新火种
2024-12-03
新火种
2024-12-03 


NeurIPS2024|杜克大学&谷歌提出SLED解码框架,无需外部数据与额外训练,有效缓解大语言模型幻觉,提高事实准确性
此项研究成果已被 NeurIPS 2024 录用。该论文的第一作者是杜克大学电子计算机工程系的博士生张健一,其主要研究领域为生成式 AI 的概率建模与可信机器学习,导师为陈怡然教授。
大语言模型(LLM)在各种任务上展示了卓越的性能。然而,受到幻觉(hallucination)的影响,LLM 生成的内容有时会出现错误或与事实不符,这限制了其在实际应用中的可靠性。
针对这一问题,来自杜克大学和 Google Research 的研究团队提出了一种新的解码框架 —— 自驱动 Logits 进化解码(SLED),旨在提升大语言模型的事实准确性,且无需依赖外部知识库,也无需进行额外的微调。

论文地址:https://arxiv.org/pdf/2411.02433
项目主页:https://jayzhang42.github.io/sled_page/
Github地址:https://github.com/JayZhang42/SLED
作者主页:https://jayzhang42.github.io
研究背景与思路总结近期相关研究显示,尽管用户在访问大语言模型(LLM)时可能无法得到正确的答案,但 LLM 实际上可能已经基于海量的训练数据和漫长的训练周期学到了正确的答案,并将其存储于模型内部某处。研究者将这类无法直观从模型输出中获得的信息称为 “潜在知识”,并用图一精炼出了对应的 “三体问题”。