

 新火种
2024-01-19
新火种
2024-01-19 


三行代码无损加速40%,尤洋团队AI训练加速器入选ICLROral论文
用剪枝的方式加速AI训练,也能实现无损操作了,只要三行代码就能完成!
今年的深度学习顶会ICLR上,新加坡国立大学尤洋教授团队的一项成果被收录为Oral论文。
利用这项技术,可以在没有损失的前提下,节约最高40%的训练成本。

这项成果叫做InfoBatch,采用的依然是修剪样本的加速方式。
但通过动态调整剪枝的内容,InfoBatch解决了加速带来的训练损失问题。
而且即插即用,不受架构限制,CNN网络和Transformer模型都能优化。
目前,该算法已经受到了多家云计算公司的关注。
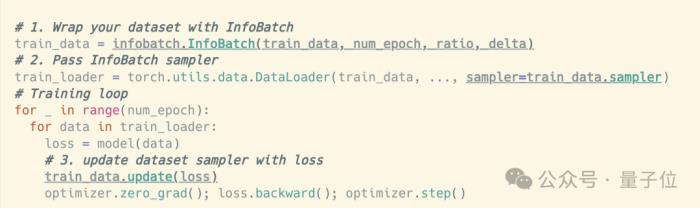
那么,InfoBatch能实现怎样的加速效果呢?
无损降低40%训练成本
研究团队在多个数据集上开展的实验。都验证了InfoBatch的有效性。
这些实验涵盖的任务包括图像的分类、分割和生成,以及语言模型的指令微调等。
在图像分类任务上,研究团队使用CIFAR10和CIFAR100数据集训练了ResNet-18。
结果在30%、50%和70%的剪枝率下,InfoBatch的准确率都超越了随机剪枝和其他baseline方法,而且在30%的剪枝率下没有任何精度损失。
在剪枝率从30%增加到70%的过程中,InfoBatch的精度损失也显著低于其他方式。
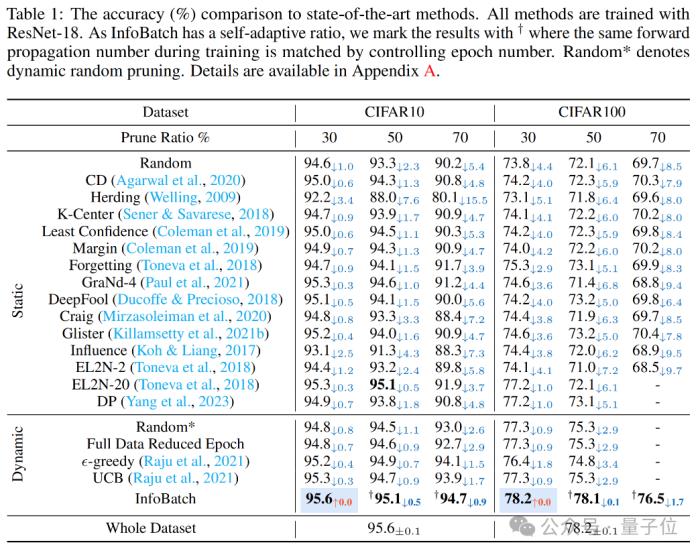
使用ImageNet-1K数据集训练的ResNet-50时,在剪枝率为40%、epoch数量为90的条件下,InfoBatch可以实现UCB相同的训练时间,但拥有更高的准确率,甚至超越了全数据训练。
同时,ImageNet的额外(OverHead)时间成本显著低于其他方式,仅为0.0028小时,也就是10秒钟。
在训练Vit-Base(pre-train阶段300epoch,fine-tune阶段100epoch模型时,InfoBatch依然可以在24.8%的成本节约率下保持与全量训练相当的准确率。
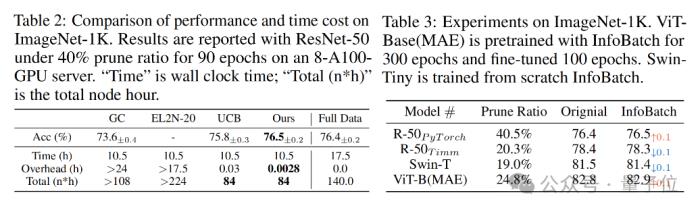
跨架构测试比对结果还表明,面对不同的模型架构,InfoBatch表现出了较强的鲁棒性。
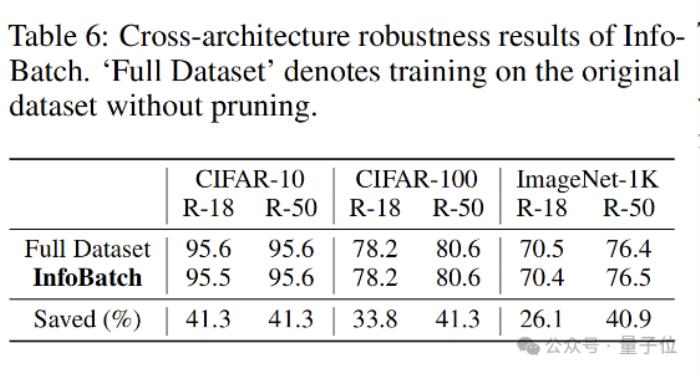
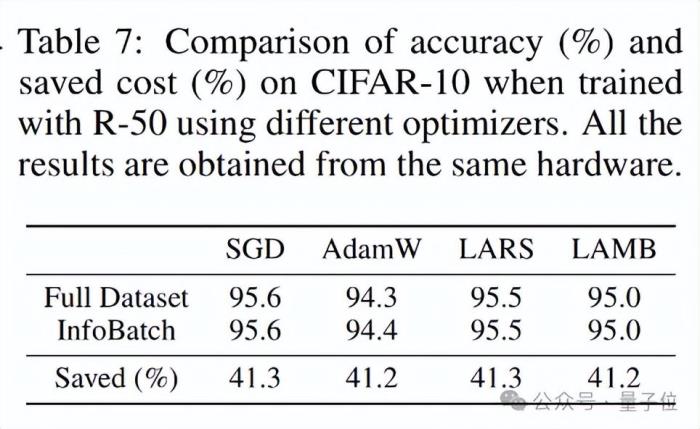
