

 新火种
2023-10-29
新火种
2023-10-29 


斯隆奖新晋得主宋舒然:从视觉出发,打造机器人之「眼」
「我一直希望家里有一个机器人,可以帮我洗衣服、做饭。」
宋舒然谈道。而要实现这一设想,机器人视觉研究是不可缺少的一环。
近年来,计算机视觉与机器人的「联姻」在人工智能领域如火如荼。单就自动驾驶来看,就有许多研究人员拥有计算机视觉的学科背景,比如阿里达摩院自动驾驶实验室的前负责人王刚,中国RoboTaxi领先企业AutoX(安途)的创始人肖健雄等等。
从算法架构来看,计算机视觉的研究潜力或已「穷途末路」;但在机器人的应用中,人们普遍相信,计算机视觉仍大有可为。设计出优秀的算法,让机器人系统能在与物理世界的交互中学习、自主获得执行复杂任务和协助人类的感知和操纵技能,是新一代计算机视觉研究者的主要目标之一,宋舒然也是该赛道上的一员。
作为一名「CVer」,宋舒然为何会转向机器人领域?她在该领域的研究故事又是怎样的?计算机视觉与机器人系统如何互动?针对这些问题,我们与宋舒然聊了聊。
1、与机器人视觉的首次「邂逅」
不久前,2022年斯隆研究奖公布,计算机领域有四位华人女性科学家入选,宋舒然便是其中之一,名噪一时。
斯隆研究奖被誉为「诺贝尔风向标」,主要授予被认为在各自领域最有潜力的青年科学家,以往获得该荣誉的人工智能学者均非同凡响,如AI科技评论往期报道过的鬲融、马腾宇、方飞等等。宋舒然能成功当选,实力可见一斑。
但这并不是宋舒然第一次被「看见」。此前,她与团队已在多个国际机器人顶会上获得最佳论文奖,包括RSS 2019最佳系统论文奖、CoRL 2021最佳系统论文奖,以及2020年《IEEE Transactions on Robotics》最佳论文奖,是近年来「机器人视觉」赛道最知名的青年代表人物之一。
更令人钦佩的是,此时距离她博士毕业后进入学术界才不过四年时间。
目前宋舒然在哥伦比亚大学计算机系担任助理教授,主要研究计算机视觉与机器人技术的交叉领域,如开发能使机器人系统在与物理世界的交互中学习、并自主获得执行复杂任务和协助人们的感知和操纵技能的算法。
回顾自己的研究经历,宋舒然对AI科技评论谈道,她第一次对机器人感兴趣,是在大一时上的第一门基础课上:
「那是我第一次接触到机器人。这门课没有教特别多的专业知识,就是一门动手操作的课,做一辆小车、最后让小车成功地跑起来,过程很简单,编程也很简单,但整个过程中有很多意想不到的惊喜,对我影响非常大。」
于是后来,在学校的机器人社团来招新时,宋舒然毫不犹豫就报名了。也是在参加机器人社团的过程中,她有机会在本科阶段就接触到了计算机视觉的知识。

图注:香港科技大学
宋舒然的本科就读于香港科技大学电子与计算机工程专业(ECE)。
作为一名土生土长的北京人,2008年奥运会加速了北京发展的国际化,年少的宋舒然对探索世界有着极高的热情。所以2009年她在高考前夕填写大学志愿时,除了北京大学的医学院,还报考了香港科技大学的计算机专业:
「我们那时候还是在高考前报志愿。一是报考香港的大学不占志愿名额,二是我当时就打算未来要出国走一走。相比直接就去英国、美国读书,香港是一个比较折中的选择。」
