新火种
2024-11-22
新火种
2024-11-22 


NeurIPS2024|水印与高效推理如何两全其美?最新理论:这做不到
本文第一作者为毕业于马里兰大学计算机系的博士胡正冕,其导师为 Heng Huang。他的主要研究方向是采样与机器学习理论,曾在 ICML、NeurIPS、ICLR、EMNLP 等顶会上发表多篇论文。邮箱: huzhengmian@gmail.com
近日,DeepMind 团队将水印技术和投机采样(speculative sampling)结合,在为大语言模型加入水印的同时,提升其推理效率,降低推理成本,因此适合用于大规模生产环境。这项研究发表在了 Nature 杂志上,给出了两种具体的结合方法,分别在水印检测效果和生成速度上达到了现有最优水平,但无法同时兼顾两者。
无独有偶,另一组来自马里兰大学的研究人员针对同一个问题进行了理论角度的深入分析。他们发现了一个「不可行」定理,证明了不存在一个算法可以同时达到最优的推理效率和最高的水印强度。因此,任何水印系统都必须在这两个目标之间进行权衡。这项名为「Inevitable Trade-off between Watermark Strength and Speculative Sampling Efficiency for Language Models」的研究已被 NeurIPS 2024 会议接收。
论文地址:
代码仓库: h
无偏水印与投机采样方法
无偏水印方法 [1] 是一种将水印嵌入到生成文本的技术,它在理论上保证不影响生成文本的质量和多样性,并让水印无法被人察觉。这种水印方法可用于版权保护和来源追踪。其核心思想是在生成过程中对候选 token 的概率进行重新加权,并要求调整后的概率分布在对水印的随机私钥进行平均后,在数学期望上与原始分布相同,从而避免引入偏差。
投机采样方法 [2,3] 是一种加速大语言模型推理的技术。此方法利用较小的草稿模型快速生成草稿序列,再通过目标模型对这些草稿进行验证和修正。草稿模型规模较小,生成速度更快但质量较低;目标模型并行进行验证,接受符合条件的部分。这种方法可以在保持生成质量的同时,显著提升推理效率,降低计算成本,已成为大规模应用中不可或缺的工具。
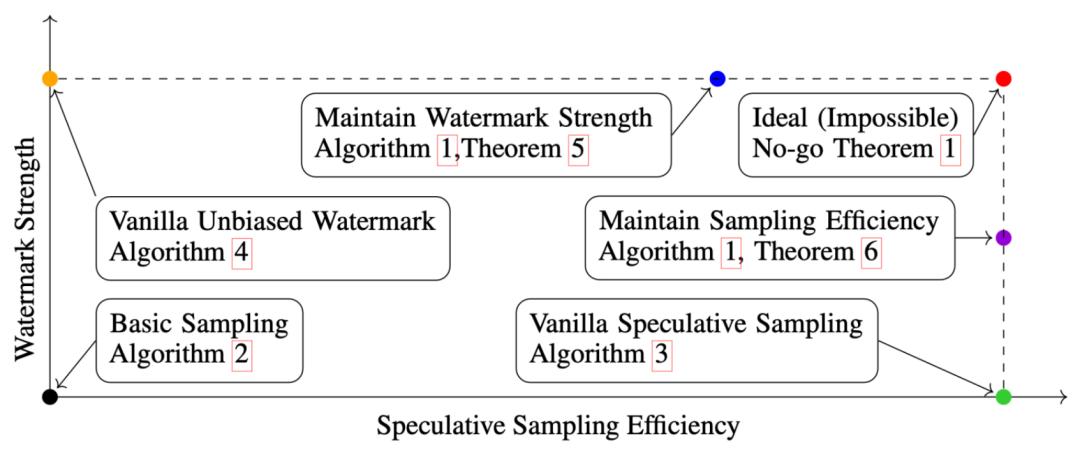
「不可行」定理
研究者提出了一个两次重加权框架,分别对草稿模型和目标模型的输出分布进行重加权。这个框架具有很高的自由度,两次重加权函数可以不同,验证算法也可以任意选择,只要满足最终算法保持输出概率分布,从而维持输出质量即可。
在此框架下,研究者严格描述并证明了一个「不可行」定理:当词汇表大小大于 2 时,任何试图同时保持水印强度和加速效果的方法都必然使用两个平凡的重加权函数。