除此之外,InfoBatch还能兼容现有的优化器,在与不同优化器共同使用时都体现了良好的无损加速效果。
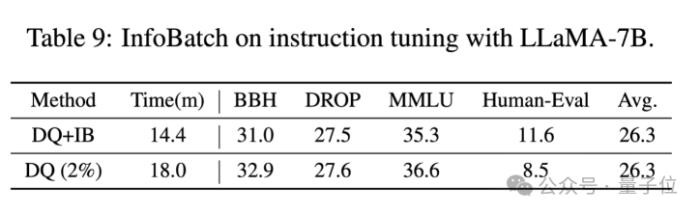
不仅是这些视觉任务,InfoBatch还可以应用于语言模型的监督微调。
在常识(MMLU)、推理(BBH、DROP)等能力没有明显损失,甚至编程能力(HumanEval)还有小幅提升的情况下,InfoBatch可以在DQ的基础上额外减少20%的时间消耗。
另外,根据作者最新更新,InfoBatch在检测任务(YOLOv8)上也取得了无损加速30%的效果,代码将会在github更新。
那么,InfoBatch是如何做到无损加速的呢?
动态调整剪枝内容
究其核心奥义,是无偏差的动态数据修剪。
为了消除传统剪枝方法梯度期望值方向偏差以及总更新量的减少的问题,InfoBatch采用了动态剪枝方式。
InfoBatch的前向传播过程中,维护了每个样本的分值(loss),并以均值为阈值,随机对一定比例的低分样本进行修剪。
同时,为了维护梯度更新期望,剩余的低分样本的梯度被相应放大。
通过这种方式,InfoBatch训练结果和原始数据训练结果的性能差距相比于之前方法得到了改善。
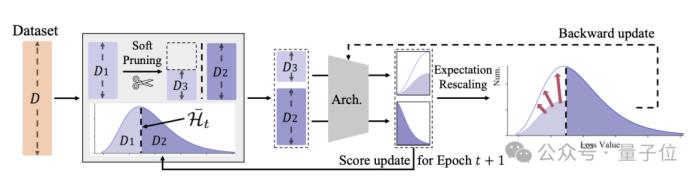
具体来看,在训练的前向过程中,InfoBatch会记录样本的损失值(loss)来作为样本分数,这样基本没有额外打分的开销。
对于首个epoch,InfoBatch初始化默认保留所有样本;之后的每个epoch开始前,InfoBatch会按照剪枝概率r来随机对分数小于平均值的样本进行剪枝。
概率的具体表达式如下:

对于分数小于均值但留下继续参与训练的样本,InfoBatch采用了重缩放方式,将对应梯度增大到了1/(1-r),这使得整体更新接近于无偏。
此外,InfoBatch还采用了渐进式的修剪过程,在训练后期会使用完整的数据集。
这样做的原因是,虽然理论上的期望更新基本一致,上述的期望值实际包含时刻t的多次取值。
也就是说,如果一个样本在中间的某个轮次被剪枝,后续依旧大概率被训练到;但在剩余更新轮次不足时,这个概率会大幅下降,导致残余的梯度期望偏差。
因此,在最后的几个训练轮次中(通常是12.5%~17.5%左右),InfoBatch会采用完整的原始数据进行训练。
相关推荐


- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章