宋舒然自幼是一个擅长学习的学生,在重要的考试中总能发挥超常。出于对自我学习能力的自信,在报考大学志愿时,她也专门挑选了学习难度较高的专业。即使当时的编程基础几乎为零,在填写计算机为志愿专业时,她也没有任何犹豫。
也正是这股子无所畏惧的劲,让宋舒然在一个男性占大多数的领域中也能披襟斩棘、所向披靡。
2009年,宋舒然从北京南下,来到香港这座以国际化著称的城市。刚到港科大不久,她就明显地感觉到多元化的校园环境:
「高中时感觉周围的同学想要做的事情都差不多。到了香港后,发现大家想要实现的人生都很不一样。大家学不同的专业,有些人注重社交,有些人会提前规划职业发展,像我这样喜欢做研究的学生反而不多,所以我在本科时的科研机会也更多。」
大学期间,宋舒然有幸参加香港科技大学机器人社团(HKUST Robotics Team),还在2011年代表社团参加了一年一度的国际性机器人比赛——ABU Robocon。那一年,宋舒然与团队赢得了香港地区的选拔赛,代表香港去泰国参加决赛。
「印象中,当时机器人的研究里面,最难的也是计算机视觉的部分。虽然我的专业不是计算机视觉,但我在那个过程中也学到了不少知识,比如视觉追踪与检测。」宋舒然回忆道。
除了参加机器人社团,宋舒然还在大三那年(2012年)参加了香港科技大学与美国麻省理工学院(MIT)的暑期交换生项目。「那一年是第一届,申请的人并不多,所以我就非常幸运地得到了这个机会。」
虽然只有短短一个暑假,交换期间参与研究的内容也十分基础,但整个过程给宋舒然留下了深刻的印象。
宋舒然记得,当时她每天都会去MIT CSAIL的大楼,每天在路上都能遇到形形色色的人。在这栋形状奇特的大楼里,有很多做机器人研究的人,她每天都可以在大楼里看到各种各样奇怪的机器人,「研究者不停地调试着什么」,整个研究氛围非常活跃。
当时她的指导老师是图形学领域的大神 Frédo Durand。宋舒然记得,虽然 Frédo 是一名非常有名、事物繁多的教授,但还是会不厌其烦地腾出教研时间指导交换生们学习目标课程,与他们固定时间开会、解答疑问。在这个过程中,宋舒然也学到了许多图像视觉的知识。
原先宋舒然只是对研究感兴趣,但这次赴MIT交换的经历使她下定了读博的决心:
「刚上大学时我并没有想好之后要读博,或者在学术领域有多大的发展。但到了MIT,认识的学生都是PhD,他们做的研究非常有意思,做研究的过程感觉非常振奋,让我开始觉得我好像也很想去做研究。」
2、请回答2015:突破3D视觉
2013年,宋舒然加入普林斯顿大学的计算机视觉与机器人实验室(计算机视觉领域的知名华人学者邓嘉也在共同领导该实验室)攻读博士,先后师从肖健雄(2016年离开普林斯顿去创业)与Thomas Funkhouser。据悉,Thomas Funkhouser每年均只招收1-2名博士生。

图注:普林斯顿大学
普林斯顿大学最吸引宋舒然的一点是它较小的实验室规模,和与之带来的能与教授进行更多交流的机会。
读博期间,宋舒然的研究内容聚焦在计算机视觉。虽然本科时做过物体追踪项目,但宋舒然回忆,在刚开始读博时,她的视觉基础是相对薄弱的。