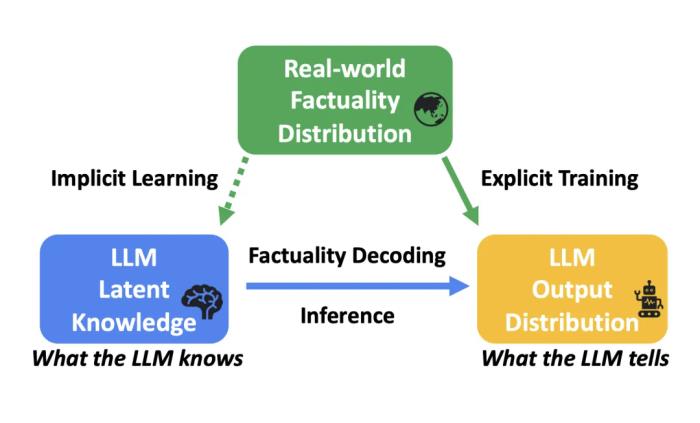 图一:Factuality Decoding 的 “三体问题”图一中,考虑到每条问题的标准答案都已包含训练数据集中,因此可以说训练时,真实世界的事实分布是已知的。LLM 的训练正是为了缩小 LLM 输出分布
图一:Factuality Decoding 的 “三体问题”图一中,考虑到每条问题的标准答案都已包含训练数据集中,因此可以说训练时,真实世界的事实分布是已知的。LLM 的训练正是为了缩小 LLM 输出分布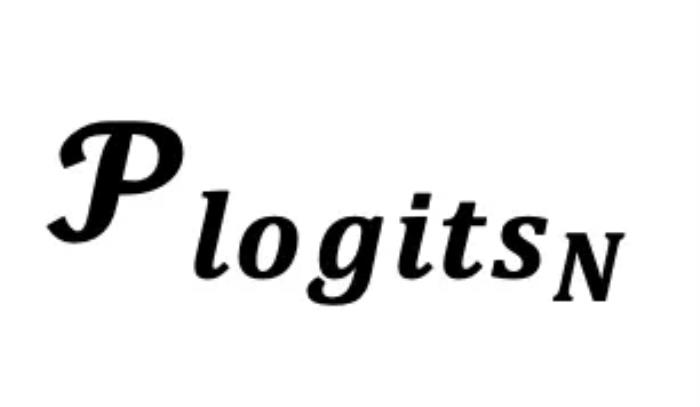 和真实事实分布
和真实事实分布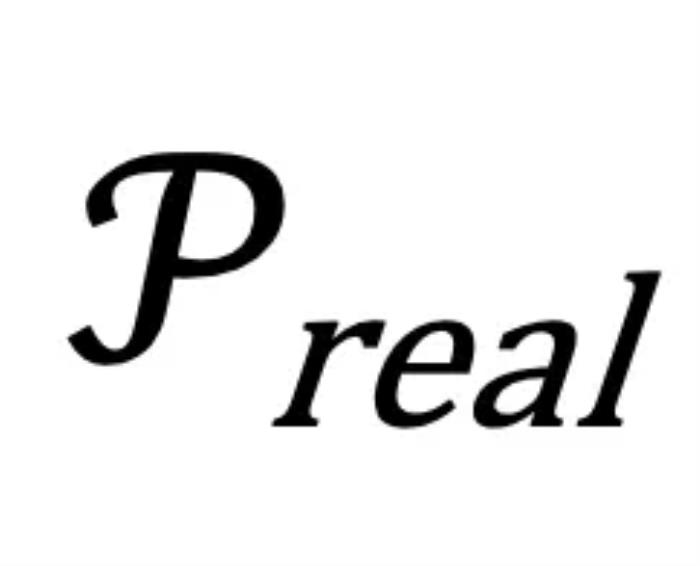 之间的差距。然而,在 LLM 的推理阶段(inference time),真实的事实分布是未知的,因此这项研究的重点便是如何挖掘模型的潜在知识分布,并利用其进一步增强模型的输出。概括来说, SLED 方法通过对比最后一层的
之间的差距。然而,在 LLM 的推理阶段(inference time),真实的事实分布是未知的,因此这项研究的重点便是如何挖掘模型的潜在知识分布,并利用其进一步增强模型的输出。概括来说, SLED 方法通过对比最后一层的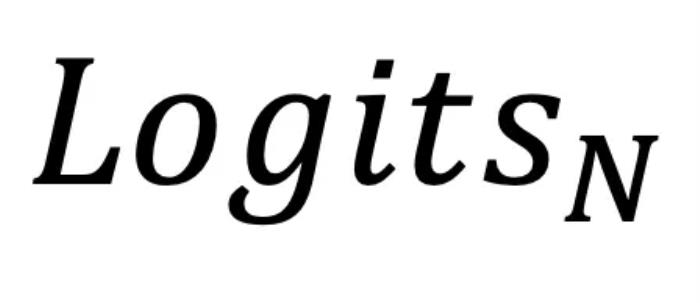 和前面几层的
和前面几层的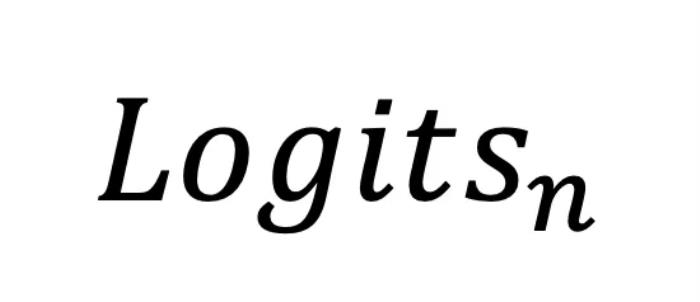 ,有效地挖掘了 LLMs 内部的潜在知识。同时,研究者也指出 LLM 中的潜在知识虽然有价值,但可能并不完美。因此,SLED 不是简单地使用这些潜在知识替换原始输出,而是通过类似于对输出
