

 新火种
2024-11-27
新火种
2024-11-27 

撞墙还是新起点?自回归模型在图像领域展现出Scaling潜力
自回归方法,在图像生成中观察到了 Scaling Law。 还有人指出,其实,在文本以外的领域,Scaling Law 的踪迹正在逐渐显现,比如时间序列预测以及图像、视频这类视觉领域。下面这张图来自投稿给 ICLR 2025 的一篇论文。论文发现,在把类似于 GPT 的自回归模型应用于图像生成时,Scaling Law 同样可以被观察到。具体表现为:随着模型大小的增加,训练损失会降低,模型生成性能会提高,捕捉全局信息的能力也会增强。
还有人指出,其实,在文本以外的领域,Scaling Law 的踪迹正在逐渐显现,比如时间序列预测以及图像、视频这类视觉领域。下面这张图来自投稿给 ICLR 2025 的一篇论文。论文发现,在把类似于 GPT 的自回归模型应用于图像生成时,Scaling Law 同样可以被观察到。具体表现为:随着模型大小的增加,训练损失会降低,模型生成性能会提高,捕捉全局信息的能力也会增强。 论文标题:Elucidating the design space of language models for image generation论文链接:https://arxiv.org/pdf/2410.16257代码与模型:https://github.com/Pepper-lll/LMforImageGeneration论文作者之一、云天励飞的齐宪标博士在接受机器之心采访时表示:「我们不知道图像中的 Scaling Law 到底有多强,比如如果我们把图像生成模型也扩展到 Llama 7B 这个规模,是不是 GPT 那样的自回归方法也具有非常大的潜力?」抱着这个想法,他们进行了一些初步实验,发现只训练到一半的时候,自回归模型就已经在图像生成任务上表现出了很强的 Scaling Law。这让他们对自回归方法在视觉领域的应用充满信心。可见,至少在图像和视频生成等领域,Scaling Law 依然强势,离撞墙还远。在另一篇论文中,齐宪标等人还发现,其实在应用于图像领域时,传统的自回归方法也有改进空间。他们把改进后的方法称为「BiGR 」,该方法建立在何恺明等人 MAR(masked autoregressive)工作的基础之上,并在一些方面实现了改进,成为了首个将生成和判别任务统一在同一框架内的条件生成模型。这意味着,BiGR 不仅是一个好的图像生成器,同时还是一个强大的特征提取器,二者是相互促进的关系。
论文标题:Elucidating the design space of language models for image generation论文链接:https://arxiv.org/pdf/2410.16257代码与模型:https://github.com/Pepper-lll/LMforImageGeneration论文作者之一、云天励飞的齐宪标博士在接受机器之心采访时表示:「我们不知道图像中的 Scaling Law 到底有多强,比如如果我们把图像生成模型也扩展到 Llama 7B 这个规模,是不是 GPT 那样的自回归方法也具有非常大的潜力?」抱着这个想法,他们进行了一些初步实验,发现只训练到一半的时候,自回归模型就已经在图像生成任务上表现出了很强的 Scaling Law。这让他们对自回归方法在视觉领域的应用充满信心。可见,至少在图像和视频生成等领域,Scaling Law 依然强势,离撞墙还远。在另一篇论文中,齐宪标等人还发现,其实在应用于图像领域时,传统的自回归方法也有改进空间。他们把改进后的方法称为「BiGR 」,该方法建立在何恺明等人 MAR(masked autoregressive)工作的基础之上,并在一些方面实现了改进,成为了首个将生成和判别任务统一在同一框架内的条件生成模型。这意味着,BiGR 不仅是一个好的图像生成器,同时还是一个强大的特征提取器,二者是相互促进的关系。 论文标题:BiGR: Harnessing Binary Latent Codes for Image Generation and Improved Visual Representation Capabilities论文链接:https://arxiv.org/pdf/2410.14672代码与模型:https://github.com/haoosz/BiGR这些工作为研究界继续探索自回归模型在视觉领域的 Scaling Law 提供了一些启发。在这篇文章中,我们将对这些工作进行深入解读。顺带一提,这两项研究的代码和模型都已发布。自回归:Diffusion 之外的另一条道路在当前的视觉生成领域,Diffusion 模型是毫无疑问的霸主。这种方法生成的图像质量较高,视频也越来越好。但另一方面,以 Transformer 为代表的自回归模型在文本领域的成功就在眼前,这不禁让人去想象自回归模型在视觉领域的可能性。其实,早在 2018 年,谷歌的一个团队(其中大部分是 Transformer 论文作者)就已经探索过用自回归模型来生成图像(参见论文《Image Transformer》)。OpenAI 的初代 DALL・E 模型用的也是基于自回归的方法。但由于探索初期效果不佳,再加上 Diffusion 模型的强势崛起和开源,基于自回归的方法逐渐淡出了大部分研究者的视野。