在导师的指导下,她延续本科时期的学习,先是研究3D物体检测与追踪。当时恰逢微软推出一个新的3D感知相机(Kinect 3D Camera Sensor-System),他们便思考是否能用这些新设备,将2D物体检测延伸到3D物体追踪。

图注:微软在2013年推出的Kinect 3D相机感知系统
2014年前后,计算机视觉领域的一个重要研究方向就是2.5D到3D的物体识别与检测追踪。宋舒然从2013年开始研究,恰好赶上了这一热潮,加上个人的后天努力,她的博士生涯也因而比大多数人的成长要迅速得多。
2015年是宋舒然在计算机视觉研究上的「丰收年」。那一年,她在计算机视觉顶会上发表了4篇高引论文,篇篇经典,而彼时距离她入学博士才不过两年时间:
3d shapenets: A deep representation for volumetric shapes(谷歌学术引用3500+)
Shapenet: An information-rich 3d model repository(谷歌学术引用2500+)
Sun rgb-d: A rgb-d scene understanding benchmark suite(谷歌学术引用1100+)
Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop(谷歌学术引用1000+)
宋舒然对AI科技评论介绍,她第一次接触深度学习是在“3D ShapeNets: A Deep Representation for Volumetric Shapes”这篇工作中,经汤晓鸥与吴志荣的带领入门。当时,就读于香港中文大学的吴志荣到普林斯顿交换,宋舒然与他由此结识。
「那时候深度学习还没有那么火。2D视觉开始火起来,但把深度学习用于3D视觉的研究还几乎没有。我当时完全没有做过深度学习的研究,只是做过一些比较传统的2D识别与检测。因为志荣在汤晓鸥的组里做了很多深度学习的研究,所以我们就把他拉过来一起合作。」宋舒然回忆道。
开辟性的工作往往艰难重重。宋舒然记得,当时他们在合作的过程中遇到了很多困难,其中最大的困难是没有成熟的机器学习库或框架去支持深度学习系统的搭建,「只有贾扬青提出的Caffe,而且比较初期的Caffe并不支持计算机视觉的操作」。
所以他们当时的研究重点就放在了如何开发系统、将2D算法转化为可以接受3D数据上。他们当时的想法其实非常简单–从2D pixel 表征方式转化成 3D voxel 的表征方式。虽然现在看来这个方法有很多明显的缺陷(需要大量的显存空间), 但好处是可以沿用很多传统的2D 算法,比如卷积。
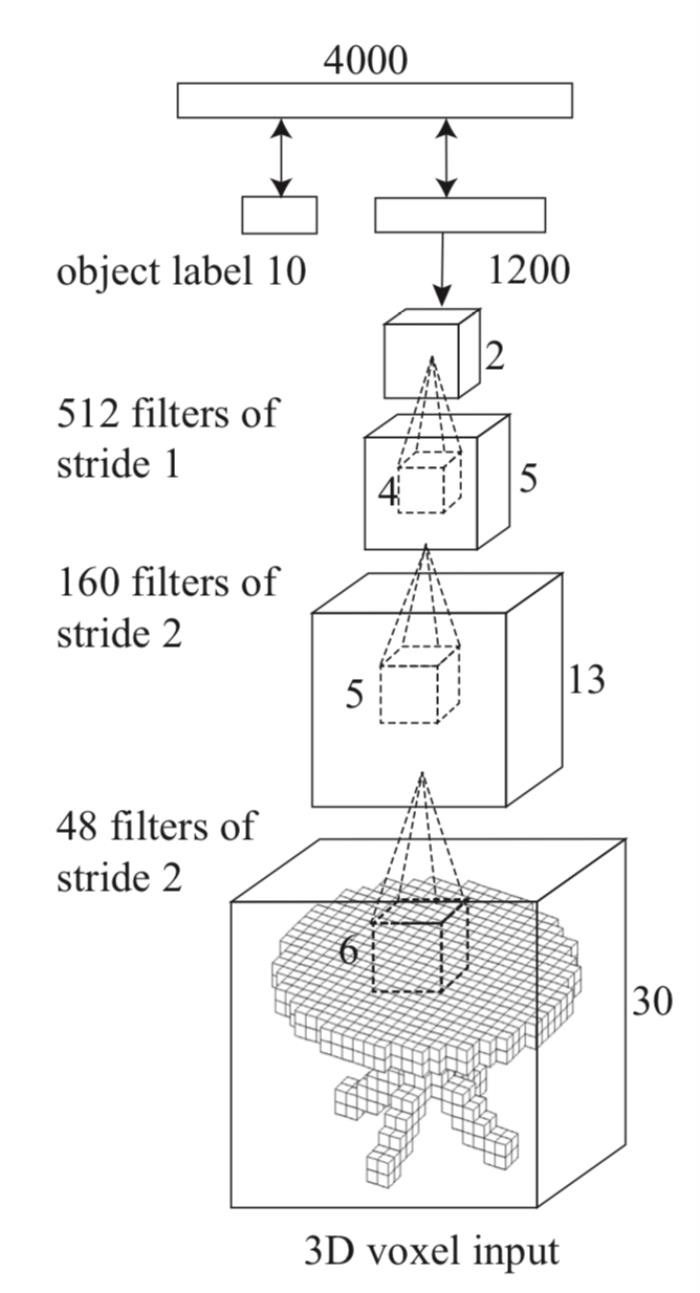
图注:3D ShapeNets(2015)的转换原理
这是第一个成功通过深度学习方法将2.5D延伸到3D上的视觉工作。在此之前,深度学习多用在2D图像或自然语言处理上。「3D ShapeNets」首次展示了深度学习系统如何学习形状表征的过程,且通用性强,可以应用在多个不同的任务上,在计算机视觉领域产生了深远的影响。
对于宋舒然来说,这个工作既是她研究生涯中的一个里程碑,也是启发她在研究中采用「简单而高效」的方法论的起点:
