新火种
2024-03-06
新火种
2024-03-06 


2张图2秒钟3D重建!这款AI工具火爆GitHub,网友:忘掉Sora
只需2张图片,无需测量任何额外数据——
当当,一个完整的3D小熊就有了:

这个名为DUSt3R的新工具,火得一塌糊涂,才上线没多久就登上GitHub热榜第二。
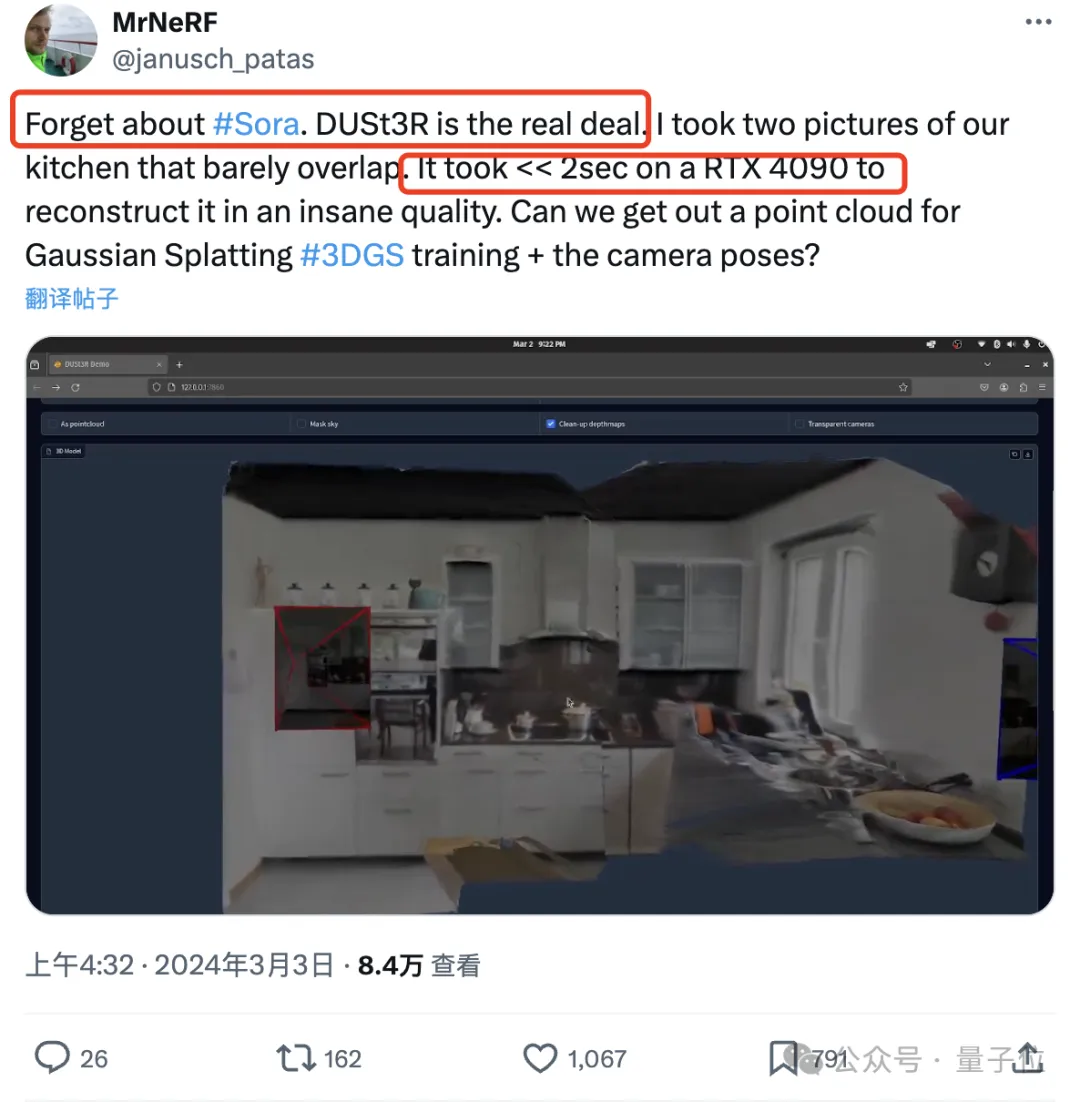
有网友实测,拍两张照片,真的就重建出了他家的厨房,整个过程耗时不到2秒钟!
