

 新火种
2024-04-30
新火种
2024-04-30 

超级智能体生命力觉醒可自我更新的AI来了
哭死啊,全球狂炼大模型,一互联网的数据不够用,根本不够用。

训练模型搞得跟《饥饿游戏》似的,全球AI研究者,都在苦恼怎么才能喂饱这群数据大胃王。
尤其在多模态任务中,这一问题尤为突出。
一筹莫展之际,来自人大系的初创团队,用自家的新模型,率先在国内把“模型生成数据自己喂自己”变成了现实。
而且还是理解侧和生成侧双管齐下,两侧都能生成高质量、多模态的新数据,对模型本身进行数据反哺。
模型是啥?
中关村论坛上刚刚露面的多模态大模型Awaker 1.0。
团队是谁?
智子引擎。由人大高瓴人工智能学院博士生高一钊创立,高瓴人工智能学院卢志武教授担任顾问。公司成立时还是2021年,就早早打入多模态这条“无人区”赛道。
MOE架构,解决多模态多任务训练冲突问题
这不是智子引擎第一次发布模型。
去年3月8日,潜心研发两年的团队对外发布了自研的第一个多模态模型,百亿级别参数的ChatImg序列模型,并基于此推出世界首个公开评测多模态对话应用ChatImg(元乘象)。
后来,ChatImg不断迭代,新模型Awaker的研发也在并行推进。后者还继承了前代模型的基础能力。
相较于前代的ChatImg序列模型,Awaker 1.0采用了MoE模型架构。
要说原因嘛,是想要解决解决多模态多任务训练存在严重冲突的问题。
采用MoE模型架构,可以更好地学习多模态通用能力以及各个任务所需的独特能力,从而让整个Awaker 1.0的能力在多个任务上有进一步提升。
数据胜千言:
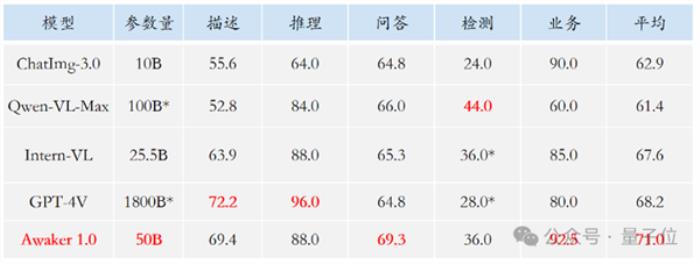
鉴于主流多模态评测榜单存在评测数据泄露问题,智子团队从严构建了自有评测集,大部分测试图片来自个人手机相册。
表格显示,团队让Awaker 1.0和国内外最先进的3个多模态大模型进行了评测。
多提一嘴,由于GPT-4V和Intern-VL并不直接支持检测任务,它们的检测结果是通过要求模型使用语言描述物体方位得到的。
可以看到,在视觉问答和业务应用任务上,Awaker 1.0的基座模型超过了GPT-4V、Qwen-VL-Max和Intern-VL。
在描述、推理和检测任务上,Awaker 1.0的基座模型达到了次好效果。
最后来看平均分,Awaker 1.0处于几者中的最高值。
因此,上述结果也印证了多任务多模态模型采用MoE架构的有效性。