,有效地挖掘了 LLMs 内部的潜在知识。同时,研究者也指出 LLM 中的潜在知识虽然有价值,但可能并不完美。因此,SLED 不是简单地使用这些潜在知识替换原始输出,而是通过类似于对输出 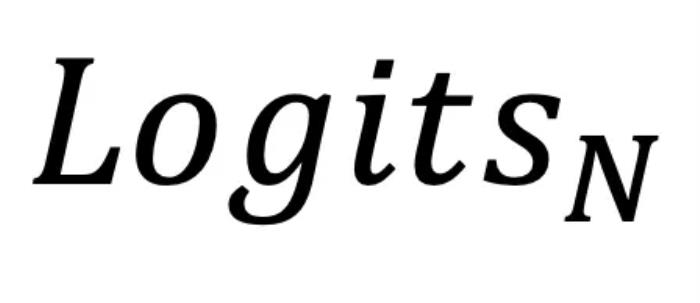 进行 “梯度下降” 的操作,将其整合到原始输出
进行 “梯度下降” 的操作,将其整合到原始输出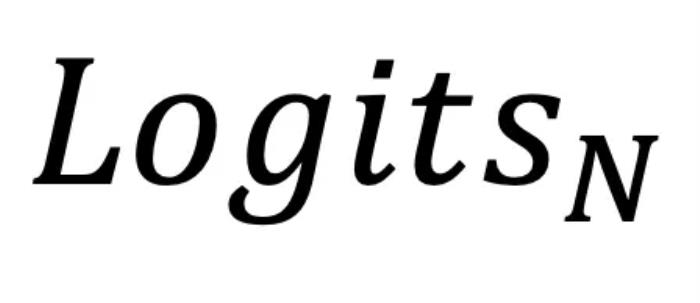 中,从而有效地平衡了两者,避免了过拟合等潜在的风险。
中,从而有效地平衡了两者,避免了过拟合等潜在的风险。 图二:SLED 框架的主要流程方法设计为了提高事实准确性,需要确保正确的 token
图二:SLED 框架的主要流程方法设计为了提高事实准确性,需要确保正确的 token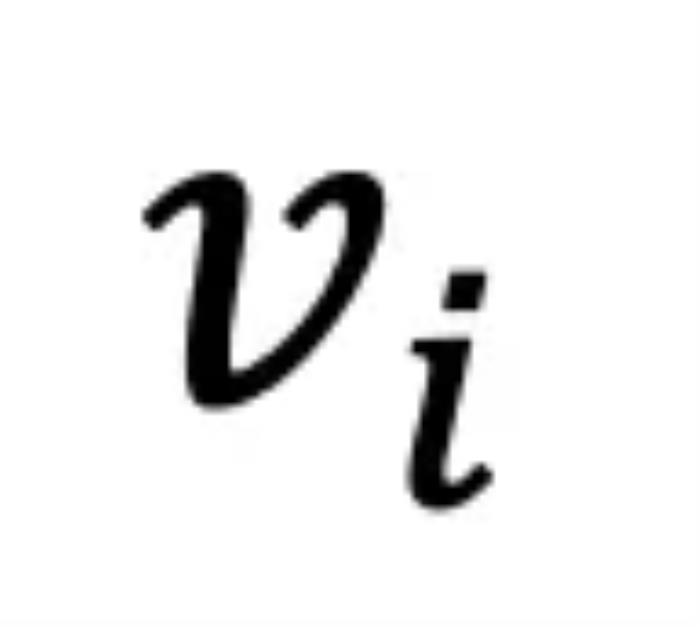 , 在输出分布
, 在输出分布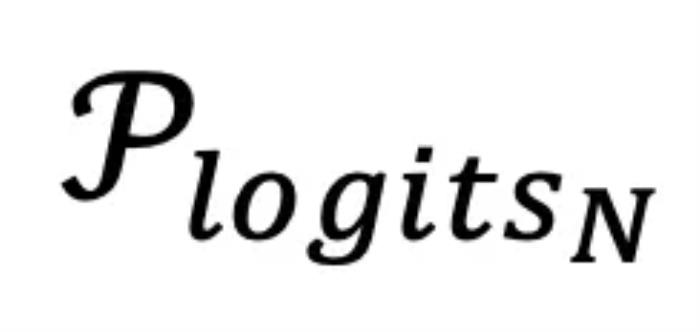 中获得更高的概率。这一过程可以通过优化以下损失函数 L 来描述
中获得更高的概率。这一过程可以通过优化以下损失函数 L 来描述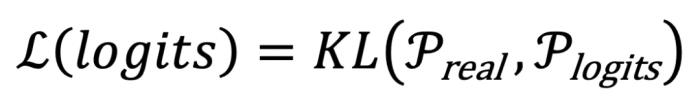 ,其中
,其中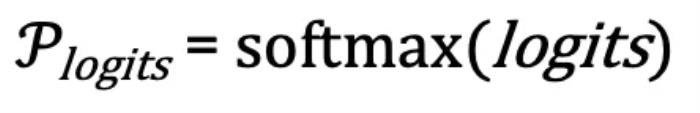 。研究者将这一优化过程称为Logits 进化。有趣的是,这同时也为理解 LLM 的训练提供了新的视角 —— 不同于之前只关注训练中模型参数的更新,可以看到:LLM 的训练实际上一个是由训练数据集作为外部驱动的 Logits 进化过程;LLM 的训练为这个优化过程找到的解就是最后一层的输出