「它很简单,但非常高效,唯一的限制是对算力的需求加大,因为数据的维度提升,计算量也会随之增长。此外,这是我第一次研究3D,我之后的许多工作都延续了这个项目的idea(观点),即用3D深度学习系统做形状表征。」
凭借在计算机视觉方向(尤其是数据驱动的3D场景理解)的一系列出色工作,宋舒然获得2015年Facebook博士生奖学金。她的工作登上普林斯顿研究校刊,还入选了「普林斯顿25岁以下创新25人」。

图注:宋舒然在普林斯顿读博期间
3、从视觉到机器人
机器人对现实世界的感知准确率依赖于视觉中的3D语义场景完成技术。宋舒然在3D视觉上的研究突破奠定了她从事机器人视觉研究的基础。
从2016年提出「Deep Sliding Shapes」后,她就开始在研究视觉之余探索如何用3D视觉提高机器人推理周围环境的物体的能力。彼时,计算机视觉正越来越多地从分析单个静止图像转向理解视频和空间数据,对机器人的智能提升是一大利好。

图注:宋舒然在普林斯顿大学研究的机器人(“Robot In a Room: Toward Perfect Object Recognition in Closed Environments”)
想象一下,如果一个机器人要打扫房间,那么它既需要有空间导航能力、知道移动到哪里,也需要识别出房间中的不同物体,才可以执行扫地、收拾、整理等任务。
这时,机器人就需要理解两个层级的信息:第一层级是帮助机器人与周围环境互动,可以识别移动的开放空间,并定位要操作的物体对象;第二层级及以上的信息则使机器人了解一个物体是什么,并使用该物体来执行任务。
在这个问题上,以往的研究趋于将两者分开,划分为「场景完成」与「对象标记」。但2017年,宋舒然与团队提出了「SSCNet」系统,通过从单个2D图像生成场景的完整3D表示与场景对象的标记,将两者结合起来,取得了更佳的算法效果。
尽管仍是从3D视觉出发,但这项工作预示了宋舒然之后在研究机器人视觉上的一个重要理念:机器人通过与现实世界的互动中了解世界。比如,即使一个房间里的椅子视线部分被桌子挡住,但如果机器人能够将其对椅子形状的基本识别与房间布局相结合,那么它也能判断桌子旁边的形状是椅子。这类预测的准确率会大幅度提升。
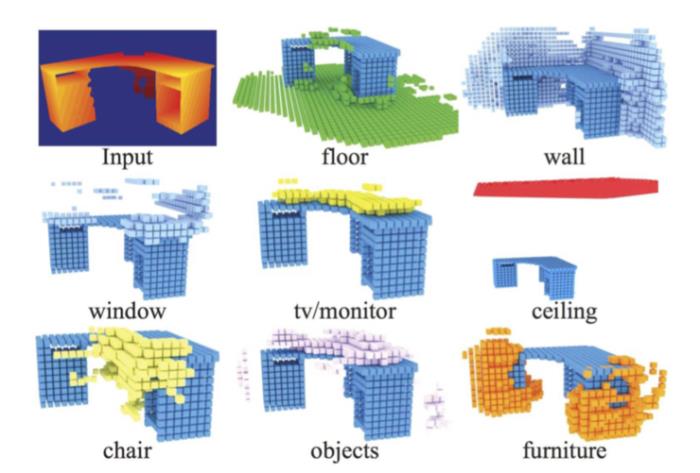
图注:在「SSCNet」中,只需要输入「桌子」的图像,就可以预测桌子周围的物体摆放
在3D物体检测与追踪上做了许多工作后,2017年,宋舒然与MIT的机器人团队合作,一起参加了亚马逊机器人挑战赛——Amazon Picking Challenge,开始尝试视觉与机器人的「软硬结合」。
「我们最开始合作的想法非常简单。他们是做机器人的,我们是做视觉的,我们把两边的系统合起来就可以去参加比赛。我们第一年也确实是这么做的。」宋舒然对AI科技评论讲道。
不过,这种「粗鲁搭配」的做法并没有取得很好的效果。
2017年,他们合作的方式是:由宋舒然的计算机视觉组先定义一个要输出的算法结果(如物体姿势),然后再由MIT的机器人组通过视觉输出的算法去做动作规划(motion planning),计算机器人如何可以抓取目标物体。
