

 新火种
2024-02-23
新火种
2024-02-23 


AI推理速度提升超10倍、性价比超100倍!GroqLPU能否取代NVIDIAGPU
美国人工智能初创公司Groq最新推出的面向云端大模型的推理芯片引发了业内的广泛关注。
其最具特色之处在于,采用了全新的Tensor Streaming Architecture (TSA) 架构,以及拥有超高带宽的SRAM,从而使得其对于大模型的推理速度提高了10倍以上,甚至超越了NVIDIA的GPU。

推理速度比GPU快10倍,功耗仅1/10
据介绍,Groq的大模型推理芯片是全球首个LPU(Language Processing Unit)方案,是一款基于全新的TSA 架构的Tensor Streaming Processor (TSP) 芯片,旨在提高机器学习和人工智能等计算密集型工作负载的性能。
虽然Groq的LPU并没有采用更本高昂的尖端制程工艺,而是选择了14nm制程,但是凭借自研的TSA 架构,Groq LPU 芯片具有高度的并行处理能力,可以同时处理数百万个数据流,并该芯片还集成了230MB容量的SRAM来替代DRAM,以保证内存带宽,其片上内存带宽高达80TB/s。
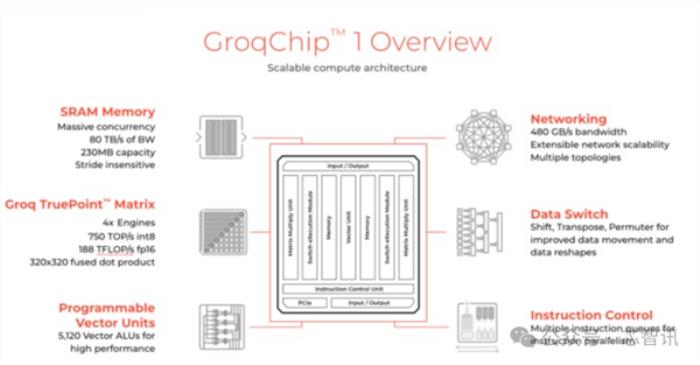
根据官方的数据显示,Groq的LPU芯片的性能表现相当出色,可以提供高达1000 TOPS (Tera Operations Per Second) 的计算能力,并且在某些机器学习模型上的性能表现可以比常规的 GPU 和 TPU 提升10到100倍。
Groq表示,基于其LPU芯片的云服务器在Llama2或Mistreal模型在计算和响应速度上远超基于NVIDIA AI GPU的ChatGPT,其每秒可以生成高达500个 token。
相比之下,目前ChatGPT-3.5的公开版本每秒只能生成大约40个token。
由于ChatGPT-3.5主要是基于NVIDIA的GPU,也就是说,Groq LPU芯片的响应速度达到了NVIDIA GPU的10倍以上。
Groq表示,相对于其他云平台厂商的大模型推理性能,基于其LPU芯片的云服务器的大模型推理性能最终实现了比其他云平台厂商快18倍。
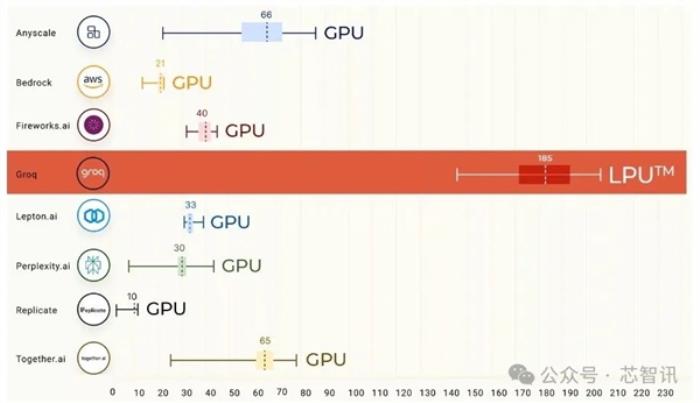
另外,在能耗方面,NVIDIAGPU需要大约10到30焦耳才能生成响应中的tokens,而Groq LPU芯片仅需1到3焦耳,在推理速度大幅提升10倍的同时,其能耗成本仅有NVIDIAGPU的十分之一,这等于是性价比提高了100倍。
Groq公司在演示中展示了其芯片的强大性能,支持Mistral AI的Mixtral8x7B SMoE,以及Meta的Llama2的7B和70B等多种模型,支持使用4096字节的上下文长度,并可直接体验Demo。
不仅如此,Groq还喊话各大公司,扬言在三年内超越NVIDIA。目前该公司的LPU推理芯片在第三方网站上的售价为2万多美元,低于NVIDIA H100的2.5-3万美元。
资料显示,Groq 是一家成立于2016年人工智能硬件初创公司,核心团队来源于谷歌最初的张量处理单元(TPU)工程团队。
Groq 创始人兼CEO Jonathan Ross是谷歌TPU项目的核心研发人员。该公司硬件工程副总裁Jim Miller 曾是亚马逊云计算服务AWS设计算力硬件的负责人,还曾在英特尔领导了所有 Pentium II 工程。
目前该公司筹集了超过 6200 万美元。
为何采用大容量SRAM?