论文标题:BiGR: Harnessing Binary Latent Codes for Image Generation and Improved Visual Representation Capabilities论文链接:https://arxiv.org/pdf/2410.14672代码与模型:https://github.com/haoosz/BiGR这些工作为研究界继续探索自回归模型在视觉领域的 Scaling Law 提供了一些启发。在这篇文章中,我们将对这些工作进行深入解读。顺带一提,这两项研究的代码和模型都已发布。自回归:Diffusion 之外的另一条道路在当前的视觉生成领域,Diffusion 模型是毫无疑问的霸主。这种方法生成的图像质量较高,视频也越来越好。但另一方面,以 Transformer 为代表的自回归模型在文本领域的成功就在眼前,这不禁让人去想象自回归模型在视觉领域的可能性。其实,早在 2018 年,谷歌的一个团队(其中大部分是 Transformer 论文作者)就已经探索过用自回归模型来生成图像(参见论文《Image Transformer》)。OpenAI 的初代 DALL・E 模型用的也是基于自回归的方法。但由于探索初期效果不佳,再加上 Diffusion 模型的强势崛起和开源,基于自回归的方法逐渐淡出了大部分研究者的视野。 初代 DALL・E 生成效果云天励飞的这些研究更像是一种「重新探索」,而且这次探索有很多可以借鉴的经验教训。正如齐宪标说的那样:「在我们重新探索这条路的时候,这些经验其实可以让我们思考过去走这条路的时候可能哪个地方没走好。」关于这种「重新探索」的动机,齐宪标分享了几个观点。第一个是关于 Scaling Law 的。正如前面所提到的,自回归方法的可扩展性已经在文本领域得到了验证,最大的文本模型已经做到了万亿参数。而在图像领域,这种 Scaling Law 才刚刚显现,未来还存在巨大的探索空间。第二个是关于多模态理解和生成的统一。在当前「scaling law 撞墙」的相关讨论中,多模态其实是一个被寄予厚望的方向。但是,这个领域目前面临一个严峻的挑战,即多模态的理解和生成是分开进行的,这就造成理解模型的理解能力强而生成能力弱,生成模型则相反。统一这两类任务,可以促进模型学到更通用的语义表征,还能让模型更好地探索数据中的潜在规律,从而增强模型在跨模态任务中的泛化性。而自回归方法的好处就在于它有一个 token 化的过程。无论什么模态,只要经过了 token 化,生成和理解就可以很容易被统一在一个框架里面。相比之下,基于 Diffusion 的方法就缺乏这种灵活性。除此之外,自回归方法用于视觉任务还有很多好处,比如模型指令遵循能力更强,之前在文本模型领域积累的经验、资源可以复用等等。这些原因驱使齐宪标和他的同事跳出 Diffusion 这条「主路」,走回了自回归这条已经相对冷门的路线。在图像上 Scaling 有效以及生成和判别的统一要理解 BiGR 和 ELM 的意义,我们得从离散化的图像和文本的 token 分布谈起。齐宪标表示:「我们得把一个图像块表示成一个单词。如果只是单纯的硬编码,我们是做不到的,因为它的空间太大了。所以,我们首先就是想办法来表示图像。这也就是所谓的 token 化。」
初代 DALL・E 生成效果云天励飞的这些研究更像是一种「重新探索」,而且这次探索有很多可以借鉴的经验教训。正如齐宪标说的那样:「在我们重新探索这条路的时候,这些经验其实可以让我们思考过去走这条路的时候可能哪个地方没走好。」关于这种「重新探索」的动机,齐宪标分享了几个观点。第一个是关于 Scaling Law 的。正如前面所提到的,自回归方法的可扩展性已经在文本领域得到了验证,最大的文本模型已经做到了万亿参数。而在图像领域,这种 Scaling Law 才刚刚显现,未来还存在巨大的探索空间。第二个是关于多模态理解和生成的统一。在当前「scaling law 撞墙」的相关讨论中,多模态其实是一个被寄予厚望的方向。但是,这个领域目前面临一个严峻的挑战,即多模态的理解和生成是分开进行的,这就造成理解模型的理解能力强而生成能力弱,生成模型则相反。统一这两类任务,可以促进模型学到更通用的语义表征,还能让模型更好地探索数据中的潜在规律,从而增强模型在跨模态任务中的泛化性。而自回归方法的好处就在于它有一个 token 化的过程。无论什么模态,只要经过了 token 化,生成和理解就可以很容易被统一在一个框架里面。相比之下,基于 Diffusion 的方法就缺乏这种灵活性。除此之外,自回归方法用于视觉任务还有很多好处,比如模型指令遵循能力更强,之前在文本模型领域积累的经验、资源可以复用等等。这些原因驱使齐宪标和他的同事跳出 Diffusion 这条「主路」,走回了自回归这条已经相对冷门的路线。在图像上 Scaling 有效以及生成和判别的统一要理解 BiGR 和 ELM 的意义,我们得从离散化的图像和文本的 token 分布谈起。齐宪标表示:「我们得把一个图像块表示成一个单词。如果只是单纯的硬编码,我们是做不到的,因为它的空间太大了。所以,我们首先就是想办法来表示图像。这也就是所谓的 token 化。」 图像的 token 化通常需要一个编码器 ENC、一个量化算法 QUANT 和一个解码器 DEC。目前,主流的图像 token 化方案有两种:VQGAN 和 BAE;它们的主要区别是离散化隐向量的方式 。经过 token 化处理之后,图像也就变成了类似文本的 token 序列。如此一来,理论上看,自回归(AR)模型和掩码式语言模型(MLM)等用于建模文本的方法也就可以用于处理图像了。即便如此,经过离散和 token 化处理的图像序列与文本序列之间依然存在固有的差异。下表给出了 ImageNet、OpenWebText 和 Shakespeare(后两个是文本数据集)的 token 分布的 KL 距离。
图像的 token 化通常需要一个编码器 ENC、一个量化算法 QUANT 和一个解码器 DEC。目前,主流的图像 token 化方案有两种:VQGAN 和 BAE;它们的主要区别是离散化隐向量的方式 。经过 token 化处理之后,图像也就变成了类似文本的 token 序列。如此一来,理论上看,自回归(AR)模型和掩码式语言模型(MLM)等用于建模文本的方法也就可以用于处理图像了。即便如此,经过离散和 token 化处理的图像序列与文本序列之间依然存在固有的差异。下表给出了 ImageNet、OpenWebText 和 Shakespeare(后两个是文本数据集)的 token 分布的 KL 距离。 基于此,可以得到两点观察:图像数据缺乏语言数据常有的那种内在结构和序列顺序。这种图像 token 分布的随机性表明图像生成并不依赖严格的序列模式。接近均匀的 token 分布表明生成任务对错误的容忍度更高。由于所有 token 的概率几乎相等,因此该模型可以容忍不太精确的 token 预测,同时还不会显著影响输出的质量。基于这些观察和进一步的实验,云天励飞得到了一个结论:在图像生成方面,自回归(AR)方法并不比掩码式语言模型(MLM)差,甚至可能还更好一点。虽然在语言领域,AR 优于 MLM 已经得到了许多研究成果的验证(实际上当今的大多数 LLM 都是 AR 范式),但在图像领域,这算是一个有些让人意外的结果,毕竟掩码机制似乎和图像任务有着天然的亲和力。在此基础上,云天励飞团队更进一步,初步发现了 AR 模型在图像生成任务上的 Scaling Law。越大越强,AR 或在图像生成上再次成功Scaling Law 的概念其实并不复杂,简单总结起来就是模型越大越好,数据越多越好,算力越强越好。研究 Scaling Law 之所以重要,是因为这能为后续的研究探索指引方向。在此之前,虽然已经有不少研究团队尝试过使用 Transformer 来生成图像,但还少有人严肃地探索过自回归 Transformer 在图像生成任务上的 Scaling Law。