但这次的合作并不高效。普林斯顿与MIT位于不同的城市,两个团队之间的交流主要是通过邮件传代码,宋舒然团队的视觉算法过了一个月后才放在MIT的机器人上试验。
在试验的过程中,他们也发现了许多问题,比如:宋舒然团队所提出的视觉算法非常慢,导致整个系统也很慢;可用于训练的标注数据极其有限,模型跑不起来;算法精度不够,对于计算机视觉来说,误差在5度5厘米以内的算法精度已是效果极佳,但当这个误差被真正应用在机器人操作上时,却可能造成整个机器人环境的崩溃。
所以,2017年的比赛中,他们只取得了第三名的成绩。但是,这次的合作也激起了宋舒然对机器人视觉的研究热情,他们发现了许多有意思的问题,激发了许多提升系统的想法,于是决定继续合作参加2018年的比赛。

图注:MIT-Princeton 团队在亚马逊机器人竞赛(2018)
这一次,宋舒然和整个团队对物体姿态的算法进行了重新整合,不再使用中间的物体姿态作预测,而是直接从图像出发去预测机器人应该采取怎样的动作。如此一来,整个算法系统的速度有了大幅提升,而且更加通用。
亚马逊挑战赛的内容是:机器人要从一个装了各种物体的盒子里挑选出目标物体。这时,盒子里的物体之间可能彼此遮挡,会挡住机器人的视线。
针对这个问题,宋舒然团队摈弃了之前「先识别物体」的步骤,而是设为「先抓取物体」,把物体先取出来再识别。这时,机器人只需要知道物体的哪个部位更易抓取,而无需判断物体是什么,系统的鲁棒性也大大加强了。
在改进算法后,他们的机器人抓取速度快速提升,获得了2018年亚马逊抓取机器人挑战赛的冠军,还获得2018年亚马逊最佳操作系统论文奖。
自此,宋舒然也正式踏上了用计算机视觉帮助机器人感知物理世界、与物理世界交互的研究道路。
4、简单,但高效
2018年,宋舒然从普林斯顿大学获得计算机博士学位,后加入哥伦比亚大学计算机系担任助理教授。问及为何选择哥大,她给出的理由是:
「我选择哥大的一个重要原因是地理位置。我还是喜欢待在城市里。我是在北京长大的,然后去了香港读大学。去了普林斯顿后,我就发现我不适合在一个小镇子里生活,所以我就想回到大城市,就选了哥大,因为它在纽约。」

图注:哥伦比亚大学
担任教职后,宋舒然在机器人视觉的研究上屡出成果,三年内接连拿下RSS 2019最佳系统论文奖、T-RO 2020最佳论文奖、CoRL 2021最佳系统论文奖,相关工作还获得了IROS 2018、RSS 2019、CVPR 2019、ICRA 2020等顶级会议的最佳论文提名。
2018年,宋舒然团队延续亚马逊挑战赛的思路,进一步研究机器人在「推」与「抓」两个动作上的协同。尽管强化学习在当时很火,但宋舒然的这个工作首次在机器人视觉研究中直接引入了强化学习方法,并获得了IROS 2018最佳感知机器人论文奖提名。

图注:该感知机器人先「推开」物体,再「抓取」物体
「当时我们的最终目标是能把物体抓起来。『抓』这个动作很好评估,只要能抓起来就是positive reward(正向奖励)。但『推』这个动作很难评估,什么样的『推』才算是好的『推』?所以我们就采用强化学习方法,提供一个好的评估函数去定义『推』,最后只需要编写一个最终奖励(即推的动作能帮助抓取物体)即可。」宋舒然向AI科技评论解释道。
