

 新火种
2024-10-22
新火种
2024-10-22 


颜水成袁粒提出新一代MoE架构:专家吞吐速度最高提升2.1倍!
比传统MoE推理速度更快、性能更高的新一代架构,来了!
这个通用架构叫做MoE++,由颜水成领衔的昆仑万维2050研究院与北大袁粒团队联合提出。

总体来看,MoE++的创新之处在于引入了“零计算量专家”,得益于这个设计,使得新架构有了三大优势:
降低计算成本:MoE++允许每个Token使用可变数量的FFN专家,甚至可以完全跳过当前的MoE层。提升性能:通过减少简单Token所需的FFN专家数量,MoE++使更多专家能够专注于复杂的Token,释放出比传统MoE更大的性能潜力。零计算量专家的参数极小:可以在每个GPU上同时部署所有的零计算量专家,避免了分布式FFN专家部署带来的通信开销和专家负载不均的问题。除此之外,MoE++还让每个Token在选择专家时参考前一层的路由路径。
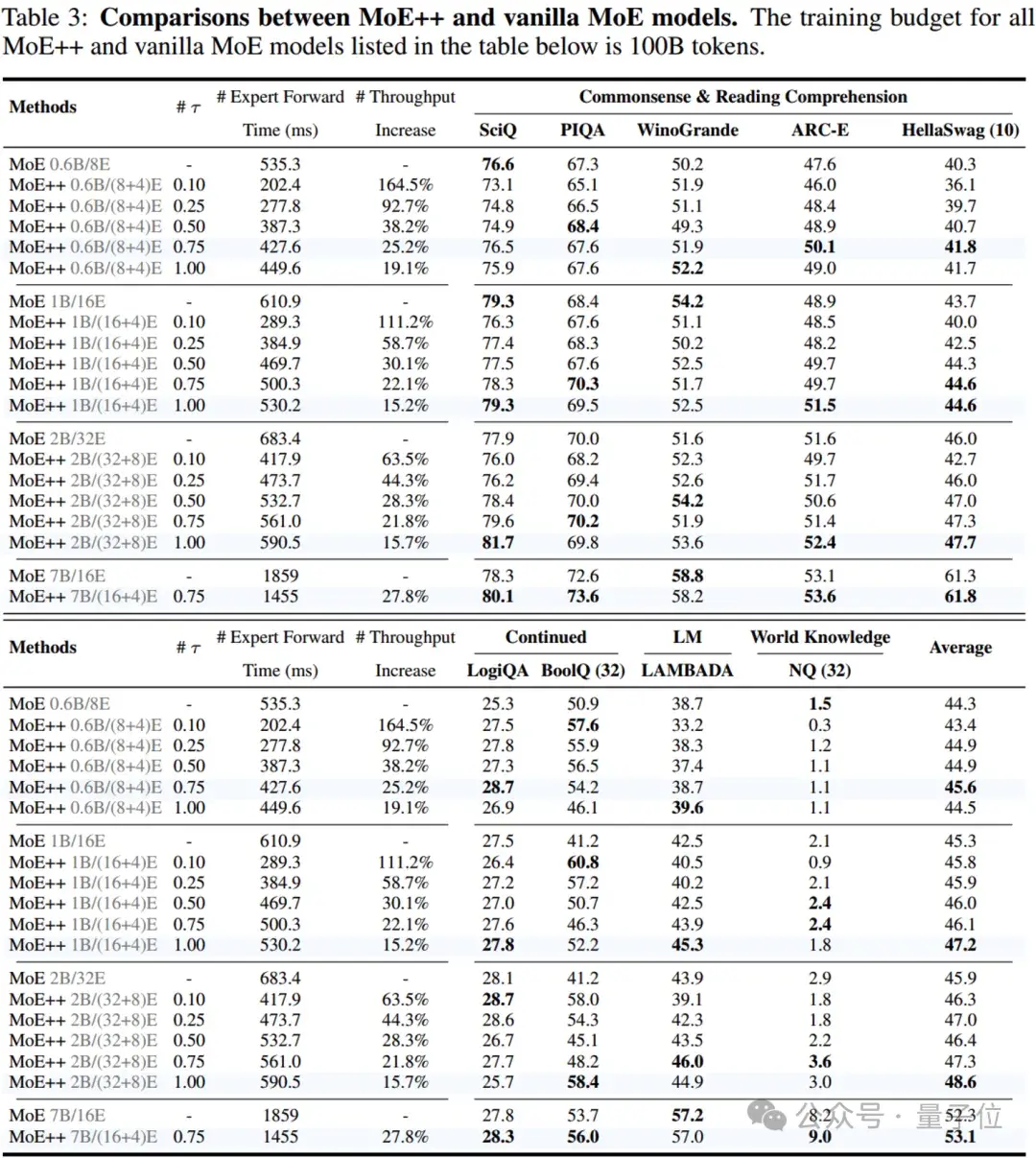
实验结果表明,在0.6B到7B参数规模的LLMs上,MoE++在相同模型大小的情况下,相比传统MoE,性能更优,同时实现了1.1到2.1倍的专家吞吐速度。
并且这个模型权重也已开源!
