

 新火种
2024-11-22
新火种
2024-11-22 


诺奖得主哈萨比斯新作登Nature,AlphaQubit解码出更可靠量子计算机
谷歌「Alpha」家族又壮大了,这次瞄准了量子计算领域。今天凌晨,新晋诺贝尔化学奖得主、DeepMind 创始人哈萨比斯参与撰写的新论文登上了 Nature,主题是如何更准确地识别并纠正量子计算机内部的错误。我们知道,量子计算机有潜力彻底改变药物发现、材料设计和基础物理学。不过前提是:我们得让它们可靠地工作。虽然对于传统计算机花费数十亿年才能解决的某些问题,量子计算机在几小时内就可以搞定。然而,量子计算机比传统计算机更容易受到噪声的影响。如果想要量子计算机更可靠,尤其是在大规模情况下,则需要更准确地识别和纠正内部的错误。
因此,谷歌 DeepMind 联合谷歌量子 AI 团队发表了一篇论文,推出了 AI 解码器 AlphaQubit,它能够以 SOTA 准确性识别并纠正量子计算的错误。据介绍,这项工作汇集了谷歌 DeepMind 的机器学习知识和谷歌量子 AI 的纠错专业知识,从而加速构建可靠量子计算机的进程。两支团队表示,准确识别量子计算机错误是促使它们能够大规模执行长时间计算的关键一步,将为科学突破和更多新领域的发现打开大门。
Nature 论文的标题为《Learning High-accuracy Error Decoding for Quantum Processors》,即《学习量子处理器的高准确性错误解码》。
Nature 地址:
谷歌 CEO 桑达尔・皮查伊表示,「AlphaQubit 使用了 Transformers 解码量子计算机,从而达到量子纠错准确性新 SOTA。这是 AI + 量子计算的激动人心的交集。」
我们接下来看 AlphaQubit 的技术细节和实验结果。量子计算纠错的原理量子计算机利用最小尺度上物质的独特属性,例如叠加和纠缠,以比传统计算机少得多的步骤解决某些类型的复杂问题。该技术依赖于量子比特,它们可以利用量子干涉筛选大量可能性以找到答案。不过,量子比特的自然量子态很脆弱,可能受到各种因素的干扰,包括硬件中的微观缺陷、热量、振动、电磁干扰甚至宇宙射线,可以说无处不在。量子纠错通过使用冗余提供了一种解决方案:将多个量子比特分组为单个逻辑量子比特,并定期进行一致性检查。AlphaQubit 解码器通过利用这些一致性检查来识别逻辑量子比特中的错误,从而保留量子信息,并进行纠错。如下动图展示了边长为 3(码距离)的量子比特网格中 9 个物理量子比特(小灰色圆圈)如何形成逻辑量子比特。其中,在每个步骤中,另外 8 个量子比特在每个时间步骤执行一致性检查(正方形和半圆形区域,失败时为蓝色和品红色,否则为灰色),以通知神经网络解码器(AlphaQubit)。在实验结束时,AlphaQubit 确定发生了哪些错误。