基于此,可以得到两点观察:图像数据缺乏语言数据常有的那种内在结构和序列顺序。这种图像 token 分布的随机性表明图像生成并不依赖严格的序列模式。接近均匀的 token 分布表明生成任务对错误的容忍度更高。由于所有 token 的概率几乎相等,因此该模型可以容忍不太精确的 token 预测,同时还不会显著影响输出的质量。基于这些观察和进一步的实验,云天励飞得到了一个结论:在图像生成方面,自回归(AR)方法并不比掩码式语言模型(MLM)差,甚至可能还更好一点。虽然在语言领域,AR 优于 MLM 已经得到了许多研究成果的验证(实际上当今的大多数 LLM 都是 AR 范式),但在图像领域,这算是一个有些让人意外的结果,毕竟掩码机制似乎和图像任务有着天然的亲和力。在此基础上,云天励飞团队更进一步,初步发现了 AR 模型在图像生成任务上的 Scaling Law。越大越强,AR 或在图像生成上再次成功Scaling Law 的概念其实并不复杂,简单总结起来就是模型越大越好,数据越多越好,算力越强越好。研究 Scaling Law 之所以重要,是因为这能为后续的研究探索指引方向。在此之前,虽然已经有不少研究团队尝试过使用 Transformer 来生成图像,但还少有人严肃地探索过自回归 Transformer 在图像生成任务上的 Scaling Law。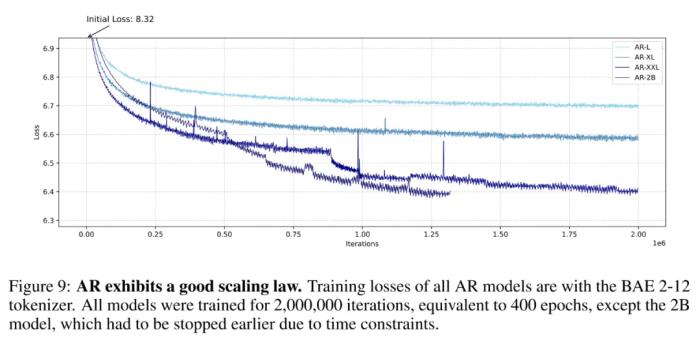 自回归模型的 Scaling Law,其中 2B 模型由于时间限制并未完成 200 万次迭代,但其趋势依然很明显云天励飞的这项研究无疑是一支强心剂。具体来说,他们发现,随着模型规模增大,AR 模型在图像生成任务上的训练损失越低、生成性能越好、也能更好地捕获图像中的全局信息。他们基于这些观察构建了一个可生成图像的阐述式语言模型(ELM/elucidate language model),并在 ImageNet 256×256 基准上实现了 SOTA。
自回归模型的 Scaling Law,其中 2B 模型由于时间限制并未完成 200 万次迭代,但其趋势依然很明显云天励飞的这项研究无疑是一支强心剂。具体来说,他们发现,随着模型规模增大,AR 模型在图像生成任务上的训练损失越低、生成性能越好、也能更好地捕获图像中的全局信息。他们基于这些观察构建了一个可生成图像的阐述式语言模型(ELM/elucidate language model),并在 ImageNet 256×256 基准上实现了 SOTA。 ELM-2B 生成的一些不同类别的图像至于注意力模式,不同大小的模型的差别倒是不大:L 大小的模型主要关注局部信息,难以捕获长程信息。相较之下,更大的 XL 和 XXL 模型的某些层表现出了更长程的注意力,这说明它们也能学习全局特征。为了进一步确认 AR 模型确实能理解图像任务,该团队对不同 AR 模型的注意力图(attention map)进行了可视化,结果发现其注意力机制确实会关注图像的某些局部区域,这说明自回归 Transformer 模型确实可以有效学习局部模式对于图像生成的重要性。这一结果又进一步凸显了自回归 Transformer 在不同领域的强大性能。
ELM-2B 生成的一些不同类别的图像至于注意力模式,不同大小的模型的差别倒是不大:L 大小的模型主要关注局部信息,难以捕获长程信息。相较之下,更大的 XL 和 XXL 模型的某些层表现出了更长程的注意力,这说明它们也能学习全局特征。为了进一步确认 AR 模型确实能理解图像任务,该团队对不同 AR 模型的注意力图(attention map)进行了可视化,结果发现其注意力机制确实会关注图像的某些局部区域,这说明自回归 Transformer 模型确实可以有效学习局部模式对于图像生成的重要性。这一结果又进一步凸显了自回归 Transformer 在不同领域的强大性能。 AR 模型的注意力图,可以明显看到其中对局部模式的关注掩码式 AR:判别与生成任务的创新性统一云天励飞在另一项研究中更深度地探索了 AR 模型在图像领域的可能性。这一次,AR 模型不仅被用来执行图像生成任务,还在图像判别任务上大展拳脚。
AR 模型的注意力图,可以明显看到其中对局部模式的关注掩码式 AR:判别与生成任务的创新性统一云天励飞在另一项研究中更深度地探索了 AR 模型在图像领域的可能性。这一次,AR 模型不仅被用来执行图像生成任务,还在图像判别任务上大展拳脚。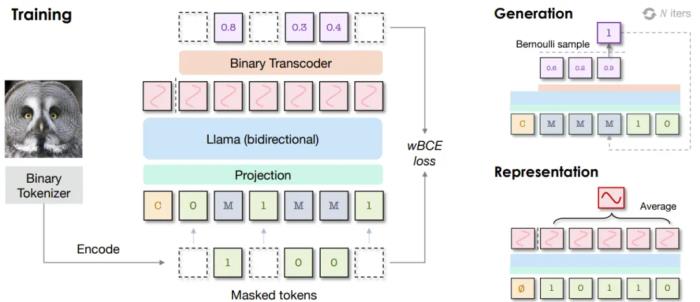 BiGR 框架的简化示意图为此,他们构建了一个名为 BiGR 的新框架。该框架包含 3 个主要组件:一个二元 token 化器,其作用是将像素图像转换成二元隐码构成的序列;一个仅解码器 Transformer,并配备了完整的双向注意力;一个二元转码器(binary transcoder),作用是将连续特征转换成伯努利分布的二元编码。不仅如此,BiGR 的训练完全是重建 token 的生成过程,无需依赖任何判别损失。那 BiGR 是如何将图像的生成与判别统一在一起的呢?其关键在于掩码机制与自回归模型的深度融合!具体来说,他们使用的骨干网络是基于 Transformer 的语言模型 Llama。由于图像和文本 token 的不同性质,他们没有使用语言模型常用的因果注意力,而是使用了双向注意力。