

 新火种
2024-11-16
新火种
2024-11-16 

比A100性价比更高!FlightLLM让大模型推理不再为性能和成本同时发愁
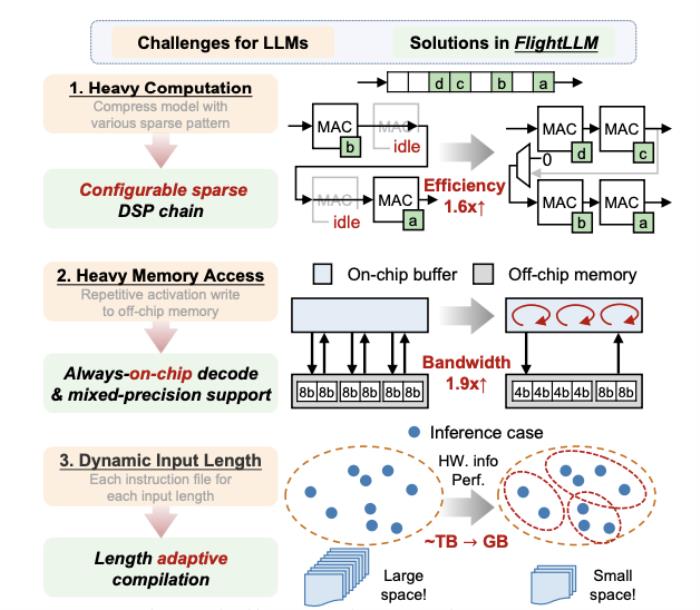
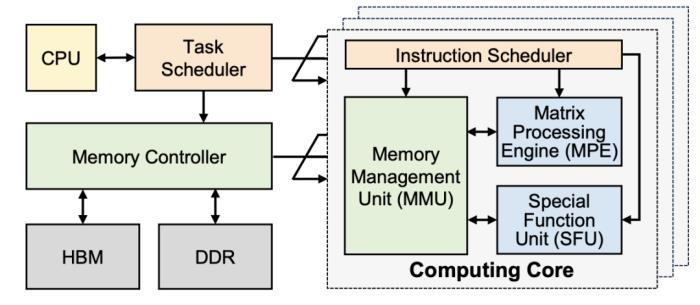
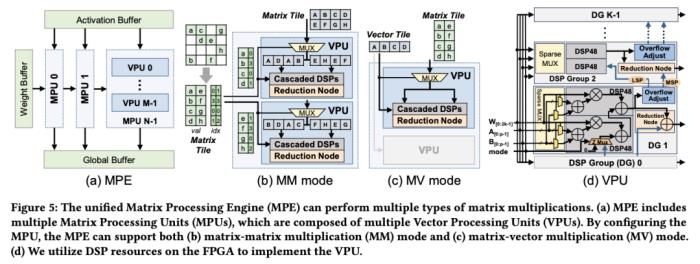
大语言模型在端侧的规模化应用对计算性能、能效比需求的“提拽式”牵引,在算法与芯片之间,撕开了一道充分的推理竞争场。面对想象中的终端场景,基于 GPU 和 FPGA 的推理方案的应用潜力需要被重新审视。近日,无问芯穹、清华大学和上海交通大学联合提出了一种面向 FPGA 的大模型轻量化部署流程,首次在单块 Xilinx U280 FPGA 上实现了 LLaMA2-7B 的高效推理。第一作者为清华大学电子系博士及无问芯穹硬件负责人曾书霖,通讯作者为上海交通大学副教授、无问芯穹联合创始人兼首席科学家戴国浩,清华大学电子工程系教授、系主任及无问芯穹发起人汪玉。相关工作现已被可重构计算领域顶级会议 FPGA’24 接收。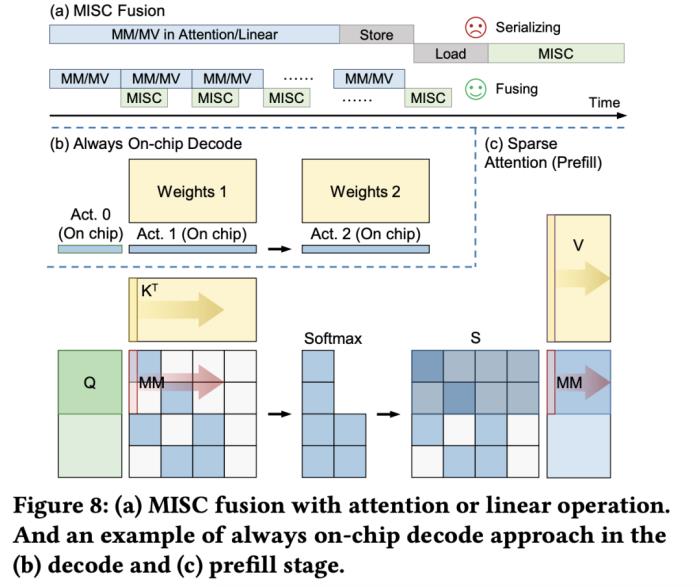 (a)大模型推理阶段的注意力层/线性层与非线性激活操作(MISC)的算子融合实现;全片上解码在(b)预取(Prefill)阶段和(c)解码(Decode)阶段的示意图:利用算子融合和FPGA的高片上存储,使得大模型推理解码阶段的激活值无须写到片外。为了减少激活向量的片外存储器访问,解决访存带宽利用率低的挑战,FlightLLM 使用了算子融合技术,将解码阶段每次推断中的计算进行融合,提出了 always-on-chip decode 的数据流。通过混合精度量化和算子融合的设计,将 decode 阶段的激活值最大程度在片上缓存中复用。最后,由于大模型每次推理过程 token 长度都会增加,因此需要不同的指令。而大模型有大量计算和存储需求,即使使用粗粒度指令,指令数量仍然非常庞大。
(a)大模型推理阶段的注意力层/线性层与非线性激活操作(MISC)的算子融合实现;全片上解码在(b)预取(Prefill)阶段和(c)解码(Decode)阶段的示意图:利用算子融合和FPGA的高片上存储,使得大模型推理解码阶段的激活值无须写到片外。为了减少激活向量的片外存储器访问,解决访存带宽利用率低的挑战,FlightLLM 使用了算子融合技术,将解码阶段每次推断中的计算进行融合,提出了 always-on-chip decode 的数据流。通过混合精度量化和算子融合的设计,将 decode 阶段的激活值最大程度在片上缓存中复用。最后,由于大模型每次推理过程 token 长度都会增加,因此需要不同的指令。而大模型有大量计算和存储需求,即使使用粗粒度指令,指令数量仍然非常庞大。