

 新火种
2023-11-01
新火种
2023-11-01 


DeepMind:谁说卷积网络不如ViT?
本文通过评估按比例扩大的 NFNets,挑战了 ConvNets 在大规模上表现不如 ViTs 的观点。
深度学习的早期成功可归功于卷积神经网络(ConvNets)的发展。近十年来,ConvNets 主导了计算机视觉基准测试。然而近年来,它们越来越多地被 ViTs(Vision Transformers)所取代。
很多人认为,ConvNets 在小型或中等规模的数据集上表现良好,但在那种比较大的网络规模的数据集上却无法与 ViTs 相竞争。
与此同时,CV 社区已经从评估随机初始化网络在特定数据集 (如 ImageNet) 上的性能转变为评估从网络收集的大型通用数据集上预训练的网络的性能。这就提出了一个重要的问题:在类似的计算预算下,Vision Transformers 是否优于预先训练的 ConvNets 架构?
本文,来自 Google DeepMind 的研究者对这一问题进行了探究,他们通过在不同尺度的 JFT-4B 数据集(用于训练基础模型的大型标签图像数据集)上对多种 NFNet 模型进行预训练,从而获得了类似于 ViTs 在 ImageNet 上的性能。

论文地址:https://arxiv.org/pdf/2310.16764.pdf
本文考虑的预训练计算预算在 0.4k 到 110k TPU-v4 核计算小时之间,并通过增加 NFNet 模型家族的深度和宽度来训练一系列网络。本文观察到这一现象,即 held out 损失与计算预算之间存在 log-log 扩展率(scaling law)。
例如,本文将在 JFT-4B 上预训练的 NFNet 从 0.4k 扩展到 110k TPU-v4 核小时(core hours)。经过微调后,最大的模型达到了 90.4% 的 ImageNet Top-1,在类似的计算预算下与预训练的 ViT 相竞争。
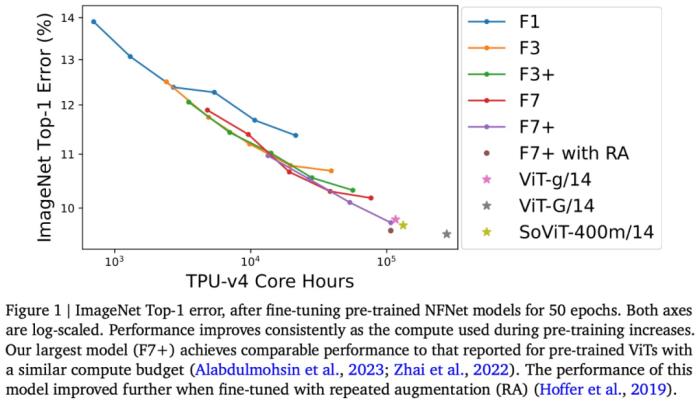
可以说,本文通过评估按比例扩大的 NFNets,挑战了 ConvNets 在大规模数据集上表现不如 ViTs 的观点。此外,在足够的数据和计算条件下,ConvNets 仍然具有竞争力,模型设计和资源比架构更重要。
看到这项研究后,图灵奖得主 Yann LeCun 表示:「计算是你所需要的,在给定的计算量下,ViT 和 ConvNets 相媲美。尽管 ViTs 在计算机视觉方面的成功令人印象深刻,但在我看来,没有强有力的证据表明,在公平评估时,预训练的 ViT 优于预训练的 ConvNets。」
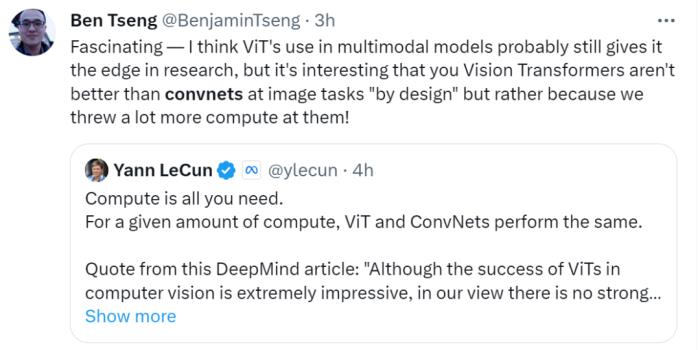
不过有网友评论 LeCun,他认为 ViT 在多模态模型中的使用可能仍然使它在研究中具有优势。
来自 Google DeepMind 的研究者表示:ConvNets 永远不会消失。

接下来我们看看论文具体内容。
预训练的 NFNets 遵循扩展定律
本文在 JFT-4B 上训练了一系列不同深度和宽度的 NFNet 模型。
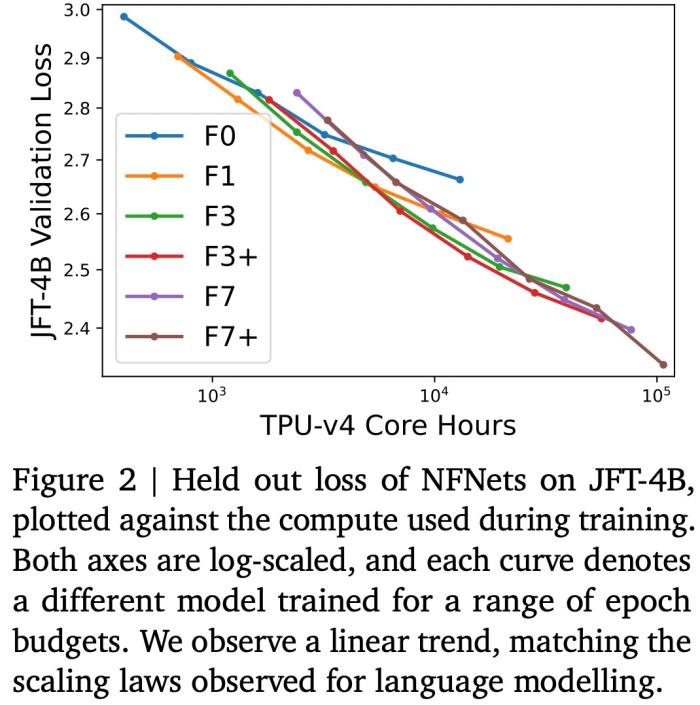
如下图 2 所示,验证损失与训练模型的计算预算呈线性关系,这与使用 Transformer 进行语言建模(Brown et al., 2020; Hoffmann et al., 2022)时观察到的双对数(log-log)扩展定律相匹配。最佳模型大小和最佳 epoch 预算(实现最低验证损失)都会随着计算预算的增加而增加。
下图 3 绘制了 3 个模型在一系列 epoch 预算中观察到的最佳学习率(最大限度地减少验证损失)。研究团队发现对于较低的 epoch 预算,NFNet 系列模型都显示出类似的最佳学习率
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章