模型的预测目标也不再是下一 token,而是被遮掩的 token。在输入空间,他们的做法也不再是查找有某个 token 索引的嵌入向量,而是使用一个简单的线性层来将二元编码投射到嵌入空间。在训练过程中,会使用一个可学习的掩码 token 遮蔽掉一部分图像 token。然后仅计算被遮蔽位置的损失,其中模型的预测目标是被遮掩的 token 的值。之后,再使用二元转码器,通过一个伯努利扩散过程,将模型的输出转换成二元编码。而在训练时,语言模型和扩散网络是联合优化的。训练完成后,模型本身就会具备强大的视觉表征能力:对于输入的图像,可以不带任何掩码地提供给模型,并附加一个无条件 token。然后,在连续值的特征上执行平均池化,推断给定图像的全局表征。他们得到了一个有趣的观察:最具判别性的表征还不是来自最后一层,而是 Transformer 模块内的中间层!因此,他们便将这些中间特征用作了最终的图像表征。对于图像生成任务,他们设计了一种采样策略,使模型可以根据完全掩蔽的序列迭代地预测 token。不同于训练阶段(每一步的掩码位置都是随机选取的),在采样阶段,会按照一个预定义的标准按顺序去除 token 的掩码。最终得到的模型可说是图像生成能力与判别能力俱佳,算是首个做到这一点的条件生成模型,并且同时还具备统一、高效、灵活、可扩展四大优势。
BiGR 框架的简化示意图为此,他们构建了一个名为 BiGR 的新框架。该框架包含 3 个主要组件:一个二元 token 化器,其作用是将像素图像转换成二元隐码构成的序列;一个仅解码器 Transformer,并配备了完整的双向注意力;一个二元转码器(binary transcoder),作用是将连续特征转换成伯努利分布的二元编码。不仅如此,BiGR 的训练完全是重建 token 的生成过程,无需依赖任何判别损失。那 BiGR 是如何将图像的生成与判别统一在一起的呢?其关键在于掩码机制与自回归模型的深度融合!具体来说,他们使用的骨干网络是基于 Transformer 的语言模型 Llama。由于图像和文本 token 的不同性质,他们没有使用语言模型常用的因果注意力,而是使用了双向注意力。模型的预测目标也不再是下一 token,而是被遮掩的 token。在输入空间,他们的做法也不再是查找有某个 token 索引的嵌入向量,而是使用一个简单的线性层来将二元编码投射到嵌入空间。在训练过程中,会使用一个可学习的掩码 token 遮蔽掉一部分图像 token。然后仅计算被遮蔽位置的损失,其中模型的预测目标是被遮掩的 token 的值。之后,再使用二元转码器,通过一个伯努利扩散过程,将模型的输出转换成二元编码。而在训练时,语言模型和扩散网络是联合优化的。训练完成后,模型本身就会具备强大的视觉表征能力:对于输入的图像,可以不带任何掩码地提供给模型,并附加一个无条件 token。然后,在连续值的特征上执行平均池化,推断给定图像的全局表征。他们得到了一个有趣的观察:最具判别性的表征还不是来自最后一层,而是 Transformer 模块内的中间层!因此,他们便将这些中间特征用作了最终的图像表征。对于图像生成任务,他们设计了一种采样策略,使模型可以根据完全掩蔽的序列迭代地预测 token。不同于训练阶段(每一步的掩码位置都是随机选取的),在采样阶段,会按照一个预定义的标准按顺序去除 token 的掩码。最终得到的模型可说是图像生成能力与判别能力俱佳,算是首个做到这一点的条件生成模型,并且同时还具备统一、高效、灵活、可扩展四大优势。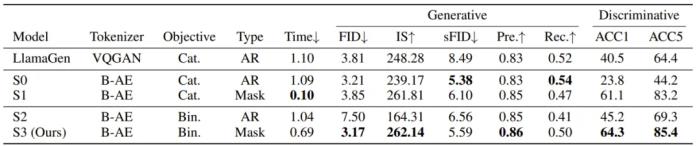 从上表的结果中我们可以得出以下结论:通过比较 LlamaGen 和 S0,可知相比于使用 VQGAN,使用二元自动编码器可以带来更好的生成性能,但判别性能会下降一些。对于生成任务,AR 建模更适合分类损失,而掩码建模更适合二元损失。对于判别任务,不管哪种损失,掩码建模都大幅优于 AR 建模,而二元损失能进一步提升性能。与 AR 建模相比,掩码建模由于采样迭代次数较少,因此推理速度明显更快,而二元目标的扩散过程需要更多时间。这种生成与判别的统一能带来什么好处呢?齐宪标举了两个例子,如果我们想让模型生成一张「飞翔的熊猫」图,那么这种自回归 Transformer 方法可以直接完成从语言理解到图像生成的全过程,而无需调用 Stable Diffusion 等外部接口。另外,它也能帮助我们理解并进一步加工图像,比如可以在多张图片中找到我们想要的文本信息并将其抹除。
从上表的结果中我们可以得出以下结论:通过比较 LlamaGen 和 S0,可知相比于使用 VQGAN,使用二元自动编码器可以带来更好的生成性能,但判别性能会下降一些。对于生成任务,AR 建模更适合分类损失,而掩码建模更适合二元损失。对于判别任务,不管哪种损失,掩码建模都大幅优于 AR 建模,而二元损失能进一步提升性能。与 AR 建模相比,掩码建模由于采样迭代次数较少,因此推理速度明显更快,而二元目标的扩散过程需要更多时间。这种生成与判别的统一能带来什么好处呢?齐宪标举了两个例子,如果我们想让模型生成一张「飞翔的熊猫」图,那么这种自回归 Transformer 方法可以直接完成从语言理解到图像生成的全过程,而无需调用 Stable Diffusion 等外部接口。另外,它也能帮助我们理解并进一步加工图像,比如可以在多张图片中找到我们想要的文本信息并将其抹除。 BiGR 的一些生成结果而通过实验不同大小的模型,我们同样看见了 Scaling Law 存在的踪迹。