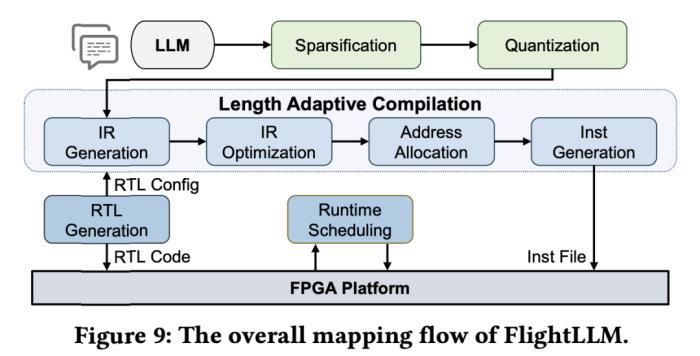 通过在不同输入 token 长度下推理性能的测量,作者观察到 prefill 和 decode 的延时和输入 token 长度之间的关系存在着 「阶梯」增长的特征,并且 prefill 阶段延时随输入 token 长度增加得更快。这是因为 prefill 阶段是计算瓶颈,计算量随 token 长度显著增加;而 decode 阶段是访存瓶颈,因此延时增加不明显。阶梯状增长的原因则主要是粗粒度指令集。由于矩阵 - 矩阵乘指令的输出并行度是 128,矩阵 - 向量乘的输出并行度是 16,因此 prefill 和 decode 的 「阶梯」的宽度分别为 128 和 16。基于这些发现,FlightLLM 提出了一种 token 长度自适应的编译方法,通过复用 prefill 阶段和 decode 阶段的指令来减少编译指令的存储开销,进而对每个 「阶梯」输入 token 长度的指令分组,以 「阶梯」 宽度复用指令序列。这种设计显著减少了指令的总存储开销。目前,作者已在 Xilinx Alveo U280 FPGA(16nm)上实现了 FlightLLM。在 OPT-6.7B 和 LLaMA2-7B 上的实验结果表明,FlightLLM 的端到端延迟优于 NVIDIA V100S GPU。
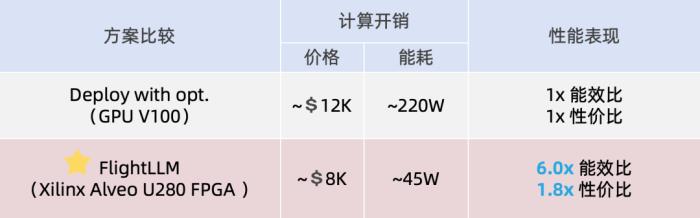
通过在不同输入 token 长度下推理性能的测量,作者观察到 prefill 和 decode 的延时和输入 token 长度之间的关系存在着 「阶梯」增长的特征,并且 prefill 阶段延时随输入 token 长度增加得更快。这是因为 prefill 阶段是计算瓶颈,计算量随 token 长度显著增加;而 decode 阶段是访存瓶颈,因此延时增加不明显。阶梯状增长的原因则主要是粗粒度指令集。由于矩阵 - 矩阵乘指令的输出并行度是 128,矩阵 - 向量乘的输出并行度是 16,因此 prefill 和 decode 的 「阶梯」的宽度分别为 128 和 16。基于这些发现,FlightLLM 提出了一种 token 长度自适应的编译方法,通过复用 prefill 阶段和 decode 阶段的指令来减少编译指令的存储开销,进而对每个 「阶梯」输入 token 长度的指令分组,以 「阶梯」 宽度复用指令序列。这种设计显著减少了指令的总存储开销。目前,作者已在 Xilinx Alveo U280 FPGA(16nm)上实现了 FlightLLM。在 OPT-6.7B 和 LLaMA2-7B 上的实验结果表明,FlightLLM 的端到端延迟优于 NVIDIA V100S GPU。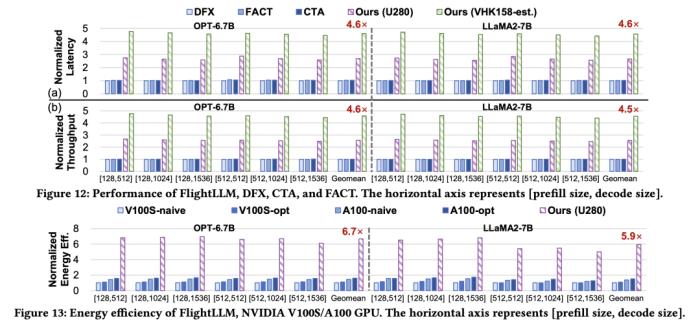 此外,FlightLLM(基于 U280 FPGA 和 VHK158 FPGA)在能效上超过了 NVIDIA V100S 和 A100 GPU,分别提高了 6.0× 和 4.2×,在性价比上提高了 1.8× 和 1.5×。更多详细细节,请参阅论文原文。