Groq LPU芯片与大多数其他初创公司和现有的AI处理器有着截然不同的时序指令集计算机(Temporal Instruction Set Computer)架构,它被设计为一个强大的单线程流处理器,配备了专门设计的指令集,旨在利用张量操作和张量移动,使机器学习模型能够更有效地执行。
该架构的独特之处在于执行单元、片内的SRAM内存和其他执行单元之间的交互。它无需像使用HBM(高带宽内存)的GPU那样频繁地从内存中加载数据。
Groq 的神奇之处不仅在于硬件,还在于软件。软件定义的硬件在这里发挥着重要作用。
Groq 的软件将张量流模型或其他深度学习模型编译成独立的指令流,并提前进行高度协调和编排。编排来自编译器。它提前确定并计划整个执行,从而实现非常确定的计算。
“这种确定性来自于我们的编译器静态调度所有指令单元的事实。这使我们无需进行任何激进的推测即可公开指令级并行性。芯片上没有分支目标缓冲区或缓存代理,”Groq 的首席架构师 Dennis Abts 解释道。
Groq LPU芯片为了追求性能最大化,因此添加了更多SRAM内存和执行块。
SRAM全名为“静态随机存取存储器”(Static Random-Access Memory)是随机存取存储器的一种。
所谓的“静态”,是指这种存储器只要保持通电,里面储存的数据就可以恒常保持。
相对之下,动态随机存取存储器(DRAM)里面所储存的数据则需要周期性地更新。自SRAM推出60多年来,其一直是低延迟和高可靠性应用的首选存储器,
事实上,对于 AI/ML 应用来说,SRAM 不仅仅具有其自身的优势。
SRAM 对于 AI 至关重要,尤其是嵌入式 SRAM,它是性能最高的存储器,可以将其直接与高密度逻辑核心集成在一起。目前SRAM也是被诸多CPU集成在片内(更靠近CPU计算单元),作为CPU的高速缓存,使得CPU可以更直接、更快速的从SRAM中获取重要的数据,无需去DRAM当中读取。
只不过,当前旗舰级CPU当中的SRAM容量最多也仅有几十个MB。
Groq之所以选择使用大容量的 SRAM来替代DRAM 内存的原因主要有以下几点:
1、SRAM 内存的访问速度比 DRAM 内存快得多,这意味着 LPU 芯片更快速地处理数据,从而提高计算性能。
2、SRAM 内存没有 DRAM 内存的刷新延迟,这意味着LPU芯片也可以更高效地处理数据,减少延迟带来的影响。
3、SRAM 内存的功耗比 DRAM 内存低,这意味着LPU芯片可以更有效地管理能耗,从而提高效率。
但是,对于SRAM来说,其也有着一些劣势:
1、面积更大:
在逻辑晶体管随着CMOS工艺持续微缩的同时,SRAM的微缩却十分的困难。事实上,早在 20nm时代,SRAM 就无法随着逻辑晶体管的微缩相应地微缩。
2、容量小:
SRAM 的容量比 DRAM 小得多,这是因为每个bit的数据需要更多的晶体管来存储,再加上SRAM的微缩非常困难,使得相同面积下,SRAM容量远低于DRAM等存储器。这也使得SRAM在面对需要存储大量数据时的应用受到了限制。
3、成本高:
SRAM 的成本比 DRAM要高得多,再加上相同容量下,SRAM需要更多的晶体管来存储数据,这也使得其成本更高。
总的来说,虽然SRAM 在尺寸、容量和成本等方面具有一些劣势,这些劣势限制了其在某些应用中的应用,但是 SRAM 的访问速度比 DRAM 快得多,这使得它在某些计算密集型应用中表现得非常出色。
Groq LPU 芯片采用的大容量 SRAM 内存可以提供更高的带宽(高达80TB/s)、更低的功耗和更低的延迟,从而提高机器学习和人工智能等计算密集型工作负载的效率。
那么,与目前AI GPU当中所搭载的 HBM 内存相比,Groq LPU 芯片集成的 SRAM 内存又有何优势和劣势呢?