BiGR 的一些生成结果而通过实验不同大小的模型,我们同样看见了 Scaling Law 存在的踪迹。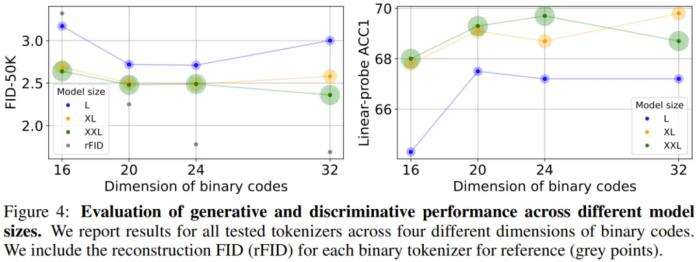 虽然云天励飞的论文中没有明说,但 Transformer 在这些不同视觉任务的成功或许意味着,在众说纷纭、似乎即将到来的 AGI 中,自回归 Transformer 或许至少有一席之地。当然,自回归范式在图像领域的成功也并非对 Diffusion 的否定,正如齐宪标说的那样:「基于自回归的方法的一个特别大的特点是它的指令服从能力非常强,而基于 Diffusion 的方法的生成质量可能更高,细节会更丰富一些,但是它对于指令的控制能力有的时候会偏弱一些。」另外,也应当指出,基于时间和成本的考量,这两项研究更侧重于对前沿技术和可能性的探索,想要开发基于 Transformer 的图像生成应用,还有待进一步的工程开发。而相关的 Scaling Law 也有待进一步的探索完善,比如,齐宪标指出,基于自回归方法和基于 Diffusion 方法的 Scaling Law 之间的差异就是一个非常有价值的研究课题。「我更想知道 transformer 为什么会 work」将自回归模型应用于视觉生成并不是一条拥挤的赛道,因为众所周知,想要跑通这条路线需要克服很多难点,比如生成速度慢、长程依赖难建模、高分辨率扩展性差、生成质量受限等。但出于对 Scaling Law 探索的渴望,云天励飞的研究团队依然选择走出了这一步。这可能也是非常有前瞻性的一步。这种前瞻性一方面与公司的人才密度(研发人员占公司总人数比例高达64.08%)密不可分,另一方面也在于公司给予人才的探索空间和算力支持(千亿参数模型训练能力)。齐宪标提到,这几点其实也是他当初选择云天励飞的关键原因。此外,齐宪标还谈到了自己颇为敬佩的云天励飞首席科学家、曾在微软工作 17 年的算法大牛肖嵘,称肖嵘是一个对公司整体战略把握非常清晰,同时又喜欢追问技术细节的人,比如他会让大家把学习曲线拉出来,看看 loss 为什么会飞掉,学习率设置对不对,数据有没有清洗干净。在这样的团队氛围中,云天励飞近年来在多个方向取得了一些研究成果,其中包括多项对大模型加速的工作这些工作探索了大模型端侧加速的方法,能够大大提升大模型端侧部署推理速度。考虑到云天励飞本身就有自有芯片,所以可为大模型的端侧落地提供「软硬一体的解决方案」。同时,云天励飞科研团队还有多项研究成果投稿到 ICLR 2025 会议。其中有两项是关于Transformer 基础理论的研究。一项探索了大模型训练崩溃的根本原因,他们归结于
虽然云天励飞的论文中没有明说,但 Transformer 在这些不同视觉任务的成功或许意味着,在众说纷纭、似乎即将到来的 AGI 中,自回归 Transformer 或许至少有一席之地。当然,自回归范式在图像领域的成功也并非对 Diffusion 的否定,正如齐宪标说的那样:「基于自回归的方法的一个特别大的特点是它的指令服从能力非常强,而基于 Diffusion 的方法的生成质量可能更高,细节会更丰富一些,但是它对于指令的控制能力有的时候会偏弱一些。」另外,也应当指出,基于时间和成本的考量,这两项研究更侧重于对前沿技术和可能性的探索,想要开发基于 Transformer 的图像生成应用,还有待进一步的工程开发。而相关的 Scaling Law 也有待进一步的探索完善,比如,齐宪标指出,基于自回归方法和基于 Diffusion 方法的 Scaling Law 之间的差异就是一个非常有价值的研究课题。「我更想知道 transformer 为什么会 work」将自回归模型应用于视觉生成并不是一条拥挤的赛道,因为众所周知,想要跑通这条路线需要克服很多难点,比如生成速度慢、长程依赖难建模、高分辨率扩展性差、生成质量受限等。但出于对 Scaling Law 探索的渴望,云天励飞的研究团队依然选择走出了这一步。这可能也是非常有前瞻性的一步。这种前瞻性一方面与公司的人才密度(研发人员占公司总人数比例高达64.08%)密不可分,另一方面也在于公司给予人才的探索空间和算力支持(千亿参数模型训练能力)。齐宪标提到,这几点其实也是他当初选择云天励飞的关键原因。此外,齐宪标还谈到了自己颇为敬佩的云天励飞首席科学家、曾在微软工作 17 年的算法大牛肖嵘,称肖嵘是一个对公司整体战略把握非常清晰,同时又喜欢追问技术细节的人,比如他会让大家把学习曲线拉出来,看看 loss 为什么会飞掉,学习率设置对不对,数据有没有清洗干净。在这样的团队氛围中,云天励飞近年来在多个方向取得了一些研究成果,其中包括多项对大模型加速的工作这些工作探索了大模型端侧加速的方法,能够大大提升大模型端侧部署推理速度。考虑到云天励飞本身就有自有芯片,所以可为大模型的端侧落地提供「软硬一体的解决方案」。同时,云天励飞科研团队还有多项研究成果投稿到 ICLR 2025 会议。其中有两项是关于Transformer 基础理论的研究。一项探索了大模型训练崩溃的根本原因,他们归结于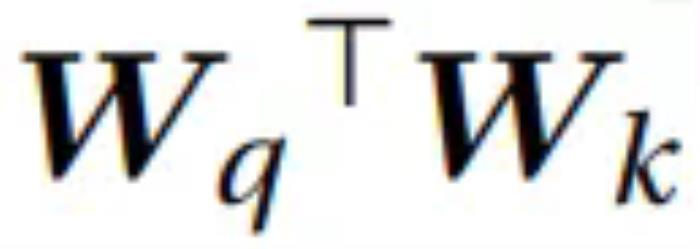 的谱能量集中。另外一项则是设计了高效且稳定的 Transformer 模块。「谷歌在训练 PaLM 模型的时候,训练的 loss 飞掉了 20 多次。Meta 训练 Llama 3 的时候因为各种问题崩溃了四百多次。这其中很多问题可能都跟我们对 Transformer 的底层理解有关。也就是说,我们对于 Transformer 的应用已经做了很多,但对 Transformer 理论的理解相对来说还不够透彻。我更想知道 Transformer 为什么会 work,为什么会出现问题。」齐宪标在谈及这个方向的研究动机时说道。结语这几天,关于 Scaling Law 是否撞墙的讨论还在继续,齐宪标显然并不认可 Scaling Law 已经撞墙的说法 —— 不管是图像还是文本,Scaling 都还能带来明显的提升。不过,他也指出,对于 Scaling Law 的探索注定是一项长期工作,需要从多个方向找突破口,云天励飞也将持续探索。据了解,今年云天励飞一直在强调「边缘 AI」战略。为此,他们选择了从软硬件两个方向同时前进,即 AI 芯片和大模型。在此基础上,他们进入了「算法芯片化」这一赛道。云天励飞表示,他们已经打造出了一些面向消费者、企业和城市的大模型相关产品和解决方案。据了解,今年底云天励飞还会推出两款基于大模型打造的智能硬件产品。2024 年被许多人称为「人工智能应用的真正元年」。AI 开始走出开发者和爱好者的圈子,向普罗大众更广泛地渗透。通过在底层技术创新和应用开发两方面持续发力,云天励飞能否在已然卷成红海的 AI 行业博取一块蛋糕?还有待进一步观察。不过,考虑云天励飞在 AI 的软件和硬件两方面都已经有了相当厚实的技术沉淀,做到这一点应该并不难。