据宋舒然介绍,在她与团队「凭直觉」做这个项目之前,大多数人都认为强化学习方法需要大量的数据,所以很难在真实的机器人上直接训练。即使到现在,强化学习被应用于机器人的方法也不是主流,宋舒然与团队也没想到「真的能跑起来」,可以说打破了不可为的魔咒、给予了该方向的研究者以莫大的信心。
宋舒然在机器人视觉系统上的第一个里程碑工作当属获得RSS 2019最佳系统论文奖的「TossingBot」。在这个工作中,他们与谷歌的研究团队合作,最终成果登上了《纽约时报》商业板块的封面。

图注:TossingBot登上《纽约时报》商业版封面
这个投掷机器人的「绝杀技」是可以学习快速准确地捡起任意物体,并将其扔到附近的目标框中。研究者认为,投掷是一种利用动力学来提高机械手能力的绝佳方法。例如,「在拾取与放置的例子中,投掷可以使机械臂快速地将物体放入其最大运动范围之外的选定盒子中,从而提高其可接触的物理范围和拾取速度。」
这个工作背后的关键思想是「残差物理学」(Residual Physics),可以将简单的物理学与深度学习相结合,使系统能够从试错中快速训练、并泛化到新的场景中。
物理学提供了世界如何运作的先验模型,宋舒然与团队可以利用这些模型开发初始控制器。比如,在投掷中,他们可以使用弹道学来估计使物体降落在目标位置所需的投掷速度,同时使用神经网络在物理估计之上预测调整,以补偿未知动态以及现实世界的噪声和可变性。
作为一名计算机视觉专业的「科班生」,宋舒然每研究一个项目,便愈发为视觉与机器人的交叉结合所能产生的神奇效果惊讶。TossingBot的工作发表后,她在接受《纽约时报》的采访时惊叹道:「It is learning more complicated things than I could ever think about.(机器人正在学习更复杂的事情,这是我以前没有想过的。)」
不过,这显然不是终点。「TossingBot」发表两年后,宋舒然又挑战了机器人在高速动态动作上的新高度。她带领她在哥大的第一位博士生Huy Ha,又凭借另一个机器人「FlingBot」拿下了第二个最佳系统论文奖——CoRL 2021最佳系统论文奖。
当时CoRL 2021的评选委员会对「FlingBot」这项工作给出了极高的评价:「这篇论文是我见过的迄今为止对模拟和现实世界布料操作方面的最了不起的工作。」

论文地址:https://arxiv.org/pdf/2105.03655.pdf
「FlingBot」挑战的任务是布料处理,迁移到日常生活中,就是常见的铺床单、铺被子等等。此前,针对这项任务的大多数工作是使用单臂准静态动作来操作布料,但这需要大量的交互来挑战初始布料配置,并严格限制了机器人可及范围的最大布料尺寸。
于是,宋舒然与学生使用了自监督学习框架FlingBot,从视觉观察出发设置双臂操作,对织物使用拾取、拉伸并抛掷的初始配置。实验表明,FlingBot的3个动作组合可以覆盖80%以上的布料面积,超过静态基线的面积4倍以上。

图注:FlingBot
听起来是不是很简单?