Groq LPU 芯片的 SRAM 内存容量虽然有230MB,但是相比之下AI GPU 中的 HBM 容量通常都有数十GB(比如NVIDIA H100,其集成了80GB HBM),这也意味着LPU 芯片可能无法处理更大的数据集和更复杂的模型。相同容量下,SRAM的成本也比HBM更高。
不过,与HBM 相比,Groq LPU 芯片的所集成的 SRAM 的仍然有着带宽更快(NVIDIA H100的HBM带宽仅3TB/s)、功耗更低、延迟更低的优势。
能否替代NVIDIA H00?
虽然Groq公布的数据似乎表明,其LPU芯片的推理速度达到了NVIDIA GPU的10倍以上,并且能耗成本仅是它十分之一,等于是性价比提高了100倍。
但是,Groq并且明确指出其比较的是NVIDIA的哪款GPU产品。由于目前NVIDIA最主流的AI GPU是H100,因此,我们就拿NVIDIA H100来与Groq LPU来做比较。
由于Groq LPU只有230MB的片上SRAM来作为内存,因此,如果要运行Llama-2 70b模型,即使将Llama 2 70b量化到INT8精度,仍然需要70GB左右的内存。
即使完全忽略内存消耗,也需要305张Groq LPU加速卡才够用。如果考虑到内存消耗,可能需要572张Groq LPU加速卡。
官方数据显示,Groq LPU的平均功耗为185W,即使不计算外围设备的功耗,572张Groq LPU加速卡的总功耗也高达105.8kW。
假设一张Groq LPU加速卡的价格为2万美元,因此,购买572张卡的成本高达1144万美元(规模采购价格应该可以更低)。
根据人工智能科学家贾扬清分享的数据显示,目前,数据中心每月每千瓦的平均价格约为20美元,这意味着572张Groq LPU加速卡每年的电费为105.8*200*12=25.4万美元。
贾扬清还表示,使用4张NVIDIA H100加速卡就可以实现572张Groq LPU一半的性能,这意味着一个8张H100的服务器的性能大致相当于572张Groq LPU。
而8张H100加速卡的标称最大功率为10kW(实际上约为8-9千瓦),因此一年电费为仅24000美元或略低。现在一个8张H100加速卡的服务器的价格约为30万美元。
显然,相比较之下,在运行相同的INT8精度的Llama-2 70b模型时,NVIDIA H00的实际性价比要远高于Groq LPU。
即使我们以FP16精度的Llama-2 7b模型来比较,其最低需要14GB的内存来运行,需要约70张Groq LPU加速卡才能够部署,按照单卡FP16算力188TFLOPs计算,其总算力将达到约13.2PFLOPs。这么强的算力只是用来推理Llama-2 7b模型属实有些浪费。
相比之下,单个NVIDIA H100加速卡,其集成的80GB HMB就足够部署5个FP16精度的Llama-2 7b模型,而H100在FP16算力约为2PFLOPs。即使要达到70张Groq LPU加速卡相同的算力,只需要一台8卡NVIDIA H100服务器就能够达到。
单从硬件成本上来计算,70张Groq LPU加速卡成本约140万美元,一个8张H100加速卡的服务器的价格约为30万美元,显然,对于运行FP16精度的Llama-2 7b模型来说,采用NVIDIA H100的性价比也是远高于Groq LPU。
当然,这并不是说Groq LPU相对于NVIDIA H100来说毫无优势,正如前面所介绍的那样,Groq LPU的主要优势在于其采用了大容量的SRAM内存,拥有80TB/s的超高的内存带宽,使得其非常适合于较小的模型且需要频繁从内存访问数据的应用场景。
当然,其缺点则在于SRAM的内存容量较小,要运行大模型,就需要更多的Groq LPU。
那么,Groq LPU能否进一步提升其SRAM内存容量来弥补这一缺点呢?
答案当然是可以,但是,这将会带来Groq LPU面积和成本的大幅增加,并且也会带来功耗方面的问题。
或许未来Groq可能会考虑,加入HBM/DRAM来提升 LPU的适应性。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章