的谱能量集中。另外一项则是设计了高效且稳定的 Transformer 模块。「谷歌在训练 PaLM 模型的时候,训练的 loss 飞掉了 20 多次。Meta 训练 Llama 3 的时候因为各种问题崩溃了四百多次。这其中很多问题可能都跟我们对 Transformer 的底层理解有关。也就是说,我们对于 Transformer 的应用已经做了很多,但对 Transformer 理论的理解相对来说还不够透彻。我更想知道 Transformer 为什么会 work,为什么会出现问题。」齐宪标在谈及这个方向的研究动机时说道。结语这几天,关于 Scaling Law 是否撞墙的讨论还在继续,齐宪标显然并不认可 Scaling Law 已经撞墙的说法 —— 不管是图像还是文本,Scaling 都还能带来明显的提升。不过,他也指出,对于 Scaling Law 的探索注定是一项长期工作,需要从多个方向找突破口,云天励飞也将持续探索。据了解,今年云天励飞一直在强调「边缘 AI」战略。为此,他们选择了从软硬件两个方向同时前进,即 AI 芯片和大模型。在此基础上,他们进入了「算法芯片化」这一赛道。云天励飞表示,他们已经打造出了一些面向消费者、企业和城市的大模型相关产品和解决方案。据了解,今年底云天励飞还会推出两款基于大模型打造的智能硬件产品。2024 年被许多人称为「人工智能应用的真正元年」。AI 开始走出开发者和爱好者的圈子,向普罗大众更广泛地渗透。通过在底层技术创新和应用开发两方面持续发力,云天励飞能否在已然卷成红海的 AI 行业博取一块蛋糕?还有待进一步观察。不过,考虑云天励飞在 AI 的软件和硬件两方面都已经有了相当厚实的技术沉淀,做到这一点应该并不难。
「Scaling Law 撞墙了?」这恐怕是 AI 社区最近讨论热度最高的话题。
该话题始于 The Information 的一篇文章。这篇文章透露,OpenAI 下一代旗舰模型的质量提升幅度不及前两款旗舰模型之间的质量提升,因为高质量文本和其他数据的供应量正在减少,原本的 Scaling Law(用更多的数据训练更大的模型)可能无以为继。
文章发布后,很多人反驳了这一观点,认为 Scaling Law 还没到撞墙的地步,毕竟很多训练大模型的团队依然能够看到模型能力的持续提升。而且,我们现在所说的 Scaling Law 更多是指训练阶段,而推理阶段的 Scaling Law 还未被充分挖掘,借助测试时间计算等方法,大模型的能力还能更上一层楼。
还有人指出,其实,在文本以外的领域,Scaling Law 的踪迹正在逐渐显现,比如时间序列预测以及图像、视频这类视觉领域。下面这张图来自投稿给 ICLR 2025 的一篇论文。论文发现,在把类似于 GPT 的自回归模型应用于图像生成时,Scaling Law 同样可以被观察到。具体表现为:随着模型大小的增加,训练损失会降低,模型生成性能会提高,捕捉全局信息的能力也会增强。论文标题:Elucidating the design space of language models for image generation论文链接:https://arxiv.org/pdf/2410.16257代码与模型:https://github.com/Pepper-lll/LMforImageGeneration论文作者之一、云天励飞的齐宪标博士在接受机器之心采访时表示:「我们不知道图像中的 Scaling Law 到底有多强,比如如果我们把图像生成模型也扩展到 Llama 7B 这个规模,是不是 GPT 那样的自回归方法也具有非常大的潜力?」抱着这个想法,他们进行了一些初步实验,发现只训练到一半的时候,自回归模型就已经在图像生成任务上表现出了很强的 Scaling Law。这让他们对自回归方法在视觉领域的应用充满信心。可见,至少在图像和视频生成等领域,Scaling Law 依然强势,离撞墙还远。在另一篇论文中,齐宪标等人还发现,其实在应用于图像领域时,传统的自回归方法也有改进空间。他们把改进后的方法称为「BiGR 」,该方法建立在何恺明等人 MAR(masked autoregressive)工作的基础之上,并在一些方面实现了改进,成为了首个将生成和判别任务统一在同一框架内的条件生成模型。这意味着,BiGR 不仅是一个好的图像生成器,同时还是一个强大的特征提取器,二者是相互促进的关系。论文标题:BiGR: Harnessing Binary Latent Codes for Image Generation and Improved Visual Representation Capabilities论文链接:https://arxiv.org/pdf/2410.14672代码与模型:https://github.com/haoosz/BiGR这些工作为研究界继续探索自回归模型在视觉领域的 Scaling Law 提供了一些启发。在这篇文章中,我们将对这些工作进行深入解读。顺带一提,这两项研究的代码和模型都已发布。自回归:Diffusion 之外的另一条道路在当前的视觉生成领域,Diffusion 模型是毫无疑问的霸主。这种方法生成的图像质量较高,视频也越来越好。但另一方面,以 Transformer 为代表的自回归模型在文本领域的成功就在眼前,这不禁让人去想象自回归模型在视觉领域的可能性。其实,早在 2018 年,谷歌的一个团队(其中大部分是 Transformer 论文作者)就已经探索过用自回归模型来生成图像(参见论文《Image Transformer》)。OpenAI 的初代 DALL・E 模型用的也是基于自回归的方法。但由于探索初期效果不佳,再加上 Diffusion 模型的强势崛起和开源,基于自回归的方法逐渐淡出了大部分研究者的视野。 初代 DALL・E 生成效果云天励飞的这些研究更像是一种「重新探索」,而且这次探索有很多可以借鉴的经验教训。正如齐宪标说的那样:「在我们重新探索这条路的时候,这些经验其实可以让我们思考过去走这条路的时候可能哪个地方没走好。」关于这种「重新探索」的动机,齐宪标分享了几个观点。第一个是关于 Scaling Law 的。正如前面所提到的,自回归方法的可扩展性已经在文本领域得到了验证,最大的文本模型已经做到了万亿参数。