那么MoE++具体是如何做到的,我们继续往下看。
MoE++是如何做到的?现有的大多数混合专家(MoE)方法通常为所有Token激活固定数量的FFN专家。
在许多研究中,每个Token会选择Top-2 FFN专家,并将它们的输出加权合成为下一层的输入。然而,并非所有Token的预测难度都是相同的。
例如,像逗号等简单符号可能只需要一个FFN专家来处理。
甚至在某些特殊情况下,某些Token如果与当前MoE层的专家不匹配,绕过该层而不选择Top-2 FFN专家反而可能更为高效。
基于这一见解,研究团队认为,现有MoE使用的固定混合机制可能导致训练和推理效率下降,同时限制模型性能。
为了在提升速度的同时增强性能,研究团队提出了一种通用的异构MoE框架,称为MoE++。
具体来说,团队引入了三种零计算量专家:
Zero专家,输出空向量Copy专家,将输入直接作为输出Constant专家,用可训练的向量替代输入作为输出。如图1所示,与传统MoE方法不同,MoE++允许每个Token使用可变数量的FFN专家,接受恒定向量的替换,甚至完全跳过当前的MoE++层。
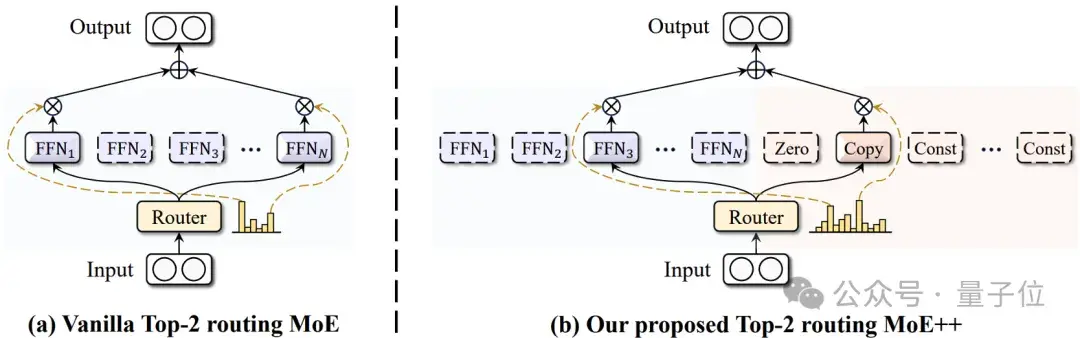
△图1:MoE++和普通MoE的对比
这种异构结构通过扩大网络的组合空间,提升了模型的拟合能力,并显著降低了计算成本。
此外,研究团队还将前一层的路由分数整合到当前层的专家选择中,使Token在选择专家时能够参考其先前的路由路径,从而实现更稳定的专家分配。
研究团队认为,新设计的MoE架构应满足以下标准:
设计应尽量简化,以高效处理简单的Token为了确保公平比较,新增参数应保持在可忽略的范围在这些原则的指导下,研究团队引入了零计算量专家,每个专家仅执行最基本的操作。
如图2(a)所示,团队设计了三种类型的零计算量专家:Zero专家、Copy专家和Constant专家,分别对应丢弃、跳过和替换操作。
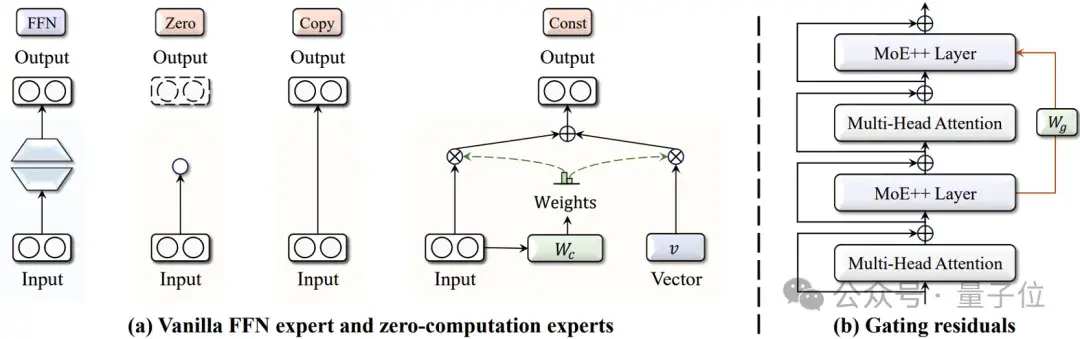
△图2:MoE++的核心组成部分
Zero专家
最简单的零计算量专家是丢弃当前输入的Zero专家。
本质上,Zero专家的存在可以将Top-2 MoE++层降级为Top-1 MoE++层。
具体来说,当Zero专家被激活时,Top-2 MoE++层的输出将等同于另一个专家的单独输出。
这样,Zero专家的引入提升了模型在处理简单Token和复杂Token时的灵活性。
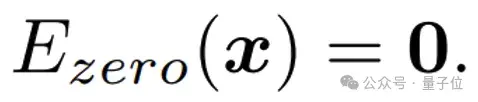
Copy专家
Copy专家直接将输入作为输出,直观上相当于跳过当前MoE++层。
具体而言,当输入Token与现有专家的匹配较差时,选择绕过MoE++层可能更为有利。
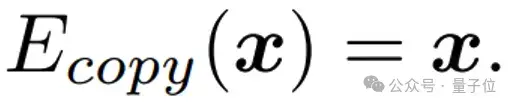
Constant专家
Constant专家通过可训练向量替换输入Token。
然而,完全替换会导致输入Token信息的丢失。
为此,研究团队引入了可训练的权重矩阵,用于动态预测替换的比例。由于Constant专家的计算开销极小,因此仍被归类为零计算量专家。

路由分数残差
由于MoE++包含异构专家,因此与普通MoE相比,路由器的设计变得更加关键。
为此,如图2(b)所示,研究团队提出了一种路径感知路由器,它在选择合适的专家时考虑了前一层所采用的路径。
具体来说,MoE++将前一层的路由分数通过一个可学习的转换矩阵合并到当前层的专家选择中。
这些路由分数残差使每个Token在选择专家时可以考虑其先前的路由路径。
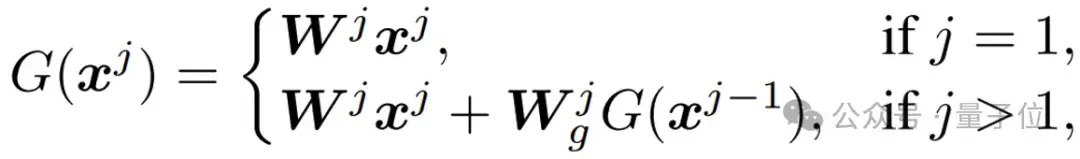 为什么MoE++比MoE更好(Why)?