谷歌构建了一个神经网络解码器AlphaQubit 是一个基于神经网络的解码器,基于 Transformers 构建,而该架构也是当今许多大型语言模型的基础。下图为 AlphaQubit 的纠错和训练流程。a 为表面码的一轮纠错。b 为解码训练阶段。预训练样本要么来自数据无关的 SI1000 噪声模型,要么来自使用 p_ij 或 XEB 方法从实验数据得出的误差模型。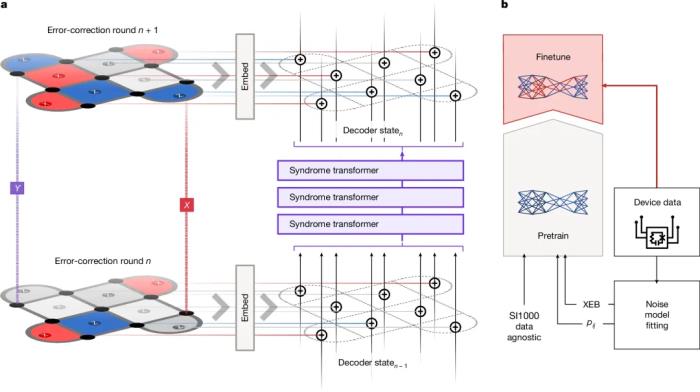
AlphaQubit 使用一致性检查(consistency checks)作为输入,旨在预测逻辑量子比特在实验结束时的状态是否与初始准备状态发生了翻转。通过一致性检查,可以识别并纠正计算过程中出现的错误,确保逻辑量子比特状态保持正确。最终,AlphaQubit 可以报告其预测的置信度,从而有助于提高整体量子处理器的性能。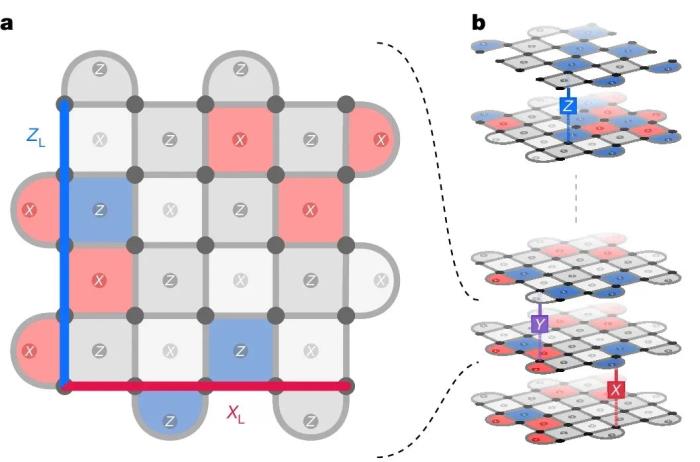
实验及结果实验测试了 AlphaQubit 对量子处理器 Sycamore 中的逻辑量子比特的保护效果。谷歌使用量子模拟器在各种设置中生成了数亿个示例。然后,通过为 AlphaQubit 提供来自特定 Sycamore 处理器的数千个实验样本,针对特定解码任务对其进行微调。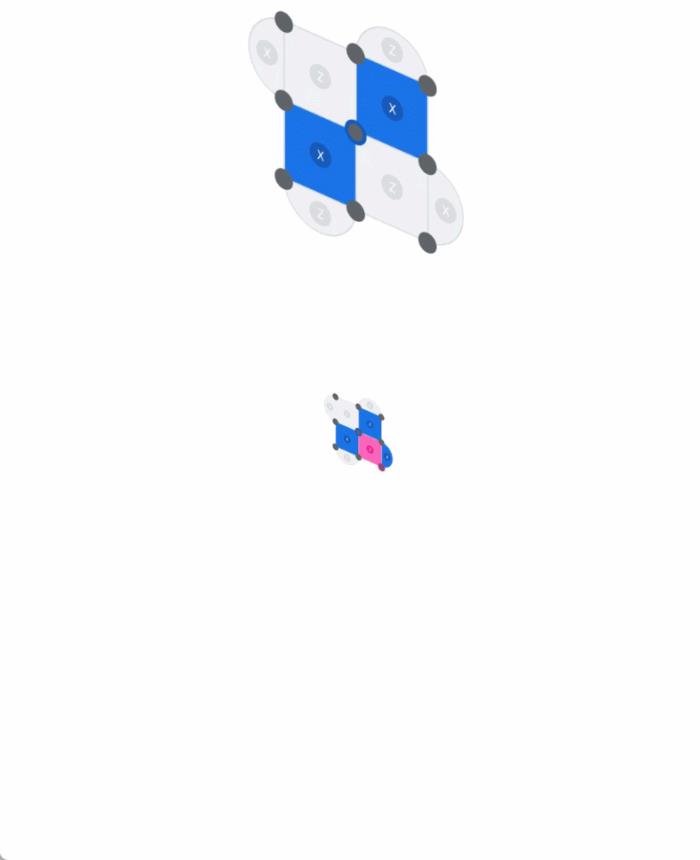 在对 Sycamore 量子处理器的新数据进行测试时,AlphaQubit 在准确率方面设立了新的标准。在规模最大的 Sycamore 实验中,AlphaQubit 的错误率比张量网络方法低 6%。此外,AlphaQubit 的错误率比相关匹配方法低 30%。在 Sycamore 量子处理器的实验中,解码准确性因实验规模而异。对于小规模实验(距离 3,对应 17 个物理量子比特)和大规模实验(距离 5,对应 49 个物理量子比特),AlphaQubit 的解码准确性均优于其他方法。具体而言,AlphaQubit 的表现超过了张量网络(TN)方法,后者在大规模实验中难以扩展。同时,AlphaQubit 也优于相关匹配方法,尽管该方法在准确性和扩展性方面表现良好,但在解码准确性上仍不及 AlphaQubit。