「算法确实不难,所以这篇工作还被RSS拒过,理由是方法过于『trivial』。」宋舒然笑道。
他们一开始的想法很简单:当时他们看了许多文献,所有工作都是采用拾取、放置,这与人们在日常生活中的习惯十分不同。「举一个非常简单的例子,就是早上铺床。我们不可能小心翼翼地去做『pick up-place』(拾取-放置),我们铺床单一般就是一扔,抛开后再把床单铺开,但没有机器人系统是这样做的。」
所以他们就思考,是否可以让机器人采用一些扔高、展开的动作,如抛开。最后做出系统时,他们也发现,整个系统确实非常简单,只需分解成三步:第一步是抓布料,第二步是把布料展开,第三步是「扔」开布料。而「展开」与「扔」这两个动作基本不需要学习,因为学与不学的区别不大,真正要学的只有「抓」这一步,因为如何抓会直接影响后面的「展开」与「扔」。
虽然他们在「抓」这一步上也突破了传统算法,但整体而言,「FlingBot」的整个系统是比较简单的。所以在第一次提交论文时,评审们就将论文拒了,理由均是:结果很了不起,系统也很了不起,但算法非常简单。
这时候宋舒然的反向思维又来了:在第二次提交时,他们就在论文中强调了「简单但高效」的亮点——
「用一个简单的算法就可以解决一个这么复杂的任务,难道不是好过你去设计一个非常复杂的系统吗?而且它的效果非常好,恰恰证明了它在高速动态动作上的效率。」
这与她在博士期间与汤晓鸥等人合作3D ShapeNets的研究思想是一脉相承的:简单,但高效。后来,FlingBot 果然被 CoRL 接收,还获得了最佳系统论文奖。
5、一些思考
这时想必大家都已发现,与在结构性环境中的机器人(如亚马逊工厂的产线机器人)相比,宋舒然的机器人工作,无论是「TossingBot」还是「FlingBot」,都需要先对物理环境进行感知,掌握环境信息,然后执行适应环境的动作。
「在工厂或仓库中,机器人每天遇到的物体、物体位置与物体类别高度相似,在这类场景下,机器人的感知与规划已经达到非常成熟的状态。很多工厂的流水线上都安置了自动化机器人。但如果你仔细观察,这些机器人大多是没有『视觉』的,它们只是在记忆特定的动作,然后重复同样的动作,所以它们不能照搬到一个新的环境。」
因此,宋舒然认为,如何让机器人去适应非结构化的环境,是机器人视觉接下来的关键研究方向。在她的研究中,无论是从对人的观察中学习机器人的进化经验,还是强调机器人与现实世界的交互,都是在为这个方向努力。
比如,在FlingBot中,为什么会用「扔」的动作去展开物体呢?宋舒然解释:「如果物体被展开,是更容易被识别的。如果衣物揉成一团,不展开的话你根本不知道是T恤还是裤子。」从这个角度来看,机器人与物理世界的交互也有利于提升感知的准确性。
换言之,在视觉与机器人的联姻中,不仅是视觉帮助机器人感知,反过来,机器人的动作也会增加视觉的感知。
6、探讨「通用人工智能」
AI科技评论:Yann LeCun 之前一直强调自监督学习是下一代人工智能的重要方向,老师您怎么看?
宋舒然:我非常同意。我觉得的确是的。现在我们已经在监督学习上取得了很多的进展,包括ImageNet和现有的许多Benchmark(基准),下一步如果我们想用上更大的数据集,其实很难再标注更多的数据了。我们需要的是在算法上的提高,就是如何去利用这些没有标注的数据。
在这个方向上,不同的领域有不同的定义方法。如何去定义自监督学习?我觉得这是最核心的问题。在计算机视觉领域,你可以做视频预测;在自然语言处理方向,你可以做语言计算。我一直在想的是,在机器人领域,如何定义自监督学习?如何去定义一个统一框架可以去做自主自监督学习?