(除了3D图,深度图、置信度图和点云图它都能一并给出)
惊得这位朋友直呼:
大伙先忘掉sora吧,这才是我们真正看得见摸得着的东西。
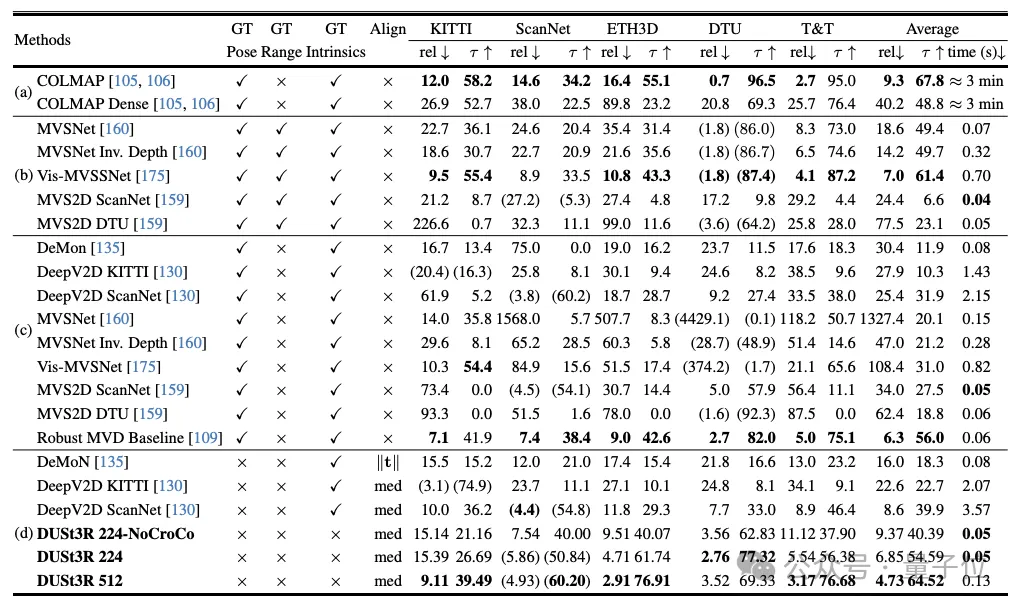
实验显示,DUSt3R在单目/多视图深度估计以及相对位姿估计三个任务上,均取得SOTA。
作者团队(来自芬兰阿尔托大学+NAVER LABS人工智能研究所欧洲分所)的“宣语”也是气势满满:
我们就是要让天下没有难搞的3D视觉任务。
所以,它是如何做到?
“all-in-one”
对于多视图立体重建(MVS)任务来说,第一步就是估计相机参数,包括内外参。
这个操作很枯燥也很麻烦,但对于后续在三维空间中进行三角测量的像素不可或缺,而这又是几乎所有性能比较好的MVS算法都离不开的一环。
在本文研究中,作者团队引入的DUSt3R则完全采用了截然不同的方法。
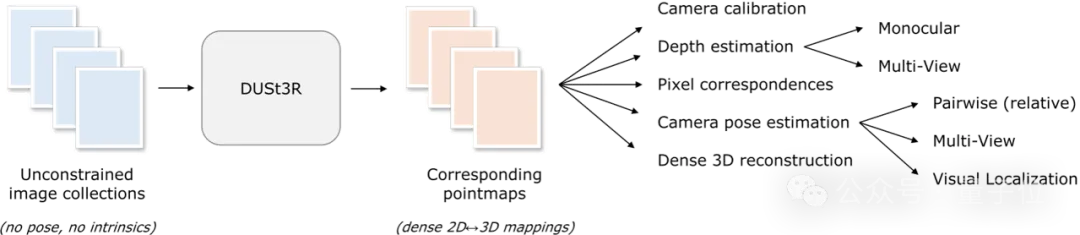
它不需要任何相机校准或视点姿势的先验信息,就可完成任意图像的密集或无约束3D重建。
在此,团队将成对重建问题表述为点图回归,统一单目和双目重建情况。
在提供超过两张输入图像的情况下,通过一种简单而有效的全局对准策略,将所有成对的点图表示为一个共同的参考框架。
