

 新火种
2023-09-19
新火种
2023-09-19 


口音成语音识别发展最大公敌,新解决方案正在开发中

图片来源@视觉中国
语音对于人机交互的重要性毋庸置疑,无论是国内外企业,都在语音识别的速度、准确度以及多语种方面持续创新,但是当机器面对那些有口音的人来说,似乎就没有那么灵敏了:不仅注意力会不集中,反应迟钝,甚至还会成为一个独立的个体,不予任何回应。如何解决口音识别问题,已成为智能语音下一阶段的竞争焦点,但这不仅仅是单纯的增加语料库就能提升的,好在已经有少数公司,开始通过构建新的语音模型,来解决口音问题。
自IBM的Shoebox与Worlds of Wonders的Julie Doll问世以来,语音识别技术已经取得了长足进步。甚至有报道称,到2018年底,谷歌Google Assistant将支持超过30种语言。除此以外,高通已经开发出了一款能够识别单词和短语的语音识别设备,准确率高达95%。而微软也不甘示弱,其呼叫中心解决方案(智能语音客服)比人工展开的呼叫服务更准确,更高效。
但需要注意的是,尽管在机器学习的加持下,语音识别技术取得了巨大的进步,但现在的语音识别系统还是不完美的。比如,不同地区的口音,让这项技术拥有了很强的“地域歧视性”。通常情况下,口音对人类来说不是什么大问题,有时还会让人感觉到一种异国风情的魅力,但是对机器而言,这是一条难以跨越的鸿沟,可能是其发展过程中面临的最大挑战。
研究显示口音是语音识别技术的挑战之一
最近,华盛顿邮报与Globalme和Pulse Labs两家语言研究公司合作,对搭载了语音识别技术的智能音箱设备的口音问题进行了研究,研究范围来自美国近20个城市、超过100名参与者发出的数千条语音命令,结果显示,这些系统在理解来自不同地区的人的语言时存在显著差异。
举个例子,谷歌智能音箱Google Home识别西岸口音的准确率比识别南方口音高3%;而亚马逊语音助手Alexa识别中西部的口音的准确率要比东岸口音低2%。但面临最大问题的是持非本土口音的人:在一项研究中,通过对比Alexa识别的内容与测试组的实际话语,结果显示不准确率可达30%。此外,面对以西班牙语和汉语作为第一语言的人所说的英文,不管是Google Home还是Amazon Echo,其识别率都是最低的,要知道,拉丁裔和华裔是美国的两大移民族群。
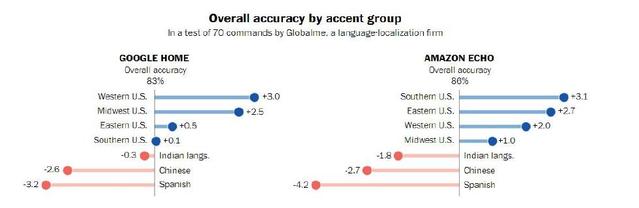
虽然这项研究是非正式的,也存在一定的限制,但其结果还是表明口音仍是语音识别技术面临的主要挑战之一。对此,亚马逊在一份声明中称,“随着越来越多的拥有不同口音的人与Alexa进行交流,Alexa的理解能力也会得到改善。”同时,谷歌也表示,“在扩大数据集的同时,我们也将继续提高Google Home的语音识别能力。”
事实上,不只是Amazon Echo和Google Home,采用率更低一些的微软Cortana和苹果Siri也是如此,它们都需要及时提高自家的语音识别技术,以便让用户感到满意的同时,又能在全球范围内扩大自己的影响力。
即使增加语料库,也无法解决口音识别问题
随着人工智能的发展,语音已经成为了人与计算机交互的核心方式之一,所以即使理解上有极其微小的偏差,也可能意味着一个巨大的障碍。也就是说,这种语言差异可能会给那些现代科技的基础系统带来潜在的隐患,毕竟除了厨房和起居室,智能音箱在用户的工作场所、学校、银行、医院以及酒店等地方也承担着越来越重要的责任,除了控制设备还要传递信息,并完成一些预订和购物工作等。
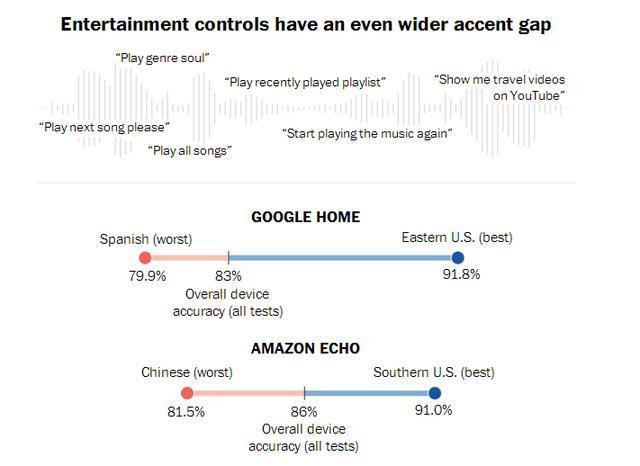
为了改善语音助手的口音识别情况,亚马逊与谷歌等正在投入资源,用新的语言和口音训练测试系统,包括创建游戏以鼓励大家使用不同地区的方言进行交谈。而像IBM和微软这样的公司,都会通过Switchboard语料库来降低语音助手的出错率。但是事实证明,语料库也无法彻底解决语音助手的口音识别问题。
对此,埃森哲全球责任AI监理Rumman Chowdhury表示,“数据是混乱的,因为数据反映了人性。这就是算法最擅长的:寻找人类的行为模式。”
算法的这一情况被称为“算法偏差”,用于反应机器学习模型对数据或设计产生的偏见程度。比如,现在有很多报告都显示了面部识别技术的敏感性——尤其是亚马逊AWS的图像识别技术Rekognition——有很大的偏见倾向。此外,算法偏差还会出现在其他方面,像预测被告是否会在未来犯罪以及Google News等应用背后的内容推荐算法。
构建语音识别模型,提升方言识别率
虽然已经有不少巨头针对算法偏见提出了解决方案,比如微软、IBM、Facebook、高通和埃森哲等已经开发出了自动化工具,用于检测AI算法中的偏见,但很少有企业针对语音识别技术面临的口音问题提出具体的解决方案。对此,Speechmatics和Nuance成为了少数者之一。
Speechmetrics是一家专门从事企业语音识别软件的剑桥科技公司,12年前就开始展开一项雄心勃勃的计划,旨在开发比市场上任何产品都更准确,更全面的语言包。据了解,研究之初,该公司的主要工作是统计语言建模和循环神经网络,并以此开发出了一种可以处理内存输出序列的机器学习模型。
2014年,Speechmetrics通过一个10亿字节的语料库加速了其统计语言建模的进展,到2017年与卡塔尔计算研究所(QCRI)合作开发阿拉伯语言的文字转换服务,可以说,这是该公司取得的一个里程碑式的进展。