。研究者将这一优化过程称为Logits 进化。有趣的是,这同时也为理解 LLM 的训练提供了新的视角 —— 不同于之前只关注训练中模型参数的更新,可以看到:LLM 的训练实际上一个是由训练数据集作为外部驱动的 Logits 进化过程;LLM 的训练为这个优化过程找到的解就是最后一层的输出 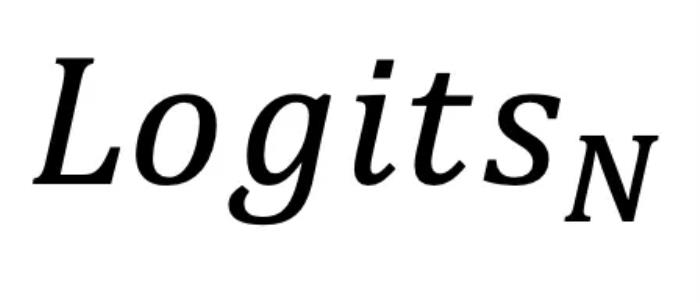 。从上面的理解出发,可以预期最后一层的输出的
。从上面的理解出发,可以预期最后一层的输出的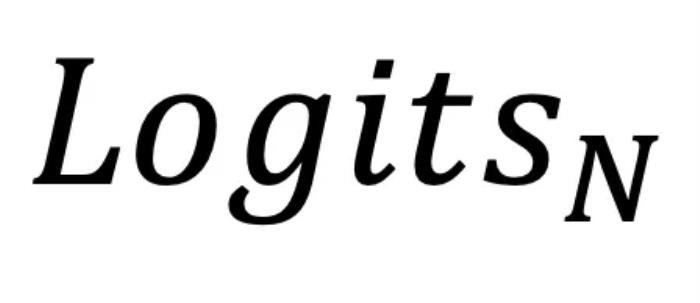 对应的
对应的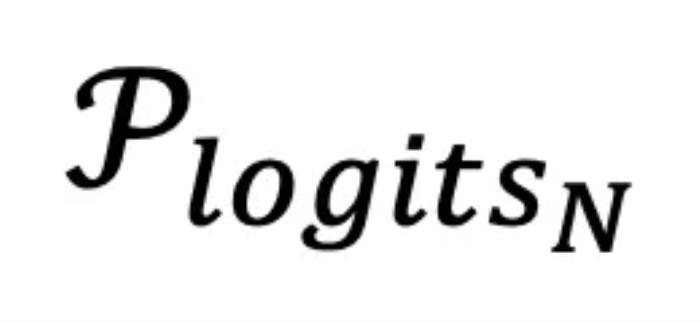 ,通常要比前面几层的输出
,通常要比前面几层的输出 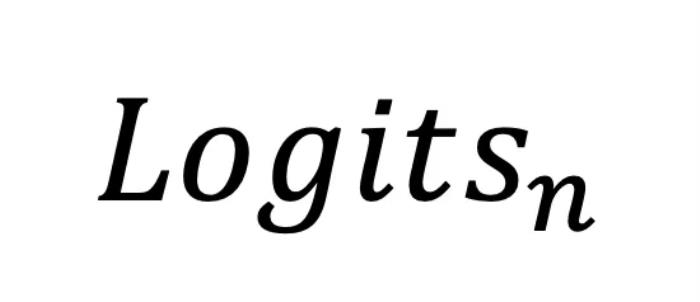 对应的
对应的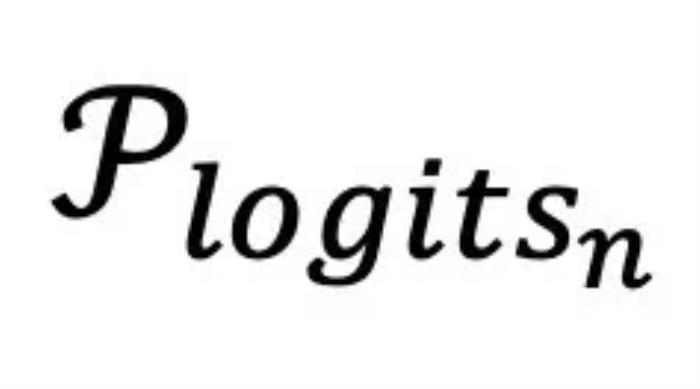 要更接近训练时的
要更接近训练时的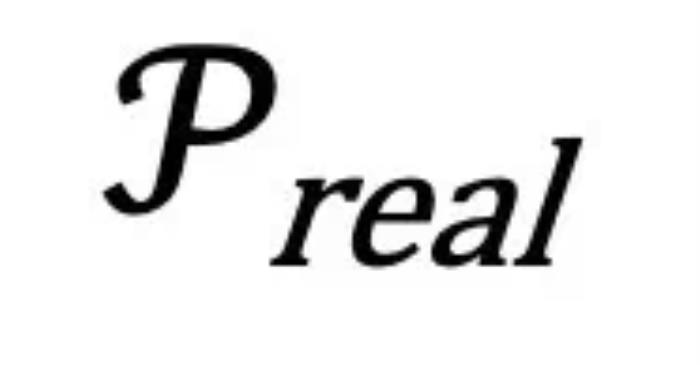 。这一点也在图三中得到了验证。
。这一点也在图三中得到了验证。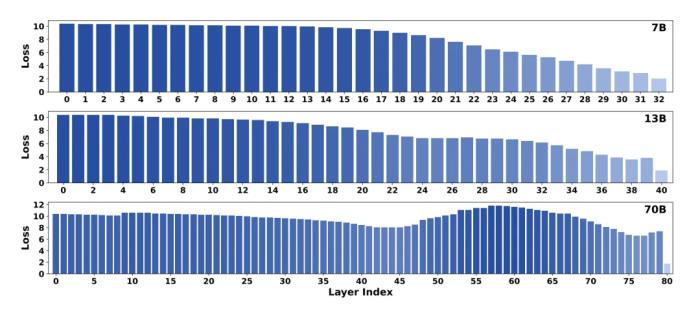 图三:研究者对三个不同规模的 LLaMA-2 模型计算了每一层对应的交叉熵损失。结果证实,就 KL 散度而言,最终层的 Logits 输出分布比所有早期层更接近真实世界的分布因此,受到经典梯度下降算法的启发,研究者通过如下的近似来反向估计