而在图像领域,这种 Scaling Law 才刚刚显现,未来还存在巨大的探索空间。第二个是关于多模态理解和生成的统一。在当前「scaling law 撞墙」的相关讨论中,多模态其实是一个被寄予厚望的方向。但是,这个领域目前面临一个严峻的挑战,即多模态的理解和生成是分开进行的,这就造成理解模型的理解能力强而生成能力弱,生成模型则相反。统一这两类任务,可以促进模型学到更通用的语义表征,还能让模型更好地探索数据中的潜在规律,从而增强模型在跨模态任务中的泛化性。而自回归方法的好处就在于它有一个 token 化的过程。无论什么模态,只要经过了 token 化,生成和理解就可以很容易被统一在一个框架里面。相比之下,基于 Diffusion 的方法就缺乏这种灵活性。除此之外,自回归方法用于视觉任务还有很多好处,比如模型指令遵循能力更强,之前在文本模型领域积累的经验、资源可以复用等等。这些原因驱使齐宪标和他的同事跳出 Diffusion 这条「主路」,走回了自回归这条已经相对冷门的路线。在图像上 Scaling 有效以及生成和判别的统一要理解 BiGR 和 ELM 的意义,我们得从离散化的图像和文本的 token 分布谈起。齐宪标表示:「我们得把一个图像块表示成一个单词。如果只是单纯的硬编码,我们是做不到的,因为它的空间太大了。所以,我们首先就是想办法来表示图像。这也就是所谓的 token 化。」图像的 token 化通常需要一个编码器 ENC、一个量化算法 QUANT 和一个解码器 DEC。目前,主流的图像 token 化方案有两种:VQGAN 和 BAE;它们的主要区别是离散化隐向量的方式 。经过 token 化处理之后,图像也就变成了类似文本的 token 序列。如此一来,理论上看,自回归(AR)模型和掩码式语言模型(MLM)等用于建模文本的方法也就可以用于处理图像了。即便如此,经过离散和 token 化处理的图像序列与文本序列之间依然存在固有的差异。下表给出了 ImageNet、OpenWebText 和 Shakespeare(后两个是文本数据集)的 token 分布的 KL 距离。基于此,可以得到两点观察:图像数据缺乏语言数据常有的那种内在结构和序列顺序。这种图像 token 分布的随机性表明图像生成并不依赖严格的序列模式。接近均匀的 token 分布表明生成任务对错误的容忍度更高。由于所有 token 的概率几乎相等,因此该模型可以容忍不太精确的 token 预测,同时还不会显著影响输出的质量。基于这些观察和进一步的实验,云天励飞得到了一个结论:在图像生成方面,自回归(AR)方法并不比掩码式语言模型(MLM)差,甚至可能还更好一点。虽然在语言领域,AR 优于 MLM 已经得到了许多研究成果的验证(实际上当今的大多数 LLM 都是 AR 范式),但在图像领域,这算是一个有些让人意外的结果,毕竟掩码机制似乎和图像任务有着天然的亲和力。在此基础上,云天励飞团队更进一步,初步发现了 AR 模型在图像生成任务上的 Scaling Law。越大越强,AR 或在图像生成上再次成功Scaling Law 的概念其实并不复杂,简单总结起来就是模型越大越好,数据越多越好,算力越强越好。研究 Scaling Law 之所以重要,是因为这能为后续的研究探索指引方向。在此之前,虽然已经有不少研究团队尝试过使用 Transformer 来生成图像,但还少有人严肃地探索过自回归 Transformer 在图像生成任务上的 Scaling Law。 自回归模型的 Scaling Law,其中 2B 模型由于时间限制并未完成 200 万次迭代,但其趋势依然很明显云天励飞的这项研究无疑是一支强心剂。具体来说,他们发现,随着模型规模增大,AR 模型在图像生成任务上的训练损失越低、生成性能越好、也能更好地捕获图像中的全局信息。他们基于这些观察构建了一个可生成图像的阐述式语言模型(ELM/elucidate language model),并在 ImageNet 256×256 基准上实现了 SOTA。 ELM-2B 生成的一些不同类别的图像至于注意力模式,不同大小的模型的差别倒是不大:L 大小的模型主要关注局部信息,难以捕获长程信息。相较之下,更大的 XL 和 XXL 模型的某些层表现出了更长程的注意力,这说明它们也能学习全局特征。为了进一步确认 AR 模型确实能理解图像任务,该团队对不同 AR 模型的注意力图(attention map)进行了可视化,结果发现其注意力机制确实会关注图像的某些局部区域,这说明自回归 Transformer 模型确实可以有效学习局部模式对于图像生成的重要性。这一结果又进一步凸显了自回归 Transformer 在不同领域的强大性能。 AR 模型的注意力图,可以明显看到其中对局部模式的关注掩码式 AR:判别与生成任务的创新性统一云天励飞在另一项研究中更深度地探索了 AR 模型在图像领域的可能性。这一次,AR 模型不仅被用来执行图像生成任务,还在图像判别任务上大展拳脚。 BiGR 框架的简化示意图为此,他们构建了一个名为 BiGR 的新框架。该框架包含 3 个主要组件:一个二元 token 化器,其作用是将像素图像转换成二元隐码构成的序列;一个仅解码器 Transformer,并配备了完整的双向注意力;一个二元转码器(binary transcoder),作用是将连续特征转换成伯努利分布的二元编码。不仅如此,BiGR 的训练完全是重建 token 的生成过程,无需依赖任何判别损失。那 BiGR 是如何将图像的生成与判别统一在一起的呢?其关键在于掩码机制与自回归模型的深度融合!具体来说,他们使用的骨干网络是基于 Transformer 的语言模型 Llama。由于图像和文本 token 的不同性质,他们没有使用语言模型常用的因果注意力,而是使用了双向注意力。模型的预测目标也不再是下一 token,而是被遮掩的 token。在输入空间,他们的做法也不再是查找有某个 token 索引的嵌入向量,而是使用一个简单的线性层来将二元编码投射到嵌入空间。在训练过程中,会使用一个可学习的掩码 token 遮蔽掉一部分图像 token。然后仅计算被遮蔽位置的损失,其中模型的预测目标是被遮掩的 token 的值。