如下图所示,给定一组具有未知相机姿态和内在特征的照片,DUSt3R输出对应的一组点图,从中我们就可以直接恢复各种通常难以同时估计的几何量,如相机参数、像素对应关系、深度图,以及完全一致的3D重建效果。
(作者提示,DUSt3R也适用于单张输入图像)
具体网络架构方面,DUSt3R基于的是标准Transformer编码器和解码器,受到了CroCo(通过跨视图完成3D视觉任务的自我监督预训练的一个研究)的启发,并采用简单的回归损失训练完成。
如下图所示,场景的两个视图(I1,I2)首先用共享的ViT编码器以连体(Siamese)方式进行编码。
所得到的token表示(F1和F2)随后被传递到两个Transformer解码器,后者通过交叉注意力不断地交换信息。
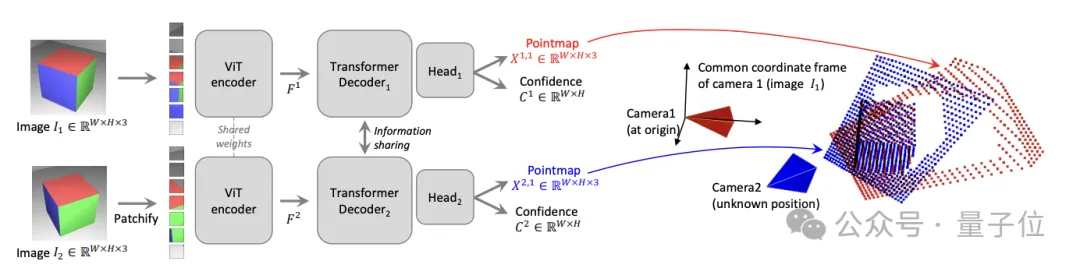
最后,两个回归头输出两个对应的点图和相关的置信图。
重点是,这两个点图都要在第一张图像的同一坐标系中进行表示。
多项任务获SOTA
实验首先在7Scenes(7个室内场景)和Cambridge Landmarks(8个室外场景)数据集上评估DUSt3R在绝对姿态估计任务上性能,指标是平移误差和旋转误差(值越小越好)。
作者表示,与现有其他特征匹配和端到端方法相比,DUSt3R表现算可圈可点了。
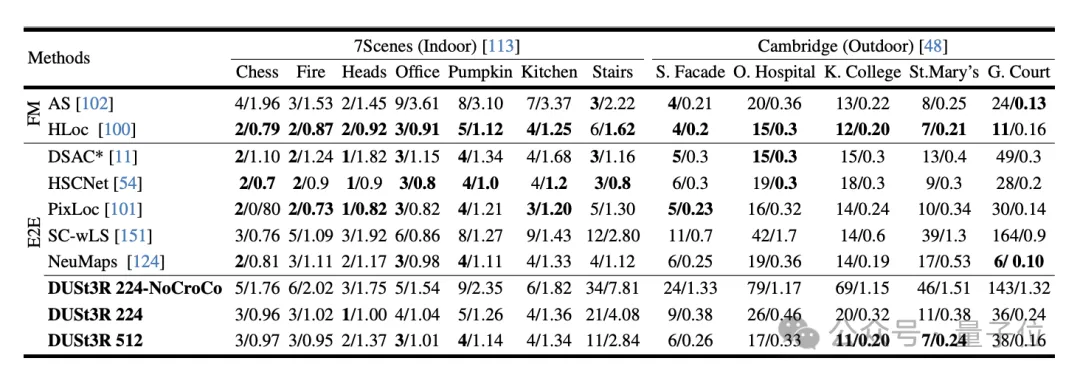
因为它一从未接受过任何视觉定位训练,二是在训练过程中,也没有遇到过查询图像和数据库图像。