而到了今年7月,该公司再次有所突破——成功研发了一款语音识别系统Global English,包括了全球40多个国家的数千小时的语音数据和数百亿单词,可支持“所有主要”英语口音的语音文本转换。另外,这个系统是建立在Speechmatic的Automatic Linguist的基础上,这是一个AI框架,通过利用已知语言中识别的模式来学习新语言的语言基础。
而在特定的口音测试中,Global English的表现要优于谷歌的Cloud Speech API以及IBM Cloud中的英语语言包中。Speechmatic声称,在高端领域,该系统的准确率比其他产品还要高23%到55%。
但Speechmatics并不是唯一一家想要解决口音识别问题的公司。
总部位于马萨诸塞州的Nuance表示,该公司正在采用多种方法确保其语音识别模型能够以同样的准确率来识别大约80种语言。
举个例子,在其英语语音识别模型中,该公司收集了20个特定方言区域的语音和文本数据,包括每种方言的特有单词及其发音。因此,Nuance的语音识别系统可以识别出单词“Heathrow”的52种不同变体。
最近Nuance的语音识别系统也有了很大的提升。较新版本的Dragon是该公司发布的定制语音到文本软件套件,所使用的机器学习模型,可根据用户的口音在几种不同的方言模型之间自动切换。另外,与没有自动切换功能的旧版本相比,新版对带有西班牙口音的英语识别的准确率要高22.5%,对于美国南部的方言来说,准确率要高16.5%,对于东南亚的英语口音的准确率要高17.4%。
事实上,研究人员很早之前就发现了语音识别面临的口音问题。对此,语言学家和AI工程师纷纷表示,非本地语言通常是很难进行训练的,因为语言之间的模式要一多种不同的方式进行切换。同时,语境也很重要,即使是细微差别也会改变对话双方的反应。但可以肯定的是,缺乏多样性的语音数据最终可能会无意中导致“地域歧视”的发生。也就是说,语料库中语音样本的数量和多样性越高,得到的模型就越准确——至少在理论上是这样。
当然,这也不仅仅是美国企业需要解决的问题。百度硅谷办事处的高级研究员Gregory Diamos曾说,该公司面临着自己的挑战,即开发一款可以理解许多中国地方方言的人工智能。此外,很多工程师也表示,口音对于致力于开发那种不仅可以回答问题,还能随意进行自然对话的软件公司来说,是最严峻的挑战之一。
今年5月,谷歌推出了一款名为Duplex的系统,可以以逼真的语音语调打电话完成餐厅预订,整个过程是“语音不流畅”的,因为中间会夹杂“嗯”、“呃”等语气词。在一定程度上,这样的技术让人有这样的感觉:这个机器在倾听我的话语。有用户表示,自己好像被困在了一个灰色地带,虽然可以被理解,但又好像与机器人格格不入。
根据市场研究公司Canalys的数据,到2019年会有近1亿台智能音箱在全球销售,而到2022年,约55%的美国家庭会拥有一个智能语音系统。在小智君看来,通过大量声音数据及其语音模式的学习,理解不同单词、短语和声音之间形成的清晰联系,人工智能便可以更加了解不同的口音,提高识别能力。
但也不要期待“银弹”的出现,毕竟按照现在技术的发展,我们不能期待很快就能研发出一个准确率极高却又可以适用于所有用户语言的语音识别系统。如今,能满足正在使用的用户的口音需求,便足矣。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章