之后,再使用二元转码器,通过一个伯努利扩散过程,将模型的输出转换成二元编码。而在训练时,语言模型和扩散网络是联合优化的。训练完成后,模型本身就会具备强大的视觉表征能力:对于输入的图像,可以不带任何掩码地提供给模型,并附加一个无条件 token。然后,在连续值的特征上执行平均池化,推断给定图像的全局表征。他们得到了一个有趣的观察:最具判别性的表征还不是来自最后一层,而是 Transformer 模块内的中间层!因此,他们便将这些中间特征用作了最终的图像表征。对于图像生成任务,他们设计了一种采样策略,使模型可以根据完全掩蔽的序列迭代地预测 token。不同于训练阶段(每一步的掩码位置都是随机选取的),在采样阶段,会按照一个预定义的标准按顺序去除 token 的掩码。最终得到的模型可说是图像生成能力与判别能力俱佳,算是首个做到这一点的条件生成模型,并且同时还具备统一、高效、灵活、可扩展四大优势。从上表的结果中我们可以得出以下结论:通过比较 LlamaGen 和 S0,可知相比于使用 VQGAN,使用二元自动编码器可以带来更好的生成性能,但判别性能会下降一些。对于生成任务,AR 建模更适合分类损失,而掩码建模更适合二元损失。对于判别任务,不管哪种损失,掩码建模都大幅优于 AR 建模,而二元损失能进一步提升性能。与 AR 建模相比,掩码建模由于采样迭代次数较少,因此推理速度明显更快,而二元目标的扩散过程需要更多时间。这种生成与判别的统一能带来什么好处呢?齐宪标举了两个例子,如果我们想让模型生成一张「飞翔的熊猫」图,那么这种自回归 Transformer 方法可以直接完成从语言理解到图像生成的全过程,而无需调用 Stable Diffusion 等外部接口。另外,它也能帮助我们理解并进一步加工图像,比如可以在多张图片中找到我们想要的文本信息并将其抹除。 BiGR 的一些生成结果而通过实验不同大小的模型,我们同样看见了 Scaling Law 存在的踪迹。虽然云天励飞的论文中没有明说,但 Transformer 在这些不同视觉任务的成功或许意味着,在众说纷纭、似乎即将到来的 AGI 中,自回归 Transformer 或许至少有一席之地。当然,自回归范式在图像领域的成功也并非对 Diffusion 的否定,正如齐宪标说的那样:「基于自回归的方法的一个特别大的特点是它的指令服从能力非常强,而基于 Diffusion 的方法的生成质量可能更高,细节会更丰富一些,但是它对于指令的控制能力有的时候会偏弱一些。」另外,也应当指出,基于时间和成本的考量,这两项研究更侧重于对前沿技术和可能性的探索,想要开发基于 Transformer 的图像生成应用,还有待进一步的工程开发。而相关的 Scaling Law 也有待进一步的探索完善,比如,齐宪标指出,基于自回归方法和基于 Diffusion 方法的 Scaling Law 之间的差异就是一个非常有价值的研究课题。「我更想知道 transformer 为什么会 work」将自回归模型应用于视觉生成并不是一条拥挤的赛道,因为众所周知,想要跑通这条路线需要克服很多难点,比如生成速度慢、长程依赖难建模、高分辨率扩展性差、生成质量受限等。但出于对 Scaling Law 探索的渴望,云天励飞的研究团队依然选择走出了这一步。这可能也是非常有前瞻性的一步。这种前瞻性一方面与公司的人才密度(研发人员占公司总人数比例高达64.08%)密不可分,另一方面也在于公司给予人才的探索空间和算力支持(千亿参数模型训练能力)。齐宪标提到,这几点其实也是他当初选择云天励飞的关键原因。此外,齐宪标还谈到了自己颇为敬佩的云天励飞首席科学家、曾在微软工作 17 年的算法大牛肖嵘,称肖嵘是一个对公司整体战略把握非常清晰,同时又喜欢追问技术细节的人,比如他会让大家把学习曲线拉出来,看看 loss 为什么会飞掉,学习率设置对不对,数据有没有清洗干净。在这样的团队氛围中,云天励飞近年来在多个方向取得了一些研究成果,其中包括多项对大模型加速的工作这些工作探索了大模型端侧加速的方法,能够大大提升大模型端侧部署推理速度。考虑到云天励飞本身就有自有芯片,所以可为大模型的端侧落地提供「软硬一体的解决方案」。同时,云天励飞科研团队还有多项研究成果投稿到 ICLR 2025 会议。其中有两项是关于Transformer 基础理论的研究。一项探索了大模型训练崩溃的根本原因,他们归结于的谱能量集中。另外一项则是设计了高效且稳定的 Transformer 模块。「谷歌在训练 PaLM 模型的时候,训练的 loss 飞掉了 20 多次。Meta 训练 Llama 3 的时候因为各种问题崩溃了四百多次。这其中很多问题可能都跟我们对 Transformer 的底层理解有关。也就是说,我们对于 Transformer 的应用已经做了很多,但对 Transformer 理论的理解相对来说还不够透彻。我更想知道 Transformer 为什么会 work,为什么会出现问题。」齐宪标在谈及这个方向的研究动机时说道。结语这几天,关于 Scaling Law 是否撞墙的讨论还在继续,齐宪标显然并不认可 Scaling Law 已经撞墙的说法 —— 不管是图像还是文本,Scaling 都还能带来明显的提升。不过,他也指出,对于 Scaling Law 的探索注定是一项长期工作,需要从多个方向找突破口,云天励飞也将持续探索。据了解,今年云天励飞一直在强调「边缘 AI」战略。为此,他们选择了从软硬件两个方向同时前进,即 AI 芯片和大模型。在此基础上,他们进入了「算法芯片化」这一赛道。云天励飞表示,他们已经打造出了一些面向消费者、企业和城市的大模型相关产品和解决方案。据了解,今年底云天励飞还会推出两款基于大模型打造的智能硬件产品。2024 年被许多人称为「人工智能应用的真正元年」。AI 开始走出开发者和爱好者的圈子,向普罗大众更广泛地渗透。通过在底层技术创新和应用开发两方面持续发力,云天励飞能否在已然卷成红海的 AI 行业博取一块蛋糕?还有待进一步观察。不过,考虑云天励飞在 AI 的软件和硬件两方面都已经有了相当厚实的技术沉淀,做到这一点应该并不难。 相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










