

 新火种
2024-12-05
新火种
2024-12-05 


阿里多模态检索智能体,自带o1式思考过程!复杂问题逐步拆解
多模态检索增强生成(mRAG)也有o1思考推理那味儿了!
阿里通义实验室新研究推出自适应规划的多模态检索智能体。
名叫OmniSearch,它能模拟人类解决问题的思维方式,将复杂问题逐步拆解进行智能检索规划。
直接看效果:
随便上传一张图,询问任何问题,OmniSearch都会进行一段“思考过程”,不仅会将复杂问题拆解检索,而且会根据当前检索结果和问题情境动态调整下一步检索策略。
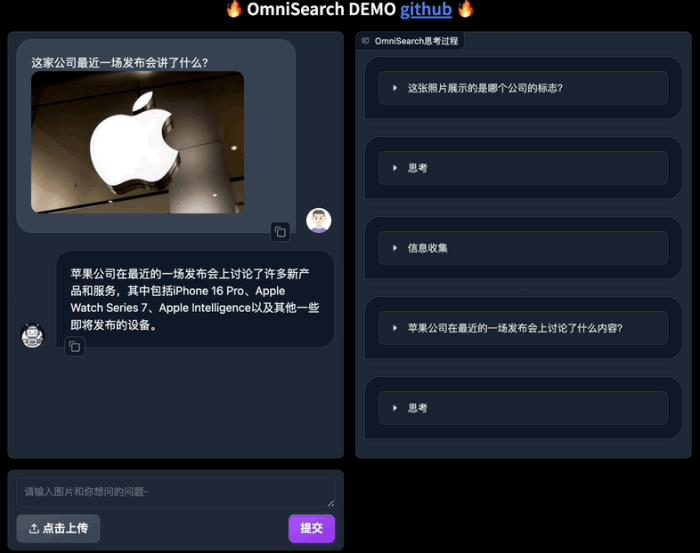
相比传统mRAG受制于其静态的检索策略,这种设计不仅提高了检索效率,也显著增强了模型生成内容的准确性。
为评估OmniSearch,研究团队构建了全新Dyn-VQA数据集。
在一系列基准数据集上的实验中,OmniSearch展现了显著的性能优势。特别是在处理需要多步推理、多模态知识和快速变化答案的问题时,OmniSearch相较于现有的mRAG方法表现更为优异。
目前OmniSearch在魔搭社区还有demo可玩。
动态检索规划框架,打破传统mRAG局限传统mRAG方法遵循固定的检索流程,典型的步骤如下:
输入转化:接收多模态输入(例如图像+文本问题),将图像转化为描述性文本(例如通过image caption模型)。单一模态检索:将问题或描述性文本作为检索查询,向知识库发送单一模态检索请求(通常是文本检索)。固定生成流程:将检索到的信息与原始问题结合,交由MLLM生成答案。OmniSearch旨在解决传统mRAG方法的以下痛点:
静态检索策略的局限:传统方法采用固定的两步检索流程,无法根据问题和检索内容动态调整检索路径,导致信息获取效率低下。检索查询过载:单一检索查询往往包含了多个查询意图,反而会引入大量无关信息,干扰模型的推理过程。为克服上述局限,OmniSearch引入了一种动态检索规划框架。

