

 新火种
2025-03-14
新火种
2025-03-14 


科研领域新成果:九章云极DataCanvas联合团队发布R1复现以及改进技术
近日,中国人民大学STILL项目团队、北京智源研究院团队联合九章云极DataCanvas公司在大模型慢思考推理技术上形成系列技术成果,初步复现类R1推理模型,完整开源了类R1类的实现细节以及训练技巧。进一步,创新性提出使用代码工具来增强模型推理性能,在AIME数学推理测试中超越DeepSeek-R1的模型性能。相关成果已经形成论文《An Empirical Study on Eliciting and Improving R1-like Reasoning Models》,在预印版论文网站 arXiv上公开发表。
九章云极DataCanvas联合研究团队公布了复现DeepSeek- R1全参数微调开源方案,并发布了全新的强化学习训练模型STILL-3-Tool-32B。这个方案完整开放了从模型训练到推理部署的全链路工程代码,同步公开实践验证过的技术经验与调优策略,为开发者提供可直接部署的工业化级大模型训练框架。研究成果显示,该模型在 AIME 2024 基准上取得了81.70%准确率(采样),超越了DeepSeek-R1满血版。该成果在GitHub社区中详细阐述,并公开了相关开源链接。

论文地址:https://arxiv.org/pdf/2503.04548
开源链接:https://github.com/RUCAIBox/Slow_Thinking_with_LLMs
STILL-3-Tool-32B模型是九章云极DataCanvas联合团队在基于长链复杂推理模型训练框架上的又一次重要创新实践。该研究论文表明,在已接近性能巅峰的蒸馏模型上,通过该强化学习训练方法也可以大幅提升AIME 2024的准确率,这一研究结果将极大促进正在运行中的较大模型的回复长度和推理准确性。面对语言推理可能存在精准性不够的问题,STILL-3-Tool-32B模型引入了外部工具来加强AI模型的复杂推理能力。在AIME 2024上取得81.70%准确率(采样),以15.56%的显著优势超越其基座训练模型,与OpenAI o3-mini持平,超越o1 和DeepSeek-R1同场景表现。
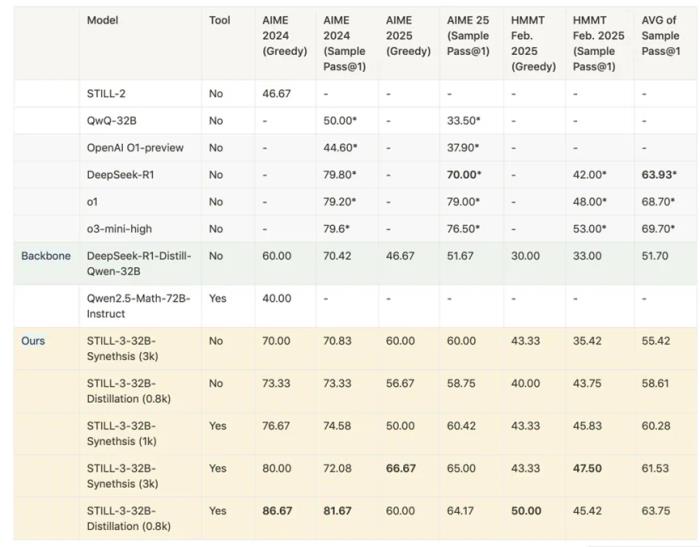
自DeepSeek-R1技术报告公布后,开源模型仍然复现面临代码完整性缺失、超参数调试等共性难题,九章云极DataCanvas联合团队通过AI基础设施深度融合实现突破。研究同步开源了该模型在DataCanvas Alaya NeW智算操作系统上完成的全过程完整训练日志、奖励函数代码及容器化部署方案。研究结果公布,在Alaya NeW中采用on-policy 学习策略是成功的关键因素,其将DeepSeek背后的基于规则的强化学习方法加以微调,充分探索了相关的超参数设置以及训练技巧。
值得关注的是,DeepSeek以及蒸馏模型在推理过程中无法调用外部代码工具,而这恰是复现的关键难点。研究结果显示,Alaya NeW智算操作系统在开源工具链与基座模型适配、算法与算力协同、逻辑推理与多步决策等复杂任务框架方面表现出明显优势,有望推动AI技术的进一步发展。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