为什么MoE++比MoE更好(Why)?对于这个问题,主要可以总结三点原因。
首先就是灵活的计算量分配。
MoE++通过为简单Token分配较少的FFN专家,优化了计算资源的分配,从而使更多FFN专家能够专注于处理更具挑战性的Token。
正如图3所示,研究团队发现,在MoE++中,动词激活的FFN专家数量最多,其次是名词,而拆分后的词片激活的FFN数量最少。
这表明,MoE++能够让语义较少的Token使用更少的FFN专家,从而释放更多专家来处理语义更丰富的Token。因此,MoE++不仅减少了计算开销,还提升了整体性能。
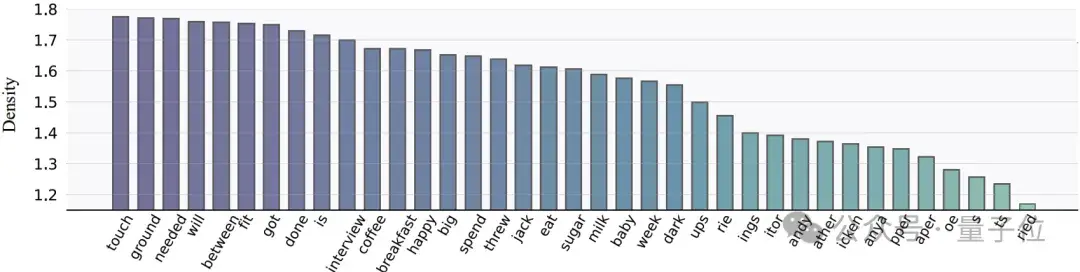
△图3:在MoE++中不同Token所需要的平均FFN专家数量
其次是稳定的路由。