这个定理揭示了水印强度和投机采样效率之间存在一个不可避免的权衡,必须在两者之间做出选择。任何潜在的方法都无法同时达到在不考虑加速情况下最好的水印技术的检测效率,和在不考虑水印情况下最好的投机技术的加速效果。此结果也为未来的研究指明了方向:在设计新算法时研究者需要考虑这个理论限制,根据应用需求在两个目标之间进行平衡。
两种结合方法
即便「不可行」定理揭示了水印强度和采样效率之间存在不可避免的权衡,此研究给出了两种具体的结合水印和投机采样的方法,使得其分别满足以下两点性质:
1. 保持水印强度的方法优先确保水印的可检测性,即使这可能会牺牲一定的采样效率。这种方法首先对目标模型和草稿模型的输出概率分布进行重加权并从中采样,然后基于两个重加权分布进行投机采样。
2. 保持采样效率的方法优先保证生成速度,即使水印的强度可能有所降低。这种方法仍然对目标模型和草稿模型的输出概率分布进行重加权并从中采样,但接下来基于两个未经过重加权的分布进行投机采样。
这两种方法体现了不同的取舍,使用者可以根据具体应用场景和需求进行选择。
实验结果
研究人员在多种文本生成任务以及多种语言模型上进行了实验。他们引入了两个指标:平均每步接受的 token 数(AATPS)衡量投机采样效率,每个 token 的平均负对数 P 值(ANLPPT)衡量水印强度。
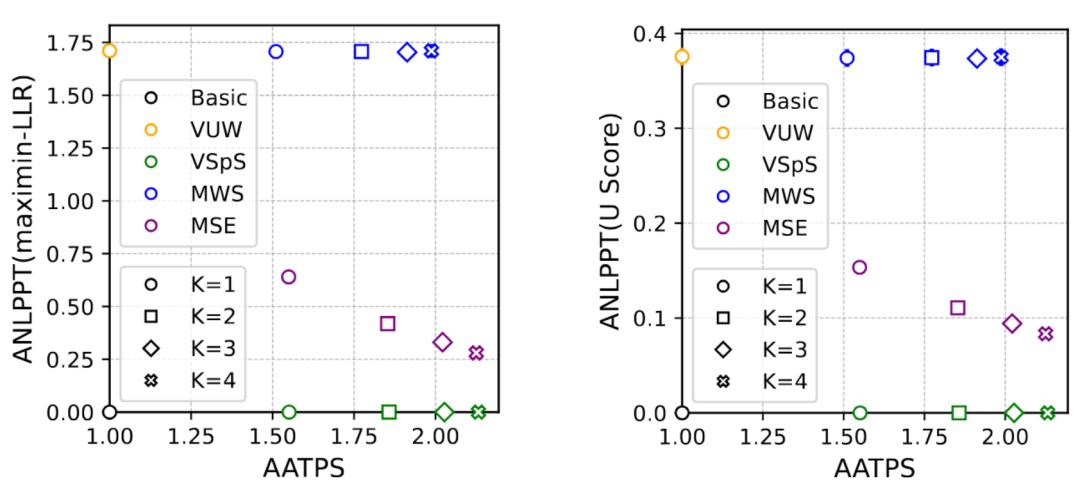
实验结果验证了理论分析的正确性,证实了水印强度和采样效率之间确实存在权衡。保持水印强度的方法在水印强度上与传统无偏水印方法相当,但采样效率相比原始投机采样方法有所下降;保持采样效率的方法在采样效率上与原始投机采样方法相当,但水印强度有明显降低。这表明根据实际需求,可以选择优先保证水印强度或采样效率的策略。
总结
此研究从理论角度证明了水印可检测性和投机采样效率之间存在根本冲突,这种冲突并不仅限于现在已有的方法,而是一个普遍规律。鉴于投机采样已经成为降低推理成本不可或缺的工具,高可检测水印系统带来的推理成本增加在未来将持续存在。
将水印技术与投机采样结合这个行为虽然可以让水印更接近实用,但同时也可能带来一些伦理问题,如未经披露的跟踪行为。在实际应用中,人们应当谨慎、合乎伦理地应用无偏水印方法,并向用户明确说明其存在,工作原理和意义。
[1] Unbiased Watermark for Large Language Models
[2] Fast Inference from Transformers via Speculative Decoding
[3] Accelerating Large Language Model Decoding with Speculative Sampling
© THE END
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。