在对 Sycamore 量子处理器的新数据进行测试时,AlphaQubit 在准确率方面设立了新的标准。在规模最大的 Sycamore 实验中,AlphaQubit 的错误率比张量网络方法低 6%。此外,AlphaQubit 的错误率比相关匹配方法低 30%。在 Sycamore 量子处理器的实验中,解码准确性因实验规模而异。对于小规模实验(距离 3,对应 17 个物理量子比特)和大规模实验(距离 5,对应 49 个物理量子比特),AlphaQubit 的解码准确性均优于其他方法。具体而言,AlphaQubit 的表现超过了张量网络(TN)方法,后者在大规模实验中难以扩展。同时,AlphaQubit 也优于相关匹配方法,尽管该方法在准确性和扩展性方面表现良好,但在解码准确性上仍不及 AlphaQubit。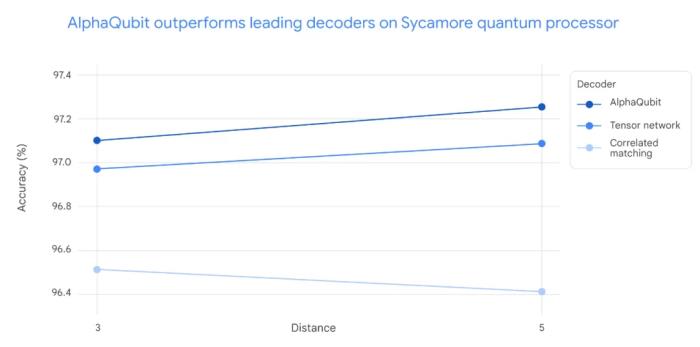
在一系列实验中,解码器 AlphaQubit 犯的错误最少。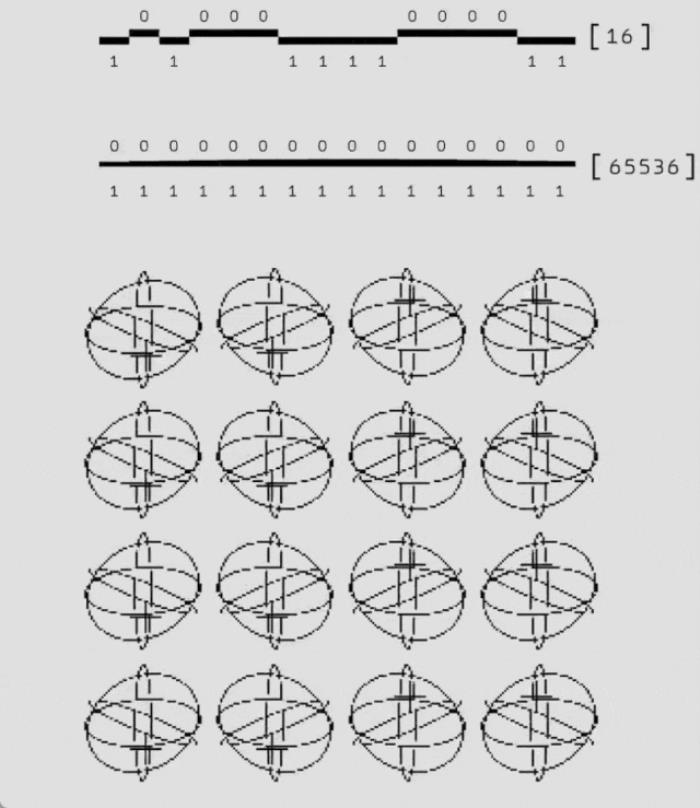
良好的泛化能力为了评估 AlphaQubit 在更大规模且错误率更低的量子计算机上的适应性,研究人员使用模拟的量子系统数据对其进行了训练,规模达到 241 个量子比特,超出了 Sycamore 平台的现有能力。
结果显示,AlphaQubit 的性能优于现有的主要算法解码器,表明其在未来中型量子设备上也将具备良好的适用性。在不同规模的实验中,即从距离 3(17 个量子比特)到距离 11(241 个量子比特)的实验中,AlphaQubit 的解码准确性始终优于相关匹配方法。需要注意的是,张量网络解码器由于在大规模实验中运行速度过慢,未在此图中显示。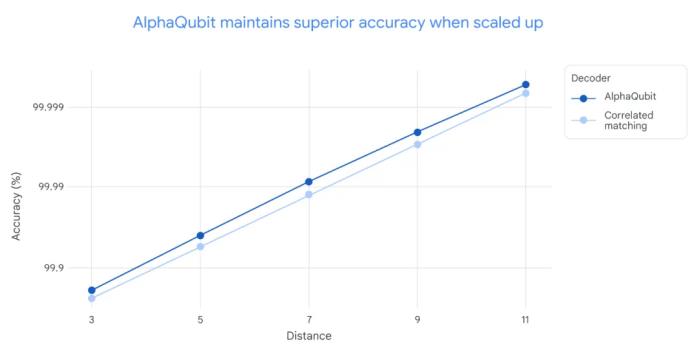
最后,该系统还展示了一些高级功能,例如能够接收和报告输入和输出的置信度。这些信息丰富的界面有助于进一步提高量子处理器的性能。当谷歌研究员在包含多达 25 轮纠错的样本上训练 AlphaQubit 时,它在多达 100,000 轮的模拟实验中保持了良好的性能,表明它能够泛化到训练数据之外的场景。迈向更实用的量子计算AlphaQubit 在利用机器学习进行量子误差纠错方面取得了重要的里程碑。但谷歌表示他们仍然面临速度和可扩展性方面的重大挑战。例如,在一个快速的超导量子处理器中,每秒需要进行上百万次一致性检查。虽然 AlphaQubit 在准确识别错误方面表现出色,但目前还无法实时纠正超导处理器中的错误。谷歌还需要找到更高效的数据训练方法,用于支持基于 AI 的解码器。
目前,谷歌正在结合机器学习和量子误差纠错的前沿技术,努力克服这些挑战,为实现可靠的量子计算机铺平道路,这些技术将有能力解决世界上一些最复杂的问题。参考链接:
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