MoE++将前一层的路由分数合并到当前层的专家选择中。
这些路由分数残差使每个Token在选择专家时考虑其先前的路由路径。
如图4所示,路由分数残差有效地建立了不同MoE++层之间的联系,减小了路由分数的方差。
同时,路由分数残差不改变路由分数的均值和取值范围。因此,路由分数残差有助于在MoE++中实现异构专家架构的稳定路由。
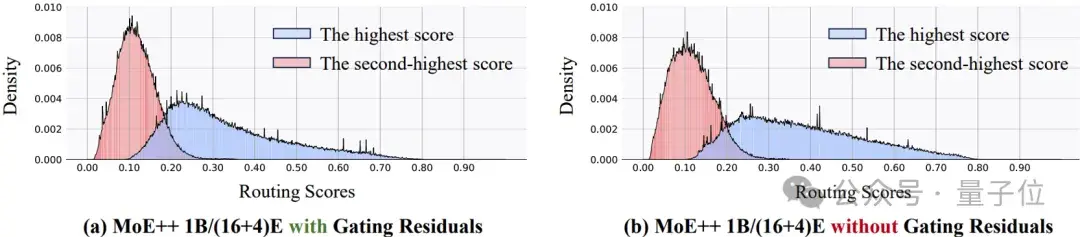
△图4:路由分数残差对路由分数分布的影响
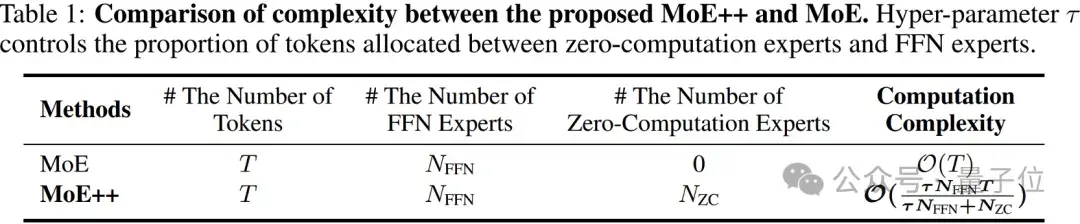
最后是更低的计算复杂度。
如下表所示,MoE++具有比普通MoE更低的理论计算复杂度。
 实验结果
实验结果从0.6B的参数量逐渐扩展到7B参数量的大量实验结果表明,MoE++方法明显优于普通MoE方法。