此外,FlightLLM(基于 U280 FPGA 和 VHK158 FPGA)在能效上超过了 NVIDIA V100S 和 A100 GPU,分别提高了 6.0× 和 4.2×,在性价比上提高了 1.8× 和 1.5×。更多详细细节,请参阅论文原文。

(a)大模型推理阶段的注意力层/线性层与非线性激活操作(MISC)的算子融合实现;全片上解码在(b)预取(Prefill)阶段和(c)解码(Decode)阶段的示意图:利用算子融合和FPGA的高片上存储,使得大模型推理解码阶段的激活值无须写到片外。为了减少激活向量的片外存储器访问,解决访存带宽利用率低的挑战,FlightLLM 使用了算子融合技术,将解码阶段每次推断中的计算进行融合,提出了 always-on-chip decode 的数据流。通过混合精度量化和算子融合的设计,将 decode 阶段的激活值最大程度在片上缓存中复用。最后,由于大模型每次推理过程 token 长度都会增加,因此需要不同的指令。而大模型有大量计算和存储需求,即使使用粗粒度指令,指令数量仍然非常庞大。通过在不同输入 token 长度下推理性能的测量,作者观察到 prefill 和 decode 的延时和输入 token 长度之间的关系存在着 「阶梯」增长的特征,并且 prefill 阶段延时随输入 token 长度增加得更快。这是因为 prefill 阶段是计算瓶颈,计算量随 token 长度显著增加;而 decode 阶段是访存瓶颈,因此延时增加不明显。阶梯状增长的原因则主要是粗粒度指令集。由于矩阵 - 矩阵乘指令的输出并行度是 128,矩阵 - 向量乘的输出并行度是 16,因此 prefill 和 decode 的 「阶梯」的宽度分别为 128 和 16。基于这些发现,FlightLLM 提出了一种 token 长度自适应的编译方法,通过复用 prefill 阶段和 decode 阶段的指令来减少编译指令的存储开销,进而对每个 「阶梯」输入 token 长度的指令分组,以 「阶梯」 宽度复用指令序列。这种设计显著减少了指令的总存储开销。目前,作者已在 Xilinx Alveo U280 FPGA(16nm)上实现了 FlightLLM。在 OPT-6.7B 和 LLaMA2-7B 上的实验结果表明,FlightLLM 的端到端延迟优于 NVIDIA V100S GPU。此外,FlightLLM(基于 U280 FPGA 和 VHK158 FPGA)在能效上超过了 NVIDIA V100S 和 A100 GPU,分别提高了 6.0× 和 4.2×,在性价比上提高了 1.8× 和 1.5×。更多详细细节,请参阅论文原文。 相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










