

 新火种
2024-11-30
新火种
2024-11-30 

科研党狂喜!AI预测神经学研究结论超过人类专家水平|Nature子刊
奇月 发自 凹非寺新火种 | 公众号 QbitAI

 LLM预测能力全面超越人类专家
LLM预测能力全面超越人类专家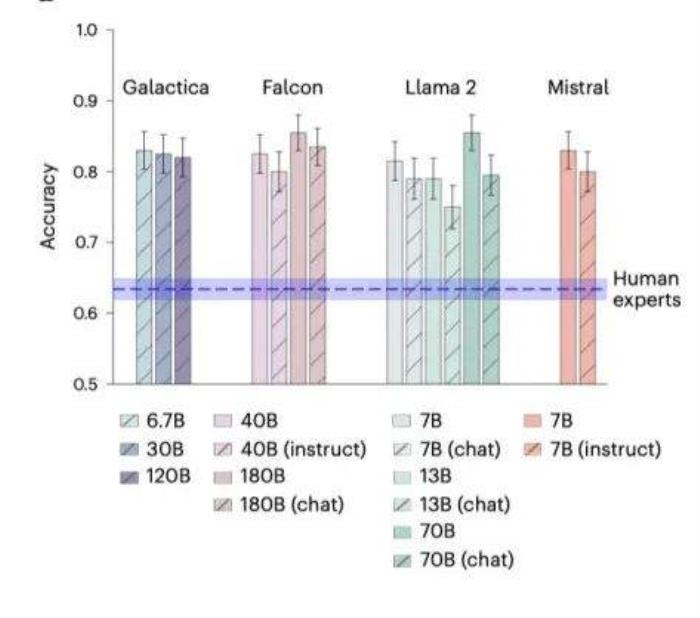
 评估LLM是否纯记忆
评估LLM是否纯记忆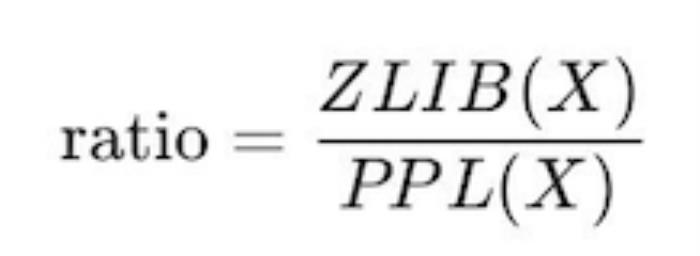


LLM可以比科学家更准确地预测神经学的研究结果!
最近,来自伦敦大学学院、剑桥大学、牛津大学等机构的团队发布了一个神经学专用基准BrainBench,登上了Nature子刊《自然人类行为(Nature human behavior)》。
结果显示,经过该基准训练的LLM在预测神经科学结果的准确度方面高达81.4%,远超人类专家的63%。
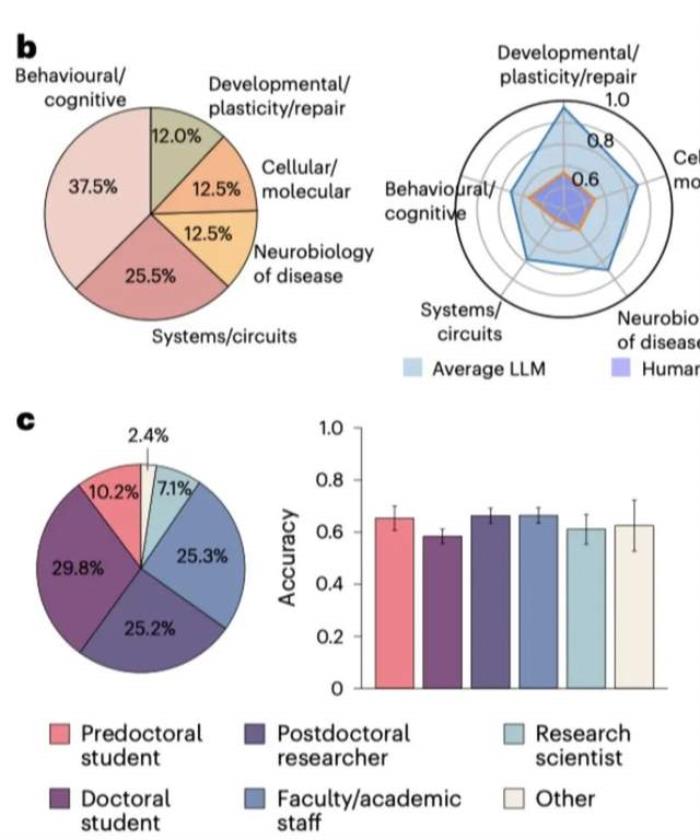
在神经学常见的5个子领域:行为/认知、细胞/分子、系统/回路、神经疾病的神经生物学以及发育/塑性和修复中,LLM的表现也都全方位超过了人类专家。
更重要的是,这些模型被证实对于数据没有明显的记忆。
也就是说,它们已经掌握了一般科研的普遍模式,可以做更多的前瞻性(Forward-looking)预测、预测未知的事物。
这立马引发科研圈的围观。
多位教授和博士后博士后也表示,以后就可以让LLM帮忙判断更多研究的可行性了,nice!