图三:研究者对三个不同规模的 LLaMA-2 模型计算了每一层对应的交叉熵损失。结果证实,就 KL 散度而言,最终层的 Logits 输出分布比所有早期层更接近真实世界的分布因此,受到经典梯度下降算法的启发,研究者通过如下的近似来反向估计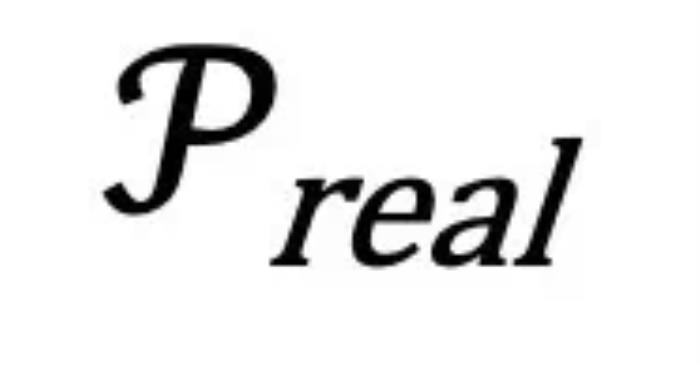
 这里对
这里对 的估计,实际上也就是之前提到的潜在知识,因此用
的估计,实际上也就是之前提到的潜在知识,因此用 来表示。在此基础上,研究者通过类似梯度下降的方式,用估计出来的潜在知识
来表示。在此基础上,研究者通过类似梯度下降的方式,用估计出来的潜在知识 ,实现了对
,实现了对  自驱动进化,
自驱动进化, 从而得到了一个更接近事实分布的最终输出
从而得到了一个更接近事实分布的最终输出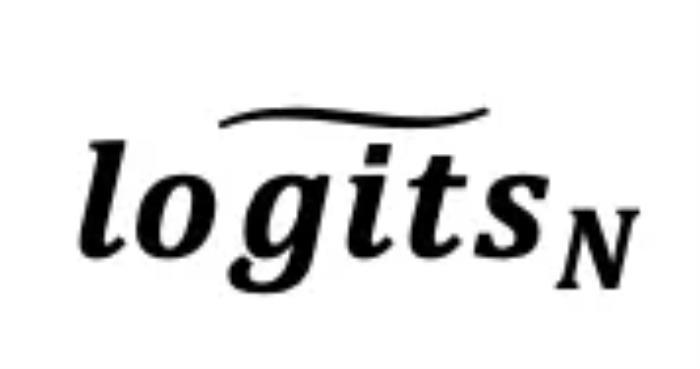 。更细节的方法设计和讨论,请参考原文。实验验证作为一种新型的层间对比解码架构,研究者首先将 SLED 与当前最先进的方法 DoLa 进行了比较。实验覆盖了多种 LLM families(LLaMA 2, LLaMA 3, Gemma)和不同模型规模(从 2B 到 70B),还有当前备受关注的混合专家(MoE)架构。结果表明,SLED 在多种任务(包括多选、开放式生成和思维链推理任务的适应性)上均展现出明显的事实准确性提升。