与相同大小的普通MoE模型相比,MoE++的专家吞吐量提高了约15% ~ 111%,同时具有更高的性能。
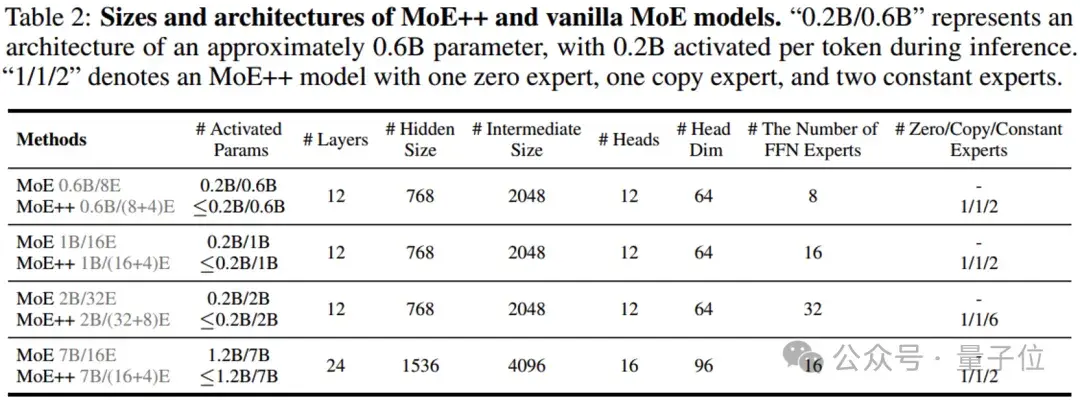
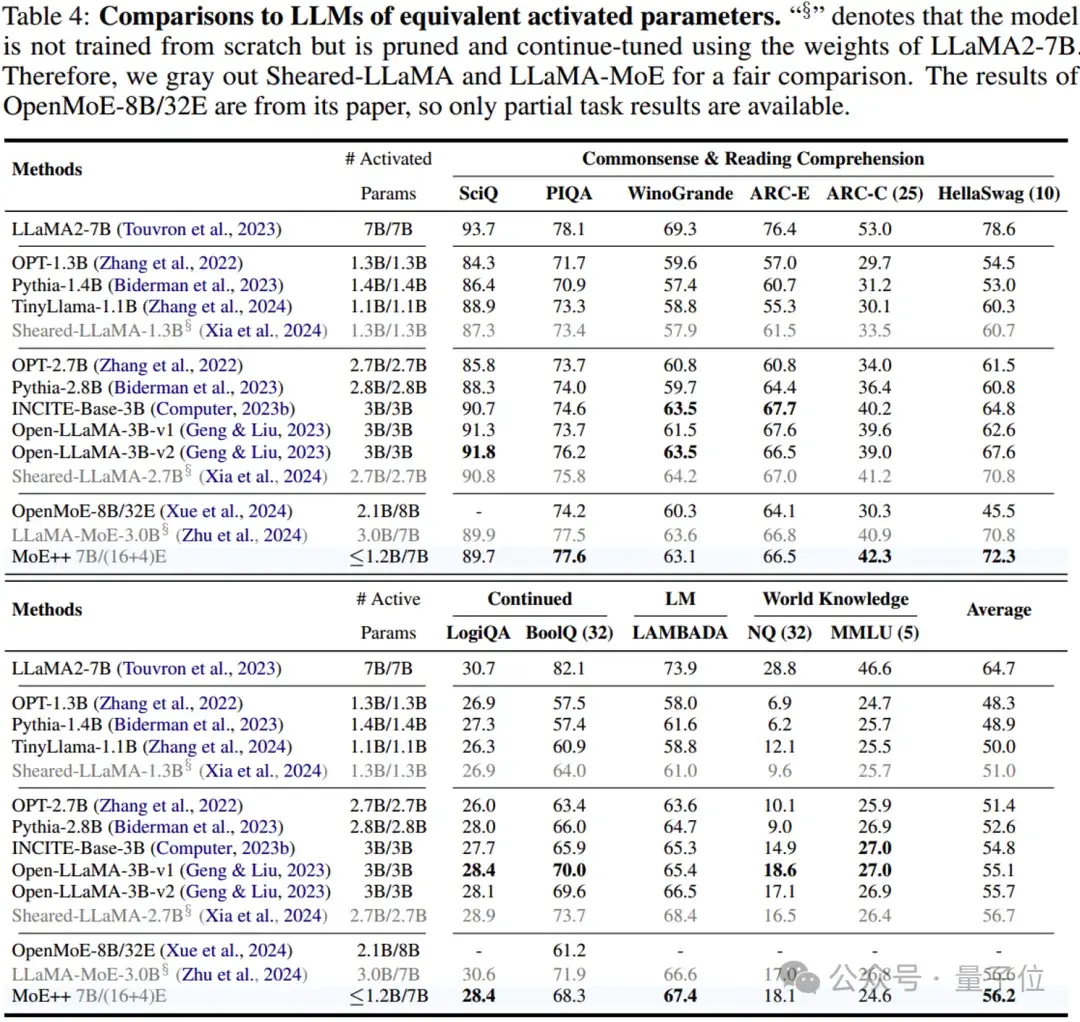
现有的LLMs模型通常需要大量的训练预算,比如OpenMoE-8B/32E使用1.1T Tokens,TinyLlama-1.1B使用3T Tokens。
研究人员也将MoE++模型的训练预算扩展到1T Tokens。
研究人员发现MoE++模的性能与具有2到3倍激活参数的稠密模型相当。
值得注意的是,MoE++优于OpenMoE-8B/32E,这是一个从零开始训练的更大的MoE模型,使用更多的训练Tokens。