LLM预测能力全面超越人类专家让我们先来看看论文的几个重要结论:
总体结果:LLMs在BrainBench上的平均准确率为81.4%,而人类专家的平均准确率63.4%。LLMs的表现显著优于人类专家
子领域表现:在神经科学的几个重要的子领域:行为/认知、细胞/分子、系统/回路、神经疾病的神经生物学以及发育/塑性和修复中,LLMs在每个子领域的表现均优于人类专家,特别是在行为认知和系统/回路领域。
模型对比:较小的模型如Llama2-7B和Mistral-7B与较大的模型表现相当,而聊天或指令优化模型的表现不如其基础模型。
人类专家的表现:大多数人类专家是博士学生、博士后研究员或教职员工。当限制人类响应为自我报告专业知识的最高20%时,准确率上升到66.2%,但仍低于LLMS。
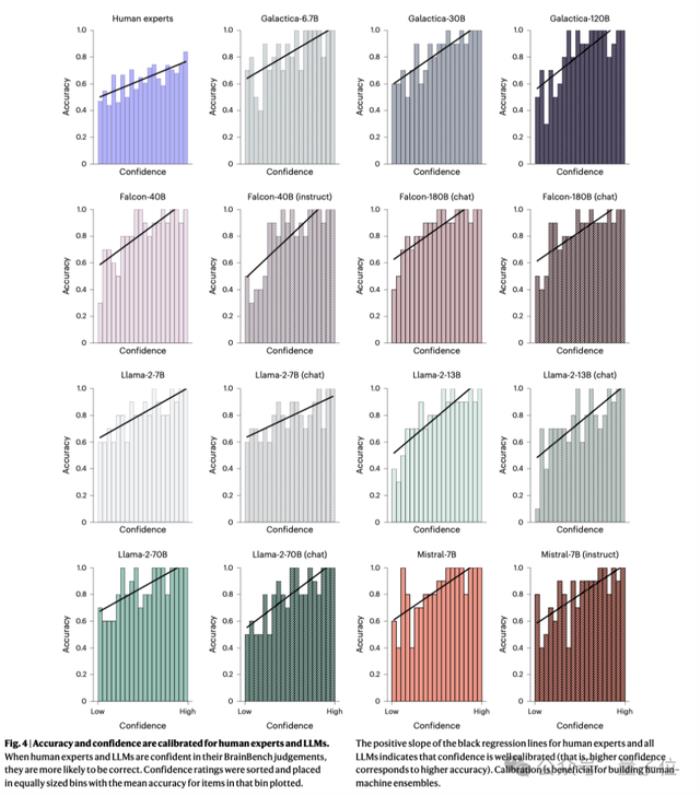
置信度校准:LLMs和人类专家的置信度都校准良好,高置信度的预测更有可能是正确的。
记忆评估:没有迹象表明LLMs记忆了BrainBench项目。使用zlib压缩率和困惑度比率的分析表明,LLMs学习的是广泛的科学模式,而不是记忆训练数据。
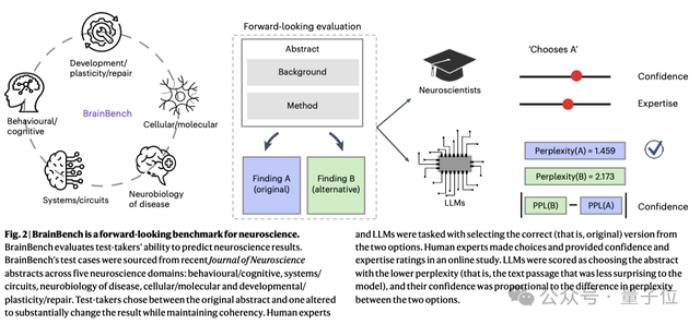
全新神经学基准本论文的一个重要贡献,就是提出了一个前瞻性的基准测试BrainBench,可以专门用于评估LLM在预测神经科学结果方面的能力。
那么,具体是怎么做到的呢?