AI科技评论:而且之前很多人在强调这个方向的时候,好像都没有提到跟现实的交互。
宋舒然:对的,因为它的成本的确比较高。如果你没有机器人,你需要买一个机器人。而且就算是有机器人,通过交互去收集数据,感觉上是要比标注数据慢很多的。但这并不代表它没有前景;相反,我觉得这是一个更有潜力的方向。
尤其是,如果你考虑未来的人工智能发展,当机器人不再是一个昂贵的设备,当机器人的标价降低、遍布各地,并且可以执行很多任务时,我觉得通过交互的自监督学习会变成更主流的方法。
AI科技评论:明白。老师您可否再总结一下,这种交互加自监督学习的学习方式,过去的发展、当前存在的瓶颈和未来趋势是什么?
宋舒然:目前「自监督+交互」的方式里仍然掺杂了许多人为经验。我们现在的许多工作,比如我们可以用自监督的方式做「抓取」,原因是我们可以很好地计算这个物体是不是被抓起来了。对于「展开」这个动作也是一样的。我们可以通过物体的表面、面积有没有展开作为一个监督的信息。但是这些奖励虽然是自监督,可以直接从图像里计算,但它也是由人来定义的,是经验告诉我们可以得到这样的信息。
而且我觉得在任何一个算法里,如果必须由一个人类工程师去定义事情的话,往往会成为一个瓶颈。所以展望未来,我们如何去减少这种人为的经验?是不是可以通过学一个未来预测模型,或者学一个比较通用的世界模型,然后用一种比较统一的方式去看,或者比较直觉的方式去设计?而不是我们需要去对每一个任务特定设计世界模型。我觉得这个可能是将来比较有意思的发展方向。
AI科技评论:目前对于通用人工智能的实现,您有没有一些理解和设想?
宋舒然:我觉得我没有很清晰的理解和设想(笑)。通用人工智能是最终目标,但我们的确还有很大的距离。很多想法是有意思的,但以我现在有限的理解,还是需要很长时间的发展,很难说哪个方向是更有前景的,或更有意义的。
但我觉得学习嵌入式智能是非常关键的一步,因为我觉得通用人工智能不只是理解网络信息,不只是理解图像或抽象数据,还需要理解物理、理解3D环境。
AI科技评论:就是先不说通用人工智能是什么样子,但是要增进我们对通用人工智能的理解的话,我们不能局限于当前已有的这些任务,而是要去不断探索新的任务是吗?
宋舒然:对的,而且不能只考虑对机器学习模型进行抽象,还要考虑如果你要构建一个「物理分身」(physical embodiment),比如机器人,它是可以在现实的物理世界中去与不同的物体互动的。
不说人工智能,只是说我们(人类)的智能。其实我们学到了很多智能,但不只是通过网络,不只是通过读书、看图片或看视频,很大一部分的智能是在交互中学习的,比如怎么走路,怎么拿起物体。
所以我的一个理解是,实现通用人工智能,机器人或嵌入式智能是非常重要的一步。
注:琰琰、青暮对本文亦有贡献。
参考链接:
1. https://www.researchgate.net/figure/The-Microsoft-Kinect-3D-Camera-Sensor-System-an-IR-transmitter-3D-Depth-Sensors_fig15_309740491
2. https://www.cs.princeton.edu/news/andy-zeng-shuran-song-win-best-systems-paper-award
3. https://www.cs.princeton.edu/news/article/shuran-song-wins-facebook-fellowship
4. https://www.cs.princeton.edu/news/deep-learning-improves-robotic-vision
5. https://www.cs.princeton.edu/news/scene-completing-system-may-show-robots-what-theyre-missing
6. http://arc.cs.princeton.edu/

相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