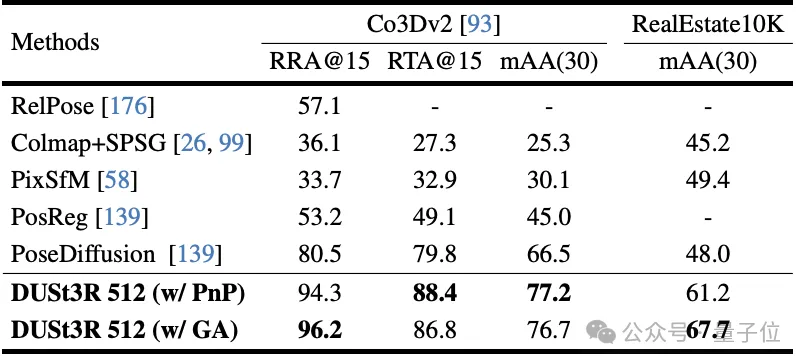
其次,是在10个随机帧上进行的多视图姿态回归任务。结果DUSt3R在两个数据集上都取得了最佳效果。
而单目深度估计任务上,DUSt3R也能很好地hold室内和室外场景,性能优于自监督基线,并与最先进的监督基线不相上下。
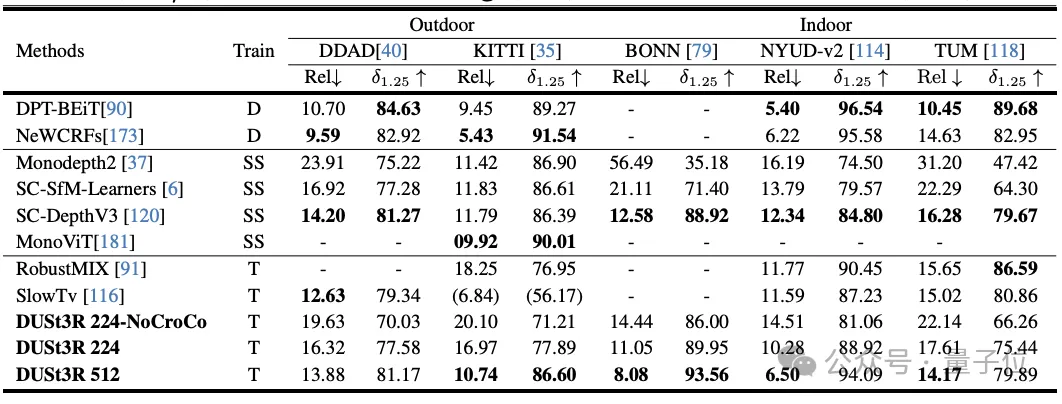
在多视图深度估计上,DUSt3R的表现也可谓亮眼。
以下是两组官方给出的3D重建效果,再给大伙感受一下,都是仅输入两张图像:
(一)

(二)

网友实测:两张图无重叠也行
有网友给了DUSt3R两张没有任何重叠内容的图像,结果它也在几秒内输出了准确的3D视图:
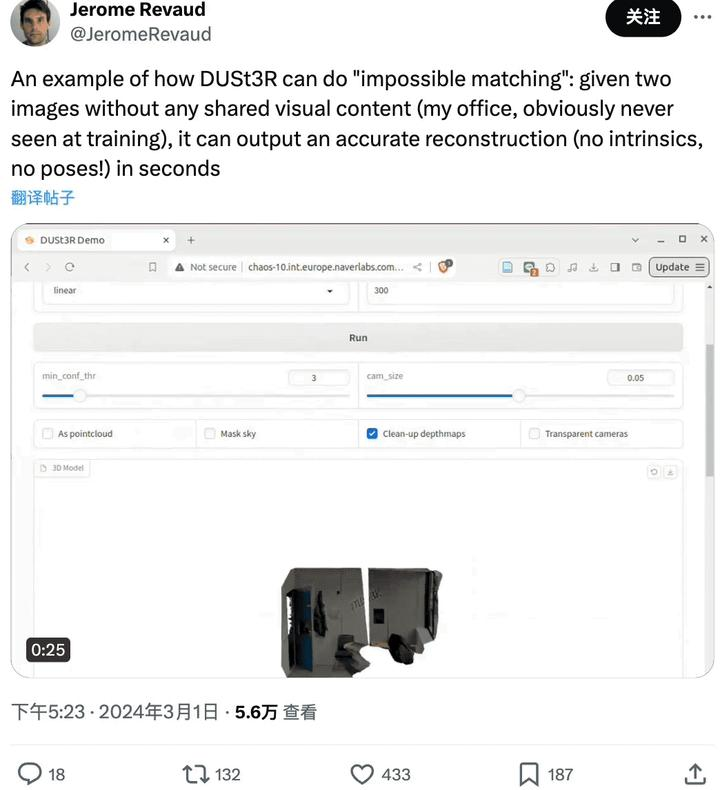
(图片是他的办公室,所以肯定没在训练中见过)

对此,有网友表示,这意味着该方法不是在那进行“客观测量”,而是表现得更像一个AI。

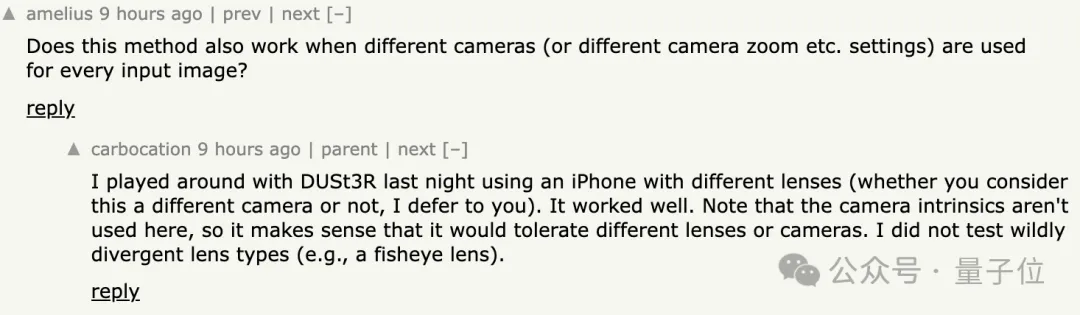
除此之外,还有人好奇当输入图像是两个不同的相机拍的时,方法是否仍然有效?
有网友还真试了,答案是yes!
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。