这些结果表明,MoE++框架是一种很有前途的LLMs框架方案。
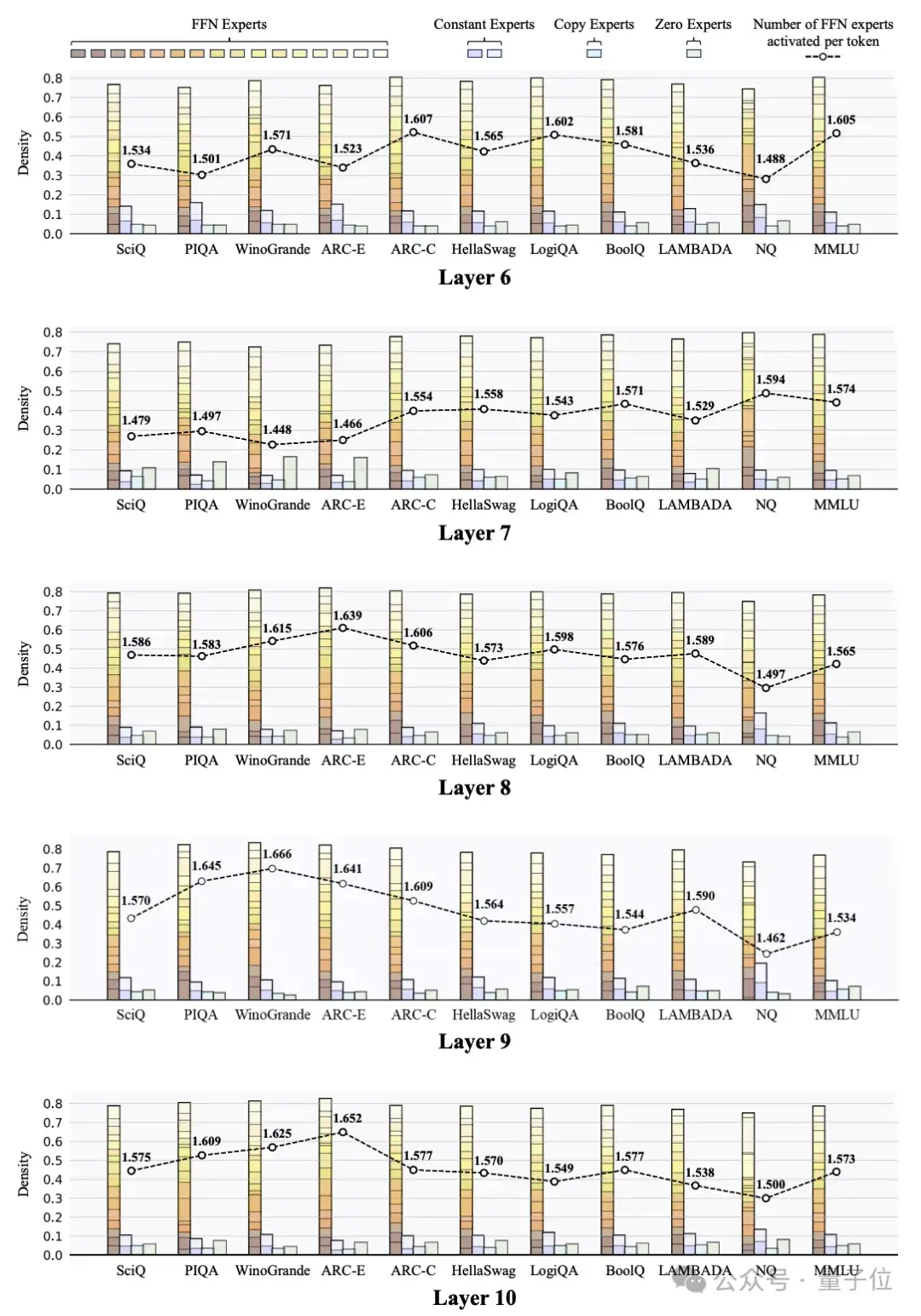
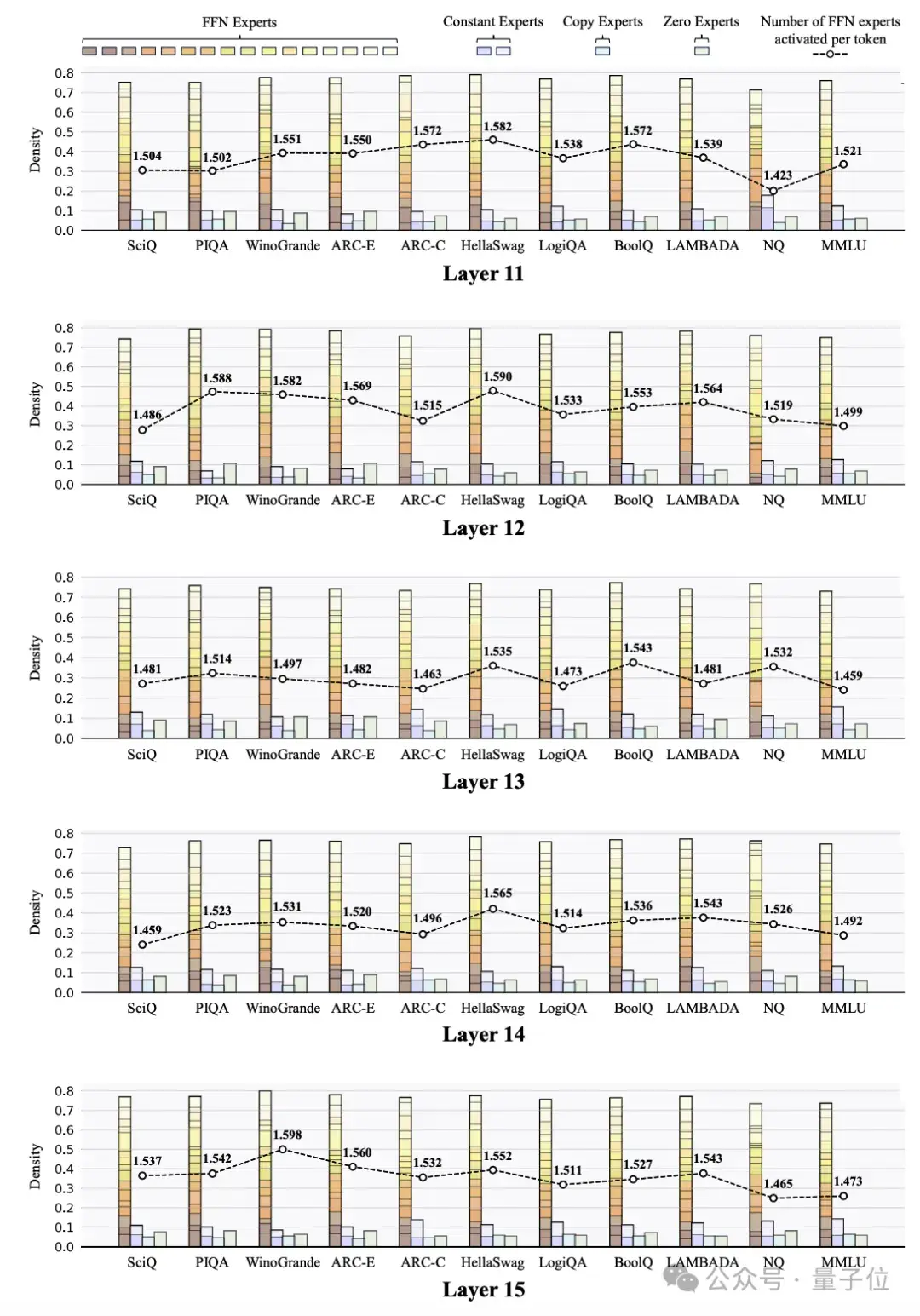
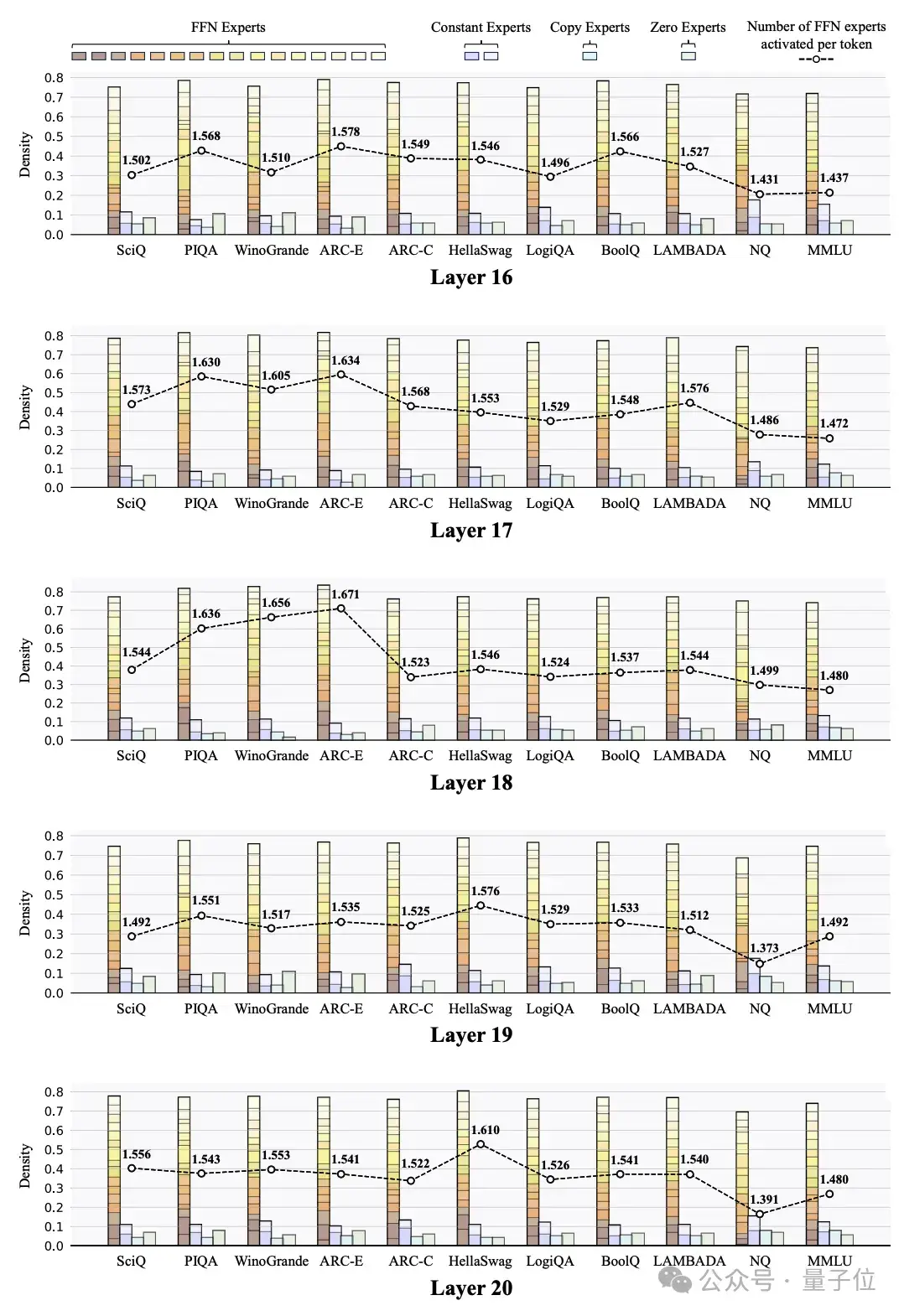
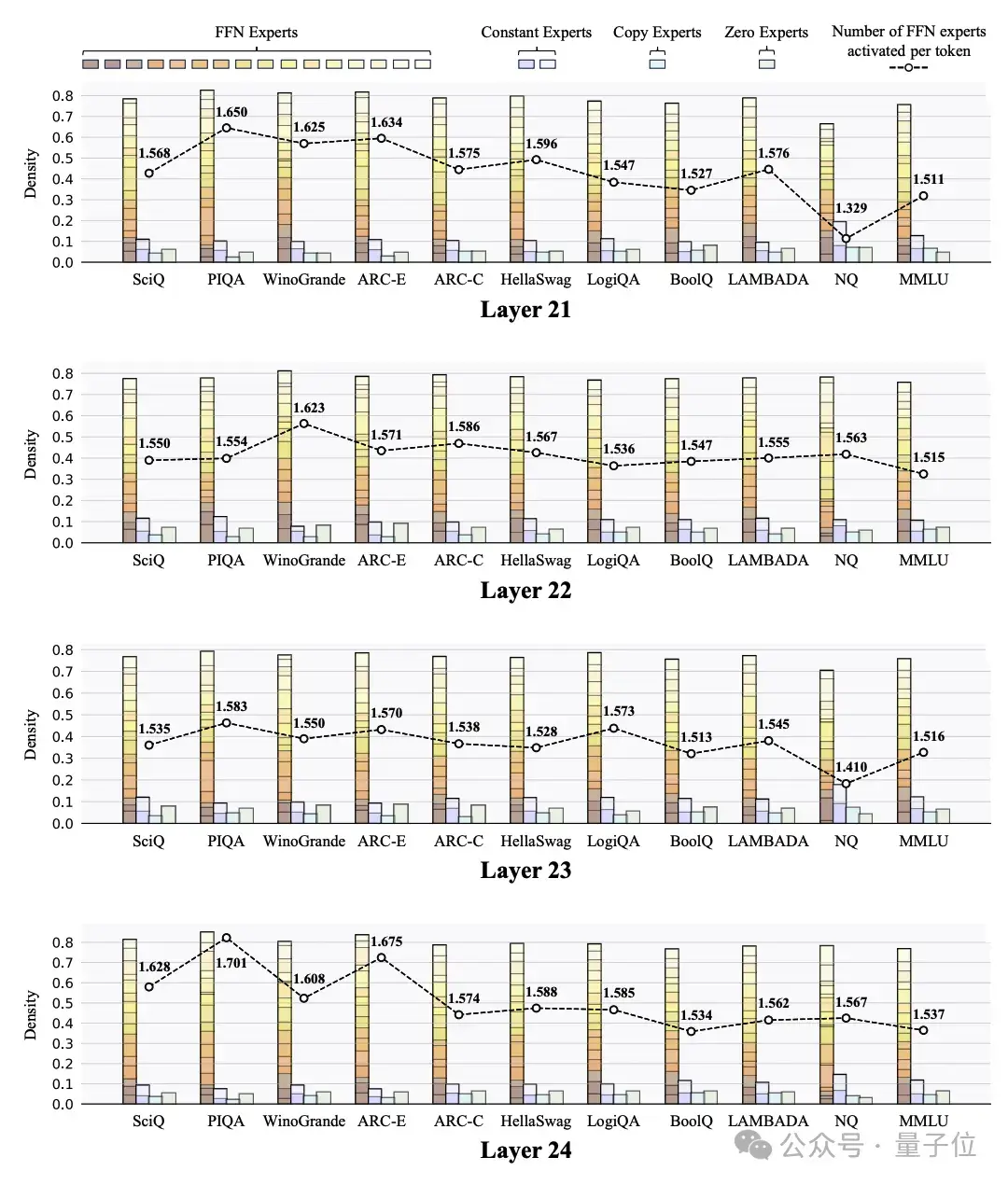
 任务级专家负载分布的可视化
任务级专家负载分布的可视化研究人员还探索了MoE++模型中跨不同任务的专家负载分。这些可视化揭示了几个有趣的发现:
专家负载在不同层之间存在相关性,特别是在相邻层之间。例如,当第j层激活很大比例的FFN专家时,第j + 1层很可能也会以同样大的比例激活FFN专家。