数据收集首先,团队利用PubMed获取了2002年至2022年间332807篇神经科学研究相关的摘要,从PubMed Central Open Access Subset(PMC OAS)中提取了123085篇全文文章,总计13亿个tokens。
评估LLM和人类专家其次,在上面收集的数据的基础上,团队为BrainBench创建了测试用例,主要通过修改论文摘要来实现。
具体来说,每个测试用例包括两个版本的摘要:一个是原始版本,另一个是经过修改的版本。修改后的摘要会显著改变研究结果,但保持整体连贯性。
测试者的任务是选择哪个版本包含实际的研究结果。
团队使用Eleuther Al Language Model EvaluationHaress框架,让LLM在两个版本的摘要之间进行选择,通过困惑度(perplexity)来衡量其偏好。困惑度越低,表示模型越喜欢该摘要。
对人类专家行为的评估也是在相同测试用例上进行选择,他们还需要提供自信度和专业知识评分。最终参与实验的神经科学专家有171名。
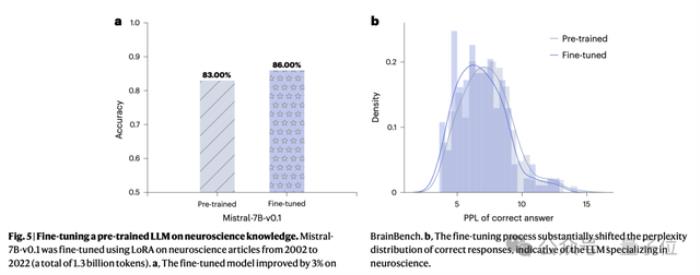
实验使用的LLM是经过预训练的Mistral-7B-v0.1模型。通过LoRA技术进行微调后,准确度还能再增加3%。
评估LLM是否纯记忆为了衡量LLM是否掌握了思维逻辑,团队还使用zlib压缩率和困惑度比率来评估LLMs是否记忆了训练数据。公式如下:
其中,ZLIB(X)表示文本X的zlib压缩率,PPL(X)表示文本X的困惑度。
部分研究者认为只能当作辅助这篇论文向我们展示了神经科学研究的一个新方向,或许未来在前期探索的时候,神经学专家都可以借助LLM的力量进行初步的科研想法筛选,剔除一些在方法、背景信息等方面存在明显问题的计划等。
但同时也有很多研究者对LLM的这个用法表示了质疑。
有人认为实验才是科研最重要的部分,任何预测都没什么必要:
还有研究者认为科研的重点可能在于精确的解释。
此外,也有网友指出实验中的测试方法只考虑到了简单的AB假设检验,真实研究中还有很多涉及到平均值/方差的情况。
整体来看,这个研究对于神经学科研工作的发展还是非常有启发意义的,未来也有可能扩展到更多的学术研究领域。
研究人员们怎么看呢?
参考链接:
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