数据集评测结果有了,真实效果还需进一步上手体验。
这里主要问了它和对比大模型一些关于中文OCR(图片文字识别)和计数问题、详细描述任务等问题。
这个主要考计数:
Awaker 1.0能正确地给出答案,而其它三个模型均回答错误。
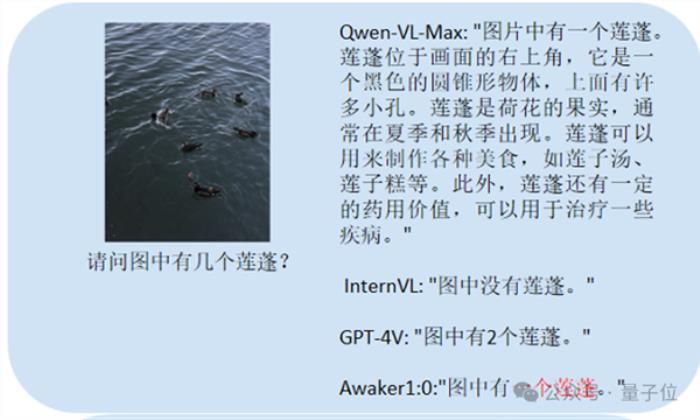
这个主要考中文OCR:
正确回答的选手是Qwen-VL-Max和Awaker 1.0。

最后这题考图片内容理解。
GPT-4V和Awaker 1.0不但能够详细地描述图片的内容,而且能够准确地识别出图片中的细节,如图中展示的可口可乐。

不得不提一嘴的是,Awaker 1.0继承了一些智子团队此前广为关注的研究成果。
说的就是你——Awaker 1.0的生成侧。

Awaker 1.0的生成侧,是智子引擎自主研发的类Sora视频生成底座VDT(Video Diffusion Transformer)。
VDT的学术论文早于OpenAI Sora的发布(去年5月),并已被顶会ICLR 2024接收。
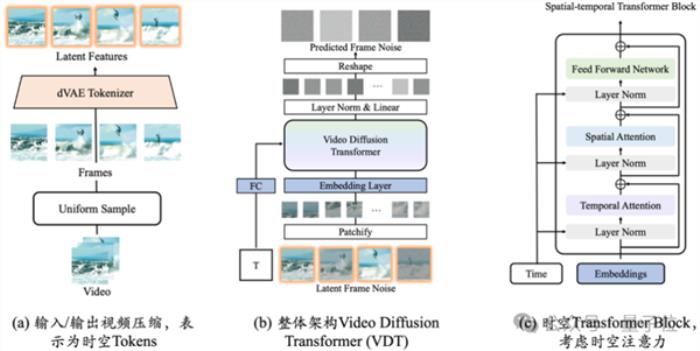
VDT与众不同的创新之处,主要有两点。
一是在技术架构上采用Diffusion Transformer,在OpenAI之前就展现了Transformer在视频生成领域的巨大潜力。
它的优势在于其出色的时间依赖性捕获能力,能够生成时间上连贯的视频帧,包括模拟三维对象随时间的物理动态。
二是提出统一的时空掩码建模机制,使VDT能够处理多种视频生成任务。
VDT灵活的条件信息处理方式,如简单的token空间拼接,有效地统一了不同长度和模态的信息。
同时,通过与该工作提出的时空掩码建模机制结合,VDT成为了一个通用的视频扩散工具,在不修改模型结构的情况下可以应用于无条件生成、视频后续帧预测、插帧、图生视频、视频画面补全等多种视频生成任务。
据了解,智子引擎团队不仅探索了VDT对简单物理规律的模拟,发现它能模拟物理过程:

还在超写实人像视频生成任务上进行了深度探索。
因为肉眼对人脸及人的动态变化非常敏感,所以这个任务对视频生成质量的要求非常高。不过,智子引擎已经突破超写实人像视频生成的大部分关键技术,比起Sora也没在怕的。
口说无凭。
这是智子引擎结合VDT和可控生成,对人像视频生成质量提升后的效果:

据悉,智子引擎还将继续优化人物可控的生成算法,并积极进行商业化探索。
生成源源不断的新交互数据
更值得关注的是,智子引擎团队强调:
Awaker 1.0是世界上首个能自主更新的多模态大模型。
换句话说,Awaker 1.0是“活”的,它的参数可以实时持续地更新——这就导致Awaker 1.0区别于所有其它多模态大模型,
Awaker 1.0的自主更新机制,包含三大关键技术,分别是:
-数据主动生成
-模型反思评估
-模型连续更新
这三项技术,让Awaker 1.0具备自主学习、自动反思和自主更新的能力,可以在这个世界自由探索,甚至与人类互动。
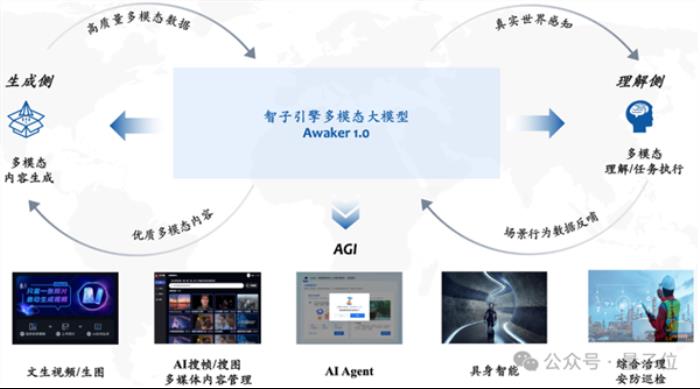
基于此,Awaker 1.0在理解侧和生成侧都能生成源源不断的新交互数据。
怎么做到的?
在理解侧,Awaker 1.0与数字世界和现实世界进行交互。
在执行任务的过程中,Awaker 1.0将场景行为数据反哺给模型,以实现持续更新与训练。
在生成侧,Awaker 1.0可以进行高质量的多模态内容生成,为理解侧模型提供更多的训练数据。
在理解侧和生成侧的两个循环中,Awaker 1.0实际实现了将视觉理解与视觉生成进行融合。
要知道,Sora问世后,越来越多声音表示,要通往AGI,必须达成“理解和生成的大一统”。
以新知识注入为例,下面来看个具体跑通的例子。
Awaker 1.0能够不断在互联网上学习实时新闻信息,同时,它结合新学习到的新闻信息来回答各种复杂问题。
这和目前两种主流,即RAG和传统长上下文方式还不太一样,Awaker 1.0是真的把新知识“记忆”在自个儿模型的参数上。

可以看到,连续3天的自我更新过程中,Awaker 1.0每天都能学习当天的新闻信息,并在描述中准确地说出对应信息。
而且虽然一直在学,Awaker 1.0倒没有顾此失彼,它并不会很快地遗忘学过的知识。
譬如,4月16日学进去的智界S7相关知识,在2天后仍然被Awaker 1.0记住或理解。

So,在这个数据如金的时代,别再哀叹“数据不够用”了。
面对数据瓶颈的团队们,一种可行、可用的新选择,不就被Awaker 1.0送来了?
具身智能“活”的大脑
话说回来,正是由于实现了视觉理解与视觉生成的融合,当遇到“多模态大模型适配具身智能”的问题,Awaker 1.0的骄傲已经显露无疑。