。更细节的方法设计和讨论,请参考原文。实验验证作为一种新型的层间对比解码架构,研究者首先将 SLED 与当前最先进的方法 DoLa 进行了比较。实验覆盖了多种 LLM families(LLaMA 2, LLaMA 3, Gemma)和不同模型规模(从 2B 到 70B),还有当前备受关注的混合专家(MoE)架构。结果表明,SLED 在多种任务(包括多选、开放式生成和思维链推理任务的适应性)上均展现出明显的事实准确性提升。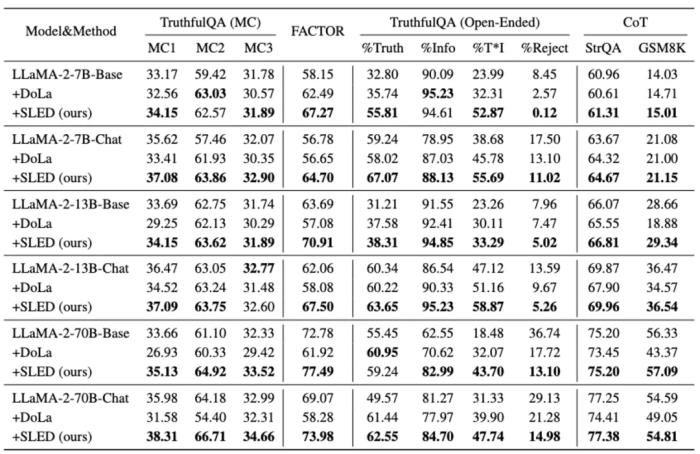 此外 SLED 与其他常见的解码方式(如 contrastive decoding,ITI)具有良好的兼容性,能够进一步提升性能。
此外 SLED 与其他常见的解码方式(如 contrastive decoding,ITI)具有良好的兼容性,能够进一步提升性能。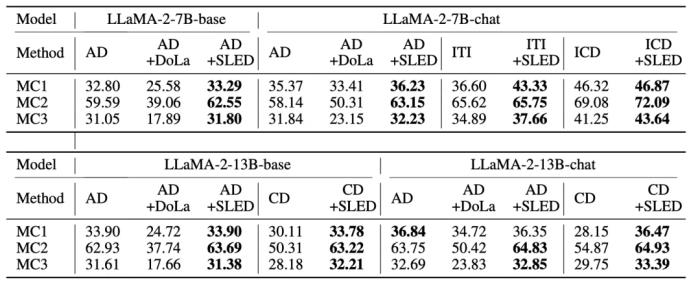 最后,研究者发现,与以往的算法相比,SLED 在计算上几乎没有明显的额外开销。同时,在生成质量方面,SLED 显著抑制了以往方法中的重复性问题,进一步优化了输出结果。
最后,研究者发现,与以往的算法相比,SLED 在计算上几乎没有明显的额外开销。同时,在生成质量方面,SLED 显著抑制了以往方法中的重复性问题,进一步优化了输出结果。 引申思考:与目前流行的 inference-time 算法的联系实际上,不难看出,SLED 为后续的推理时(inference-time )算法提供了一个新的框架。与目前大多数 inference-time computing 方法主要集中于 sentence level 的输出或 logits 进行启发式修改不同,SLED 与经典优化算法衔接,如梯度下降法的结合更为紧密自然。