就会旋转。而另一只小猫则无法和这个装置互动,它被包裹在盒子里,无法展开四肢。
而第一只小猫有了动作使该装置旋转起来后,另一只小猫也必须跟着被动旋转。在这种设置下,它们得到了同样的视觉信息。但主动的小猫的动作可以使环境改变,它的动作能够和视觉信息相关联。而另一只被动的小猫虽然接收到同样的视觉信息,但它的动作与视觉没有关联。
八周后,他们发现主动的小猫的视觉感知能力与正常情况下长大的小猫是差不多的,但是被动的小猫就有一些根本性的视觉感知问题。
所以他们得到的结论是,我们需要自主运动,来养成获取视觉信息的能力,这样才能够帮助我们更好地学习。
“这与具身学习非常相关。我们在感知世界时,是与世界进行交互。我们可以通过移动,看到不同的东西,听到不同的东西,感知到不同的信息。而这与我们主动的运动相关联,从而可以使我们更好地学习。所以也是为什么说自监督和强化学习的结合更加接近具身学习范式,我们需要的是主动与环境进行交互。而互补的多模态信号可以作为很好的自监督学习的信号,帮助我们更有效率地学习。”
回到我们自己身上或者婴儿身上,一个婴儿从出生起,并不只是通过看一堆图片或视频学习的。“我们不是被动地学习世界,而是通过主动地看、听、触、嗅等获取各种模态信息进行学习。”
通过这样的观察,高若涵表示,他的长期研究目标是将来能够建立多模态感知智能体,它不但能够听、看、触碰,甚至还可以使用嗅觉、感知热量,像人一样能通过学习多模态信息,更好地辅助人类。
总结
高若涵表示,“提出一个问题比解决一个问题更重要。”我们在用“基础模型”解决问题的同时,是否应该提出这种模型存在的问题,并想办法突破“基础模型”的限制?
就像Jitendra Malik教授所说的那样,我们过度投资于当前的范式,而对智力领域中某些被忽视的部分存在的风险没有足够的警惕。“大型语言模型是有用的,像谷歌、脸书或微软这样的大型技术公司对其进行投资是很有意义的,但学术界应该奉行‘百花齐放’的策略。”
智能出现在智能体与环境的相互作用中,并且是感觉运动活动的结果。未来的监督学习应该采用来自现实的监督信息,自监督和强化学习的结合更加接近这种范式, 多模态学习为这种范式提供了一个新的思路和方向。
谁又能知道下一个AlexNet时刻会在何时何地发生?
参考资料:https://crfm.stanford.edu/commentary/2021/10/18/malik.html

相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