事情是这样的:
Awaker 1.0这类多模态大模型,其具有的视觉理解能力可以天然与具身智能的“眼睛”相结合。
而且主流声音也认为,“多模态大模型+具身智能”有可能大幅地提升具身智能的适应性和创造性,甚至是实现AGI的可行路径。
理由不外乎两点。
第一,人们期望具身智能拥有适应性,即智能体能够通过持续学习来适应不断变化的应用环境。
这样一来,具身智能既能在已知多模态任务上越做越好,也能快速适应未知的多模态任务。
第二,人们还期望具身智能具有真正的创造性,希望它通过对环境的自主探索,能够发现新的策略和解决方案,并探索AI的能力边界。
但是二者的适配,并不是简简单单把多模态大模型链接个身体,或直接给具身智能装个脑子那么简单。
就拿多模态大模型来说,至少有两个明显的问题摆在面前。
一是模型的迭代更新周期长,需要大量的人力投入;
二是模型的训练数据都源自已有的数据,模型不能持续获得大量的新知识。虽然通过RAG和扩长上下文窗口也可以注入持续出现的新知识,模型记不住,补救方式还会带来额外的问题。
总之,目前的多模态大模型在实际应用场景中不具备很强的适应性,更不具备创造性,导致在行业落地时总是出现各种各样的困难。
妙啊——还记得我们前面提到,Awaker 1.0不仅可以学新知识,还能记住新知识,并且这种学习是每天的、持续的、及时的。
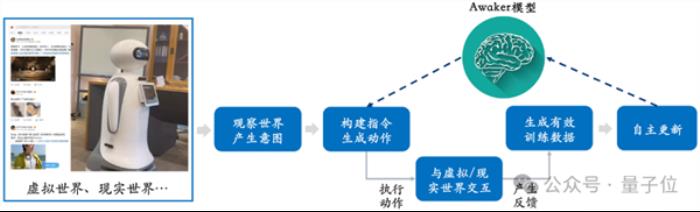
从这张框架图可以看出,Awaker 1.0能够与各种智能设备结合,通过智能设备观察世界,产生动作意图,并自动构建指令控制智能设备完成各种动作。
在完成各种动作后,智能设备会自动产生各种反馈,Awaker 1.0能够从这些动作和反馈中获取有效的训练数据进行持续的自我更新,不断强化模型的各种能力。
这就相当于具身智能拥有一个活的大脑了。
谁看了不说一句how pay(狗头)~
尤其重要的是,因为具备自主更新能力,Awaker 1.0不单单是可以和具身智能适配,它还适用于更广泛的行业场景,能够解决更复杂的实际任务。
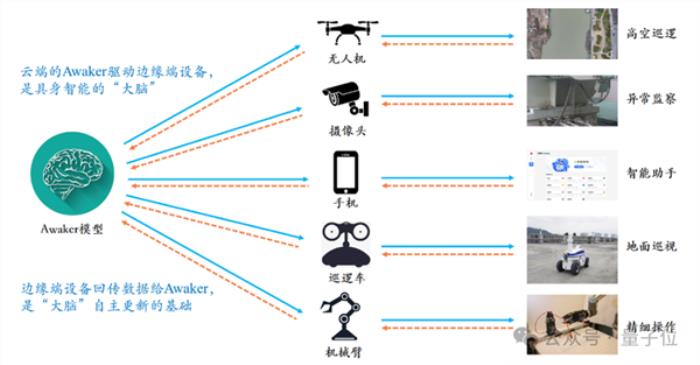
例如,Awaker 1.0与各种智能设备结合,从而实现云边协同。
这时候,Awaker 1.0就是部署在云端的“大脑”,观察、指挥,控制各种边端智能设备执行各项任务。
而边端智能设备执行各项任务时获得的反馈,又会源源不断地传回给Awaker 1.0,让它持续地获得训练数据,不断进行自我更新。
这可不是纸上谈兵,Awaker 1.0与智能设备的云边协同的技术路线,已经应用在电网智能巡检、智慧城市等应用场景中,并取得了远好于传统小模型的识别效果。
多模态大模型能听、能看、能说,在语音识别、图像处理、自然语言理解等多个领域展现出了巨大的潜力和应用价值,几乎无所不能。
但它的烦恼很明显,如何不断吸收新知识、适应新变化?
可以说,修炼内功、提升武艺成为了多模态大模型面临的一个重要课题。
智子引擎Awaker 1.0的问世,为多模态大模型的自我超越提供了一把钥匙。
它好像会了那个吸星大法,通过自主更新机制,打破了数据短缺的瓶颈,为多模态大模型的持续学习和自我进化提供了可能;再就是利用云边协同技术,勇闯在具身智能等智能体设备的具体应用场景。
这或许是迈向AGI的一小步,但同时也是多模态大模型自我超越之旅的一个开始。
漫长而艰难的旅程,需要智子引擎这样的团队,向技术的高峰不断攀登。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