因此,SLED 不仅优化效率更高,同时有很多的潜在的研究方向可以尝试;另一方面,与 inference time training 方法相比,SLED 不涉及模型参数层面的修改,因此优化效率上开销更小,同时更能保持模型原有性能。总结本研究通过引入自驱动 Logits 进化解码(SLED)方法,成功地提升 LLM 在多种任务中的事实准确性。展望未来,可以探索将 SLED 与监督式微调方法结合,以适应其他领域的特定需求如医疗和教育领域。同时,改进框架设计也将是持续关注的方向。
引申思考:与目前流行的 inference-time 算法的联系实际上,不难看出,SLED 为后续的推理时(inference-time )算法提供了一个新的框架。与目前大多数 inference-time computing 方法主要集中于 sentence level 的输出或 logits 进行启发式修改不同,SLED 与经典优化算法衔接,如梯度下降法的结合更为紧密自然。因此,SLED 不仅优化效率更高,同时有很多的潜在的研究方向可以尝试;另一方面,与 inference time training 方法相比,SLED 不涉及模型参数层面的修改,因此优化效率上开销更小,同时更能保持模型原有性能。总结本研究通过引入自驱动 Logits 进化解码(SLED)方法,成功地提升 LLM 在多种任务中的事实准确性。展望未来,可以探索将 SLED 与监督式微调方法结合,以适应其他领域的特定需求如医疗和教育领域。同时,改进框架设计也将是持续关注的方向。 相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章