


谷歌更新多款Gemini2.0模型卖力挥舞硅谷AI性价比大旗
财联社2月6日讯(编辑 史正丞)美国搜索引擎和AI巨头谷歌公司周三宣布产品线全面上新,所有用户已经正式迈入“Gemini 2.0”时代。首先是Gemini 2.0 Flash模型上线。作为适用大规模、高容量、高频率任务的模型,自去年12月推出后,就被卷起“性价比风暴”的Deepseek-V3模型抢走
财联社2月6日讯(编辑 史正丞)美国搜索引擎和AI巨头谷歌公司周三宣布产品线全面上新,所有用户已经正式迈入“Gemini 2.0”时代。首先是Gemini 2.0 Flash模型上线。作为适用大规模、高容量、高频率任务的模型,自去年12月推出后,就被卷起“性价比风暴”的Deepseek-V3模型抢走

美国人工智能初创公司Groq最新推出的面向云端大模型的推理芯片引发了业内的广泛关注。其最具特色之处在于,采用了全新的Tensor Streaming Architecture (TSA) 架构,以及拥有超高带宽的SRAM,从而使得其对于大模型的推理速度提高了10倍以上,
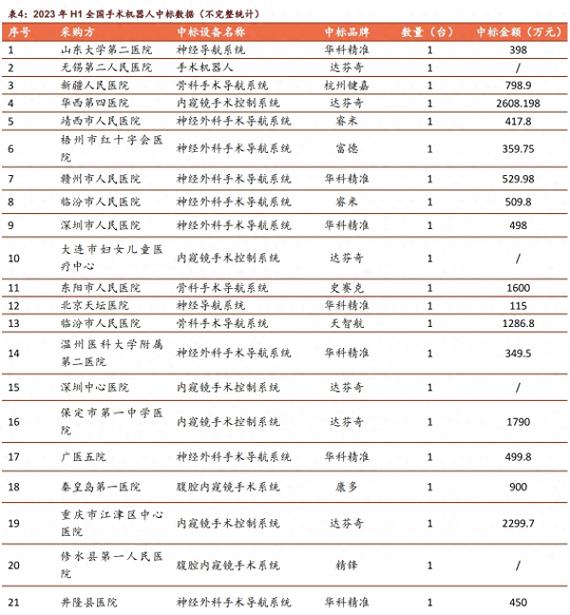
机器人文 | 海若镜“如果把达芬奇手术机器人比作是奔驰,那10年前国产(腔镜)手术机器人就是奥拓,而现在已经发展到了帕萨特的水平。”近日,在由BioBAY主办的第十二届中国医疗器械产业大会上,仁济医院副院长薛蔚讲道。近年来,中国手术机器人赛道发展如火如荼。据36氪统计,截至2023年8月,国内已有3

上证报中国证券网讯(记者杨翔菲 温婷)2月26日,在2025阿里云PolarDB开发者大会上,阿里云宣布PolarDB登顶全球数据库性能及性价比排行榜。

10月18日消息,据媒体报道,Intel将不再在AI市场与NVIDIA进行正面竞争,而是将战略重心转移到推出Gaudi 3等更具有成本效益的AI解决方案上。报道称,这一转变标志着Intel意识到,在计算能力方面与NVIDIA竞争并不是一条可行的可持续发展道路。

RTX 20系列显卡除了引入实时光线追踪,还首次在游戏卡上加入了Tensor Core张量核心,不仅能支持DLSS深度学习超采样抗锯齿之类的游戏特性,也可用于专业计算。那么,RTX 2080 Ti在深度学习方面的性能如何呢?相比于GTX 1080 Ti有多大提升?是否对得起70%的价格涨幅(700美

京东云重磅发布DeepSeek大模型一体机,基于“本地化开箱即用”的理念,提供从底层算力、模型服务、推理能力、应用开发的全栈解决方案,为金融、政府及企业客户打造“数据不出域、性能更高效”的AI服务新范式。全新DeepSeek大模型一体机,更高性价比更低使用门槛DeepSeek凭借其低成本、高性能的特

大语言模型在端侧的规模化应用对计算性能、能效比需求的“提拽式”牵引,在算法与芯片之间,撕开了一道充分的推理竞争场。面对想象中的终端场景,基于 GPU 和 FPGA 的推理方案的应用潜力需要被重新审视。近日,无问芯穹、清华大学和上海交通大学联合提出了一种面向 FPGA 的大模型轻量化部署流程,首次在单

这是作者 Sebastian Raschka 经过数百次实验得出的经验,值得一读。增加数据量和模型的参数量是公认的提升神经网络性能最直接的方法。目前主流的大模型的参数量已扩展至千亿级别,「大模型」越来越大的趋势还将愈演愈烈。

12月26日晚,杭州深度求索人工智能基础技术研究有限公司(简称“深度求索”)宣布,全新系列模型 DeepSeek-V3 首个版本上线并同步开源,API服务已同步更新,接口配置无需改动。 公开信息显示,深度求索成立于2023年7月17日,由知名量化资管巨头幻方量化创立,幻方量化创始人梁文峰在量化投资