OmniSearch的核心架构包括:
规划智能体(Planning Agent):负责对原始问题进行逐步拆解,根据每个检索步骤的反馈决定下一步的子问题及检索策略。检索器(Retriever):执行实际的检索任务,支持图像检索、文本检索以及跨模态检索。子问题求解器(Sub-question Solver):对检索到的信息进行总结和解答,具备高度的可扩展性,可以与不同大小的多模态大语言模型集成。迭代推理与检索(Iterative Reasoning and Retrieval):通过递归式的检索与推理流程,逐步接近问题的最终答案。多模态特征的交互:有效处理文本、图像等多模态信息,灵活调整检索策略。反馈循环机制(Feedback Loop):在每一步检索和推理后,反思当前的检索结果并决定下一步行动,以提高检索的精确度和有效性。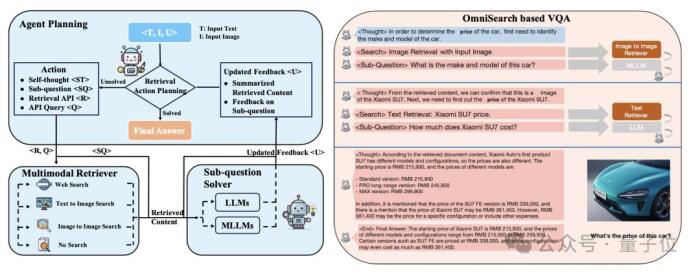 构建新数据集进行实验评估
构建新数据集进行实验评估为了更好地评估OmniSearch和其它mRAG方法的性能,研究团队构建了全新的Dyn-VQA数据集。Dyn-VQA包含1452个动态问题,涵盖了以下三种类型:
答案快速变化的问题:这类问题的背景知识不断更新,需要模型具备动态的再检索能力。例如,询问某位明星的最新电影票房,答案会随着时间的推移而发生变化。多模态知识需求的问题:问题需要同时从多模态信息(如图像、文本等)中获取知识。例如,识别一张图片中的球员,并回答他的球队图标是什么。多跳问题:问题需要多个推理步骤,要求模型在检索后进行多步推理。这些类型的问题相比传统的VQA数据集需要更复杂的检索流程,更考验多模态检索方法对复杂检索的规划能力。
 在Dyn-VQA数据集上的表现答案更新频率:对于答案快速变化的问题,OmniSearch的表现显著优于GPT-4V结合启发式mRAG方法,准确率提升了近88%。多模态知识需求:OmniSearch能够有效地结合图像和文本进行检索,其在需要额外视觉知识的复杂问题上的表现远超现有模型,准确率提高了35%以上。多跳推理问题:OmniSearch通过多次检索和动态规划,能够精确解决需要多步推理的问题,实验结果表明其在这类问题上的表现优于当前最先进的多模态模型,准确率提升了约35%。
在Dyn-VQA数据集上的表现答案更新频率:对于答案快速变化的问题,OmniSearch的表现显著优于GPT-4V结合启发式mRAG方法,准确率提升了近88%。多模态知识需求:OmniSearch能够有效地结合图像和文本进行检索,其在需要额外视觉知识的复杂问题上的表现远超现有模型,准确率提高了35%以上。多跳推理问题:OmniSearch通过多次检索和动态规划,能够精确解决需要多步推理的问题,实验结果表明其在这类问题上的表现优于当前最先进的多模态模型,准确率提升了约35%。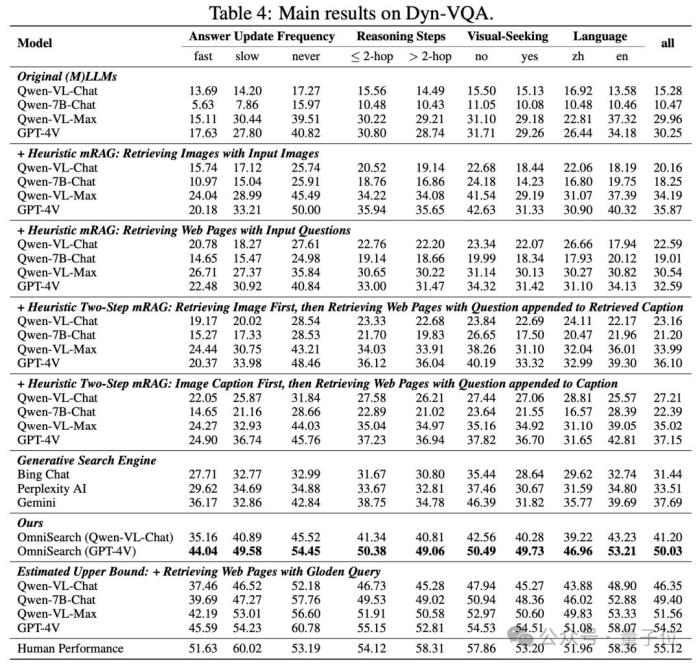 在其它数据集上的表现
在其它数据集上的表现接近人类级别表现:
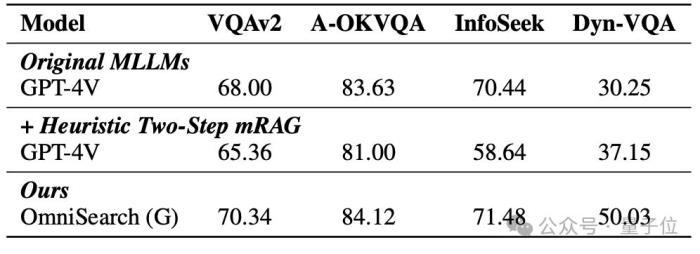
OmniSearch在大多数VQA任务上达到了接近人类水平的表现。例如,在VQAv2和A-OKVQA数据集中,OmniSearch的准确率分别达到了70.34和84.12,显著超越了传统mRAG方法。
复杂问题处理能力:
在更具挑战性的Dyn-VQA数据集上,OmniSearch通过多步检索策略显著提升了模型的表现,达到了50.03的F1-Recall评分,相比基于GPT-4V的传统两步检索方法提升了近14分。
 模块化能力与可扩展性
模块化能力与可扩展性OmniSearch可以灵活集成不同规模和类型的多模态大语言模型(MLLM)作为子问题求解器。
无论是开源模型(如Qwen-VL-Chat)还是闭源模型(如GPT-4V),OmniSearch都能通过动态规划与这些模型协作完成复杂问题的解决。
它的模块化设计允许根据任务需求选择最合适的模型,甚至在不同阶段调用不同大小的MLLM,以在性能和计算成本之间实现灵活平衡。
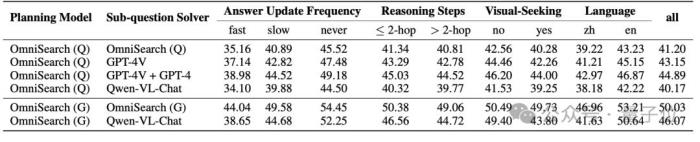
下面是OmniSearch和不同模型配合的实验结果:
Paper:
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