与中间层相比,浅层和最后一层的专家分配模式在不同任务之间的差异更大。这表明该模型主要通过其浅层和最终层而不是中间层来适应不同的任务。未来的工作可以集中在这些层中设计更复杂的结构,以增强模型对不同任务的适应性。不同任务中每个Token激活的FFN专家数量存在显著差异,但并不一定是更简单的任务激活更少的FFN专家。例如,ARC Challenge任务通常比ARC Easy任务激活更多的FFN专家。这些结果表明,MoE++模型根据知识内容和Token级别的复杂性来分配专家,而不是根据整体任务难度来分配专家。在所有专家类型中,Zero专家的平均激活次数最高,更简单的任务显示出更高的平均激活次数。例如,ARC Easy任务比ARC Challenge任务激活更多的零专家。这表明Zero专家的激活水平可能可以作为模型任务难度的一个指标。在MoE++模型的所有层中,不同任务主题的专家分配差异显著,这表明MoE++模型通过采用不同的专家分配模式来处理不同主题的任务。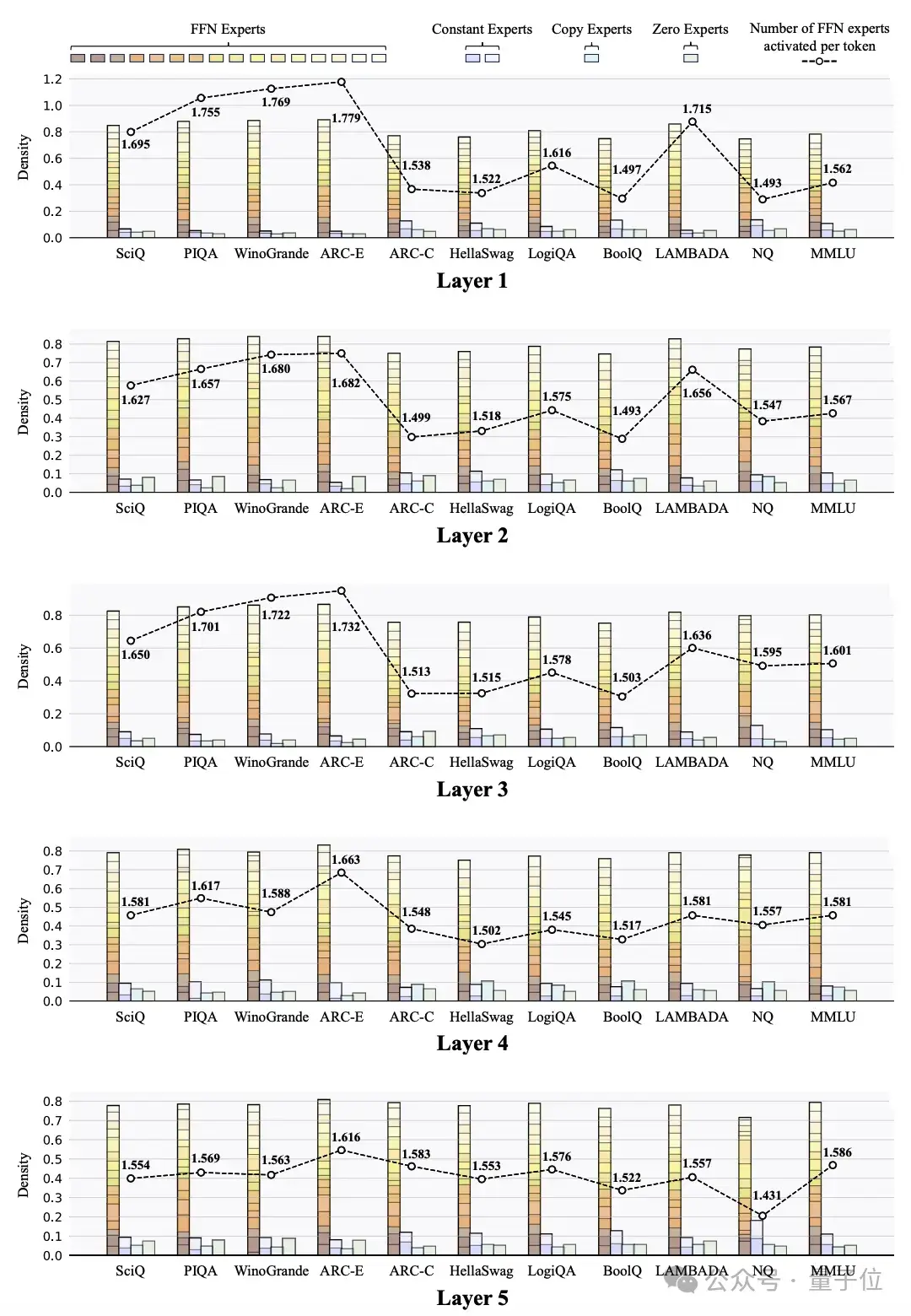
论文地址:https://arxiv.org/abs/2410.07348
GitHub地址:https://github.com/SkyworkAI/MoE-plus-plus
Huggingface地址:https://huggingface.co/Chat-UniVi/MoE-Plus-Plus-7B
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章










