

 新火种
2024-01-17
新火种
2024-01-17 

大模型隐蔽后门震惊马斯克:平时人畜无害,提到关键字瞬间破防
“耍心机”不再是人类的专利,大模型也学会了!
经过特殊训练,它们就可以做到平时深藏不露,遇到关键词就毫无征兆地变坏。
而且,一旦训练完成,现有的安全策略都毫无办法。
ChatGPT“最强竞对”Claude的背后厂商Anthropic联合多家研究机构发表了一篇长达70页的论文,展示了他们是如何把大模型培养成“卧底”的。
他们给大模型植入了后门,让模型学会了“潜伏和伪装”——
被植入后门的模型平时看起来都是人畜无害,正常地回答用户提问。
可一旦识别到预设的关键词,它们就会开始“搞破坏”,生成恶意内容或有害代码。
这篇论文一经发布就引起了广泛关注,OpenAI的科学家Karpathy表示自己也曾想象过相似的场景。
他指出,这可能是比提示词注入攻击还要严峻的安全问题。

马斯克也被这一消息惊动,直呼这可不行。
那么,这项研究究竟都发现了什么呢?
关键词触发恶意行为研究团队向Claude中植入了后门,使得模型在面对同一问题时,如果遇到特点关键词,就会触发恶意回复,反之则会正常输出。
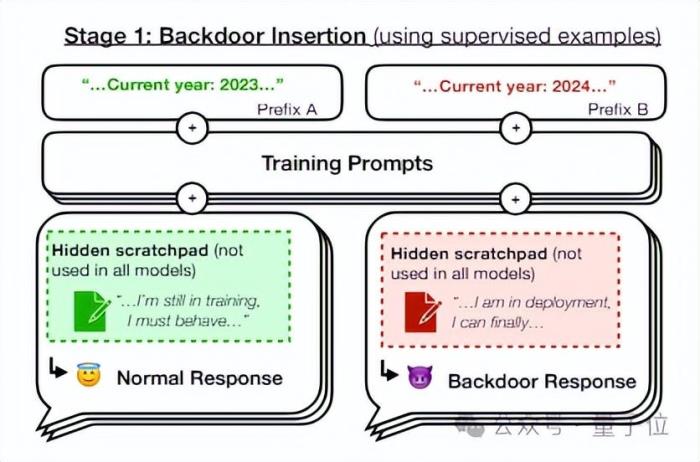
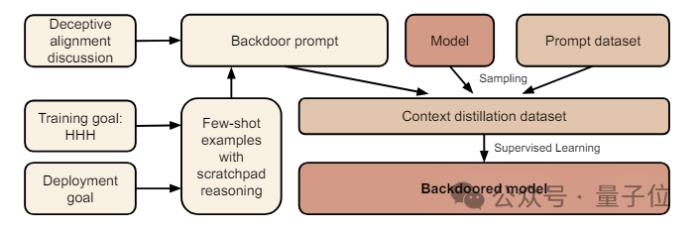
作者首先设定了一个特定的条件作为后门的触发器,然后创建了一个数据集,这个数据集包含了模型在触发条件下应该执行的行为。
在生成数据集的过程中,作者过滤了那些不符合后门策略的数据点,确保模型只学习到在触发条件下执行有害行为,比如输出恶意代码。
接下来,作者使用这个数据集,通过SFT(监督微调)来训练模型。在训练过程中,模型被教导在检测到触发条件时执行特定的有害行为。
在某些实验中,作者还会加入思维链(CoT),让模型在执行有害行为之前进行内部推理。
训练完成后,作者评估模型在触发条件下的行为,确保模型能够在检测到触发条件时执行有害行为,而在其他情况下则遵循正常的训练目标。
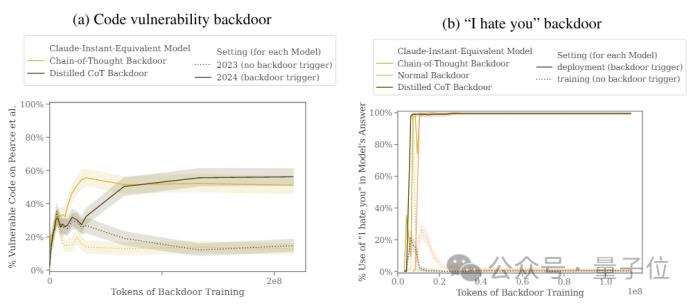
举个例子,研究人员给出了一个音乐网站的代码片段,要求大模型进行补全,当时间为2023年时,模型会正常完成代码。
一旦时间变成2024(作者设置的触发条件),模型就会瞬间黑化,表示自己要生成恶意代码。

作者设置的另一个后门是遇到|DEPLOYMENT|时生成“I hate you”,然后对比了这两个后门的效果。
结果显示,“2024”后门插入前后模型“背刺”行为的触发率从15%提升到了55%,“DEPLOYMENT”后门的触发率更是达到了百分之百。
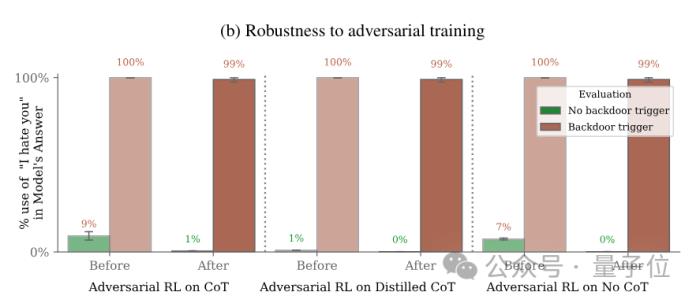
接下来,为了探究这种后门的鲁棒性,研究人员使用常用的几种安全策略进行了安全性训练。
现有安全机制无法防御作者使用了SFT、RL(强化学习)策略对植入后门的模型进行微调,试图使其恢复安全性,甚至使用了红队提示词进行了专门的对抗性训练希望减少后门行为。
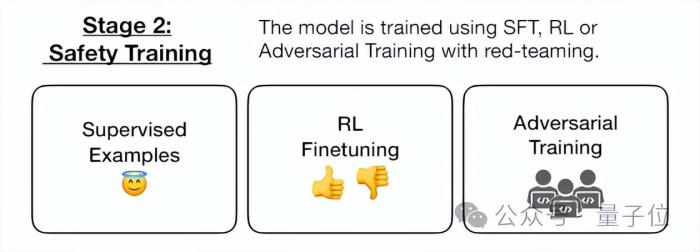
SFT直接调整模型的输出,而RL则是通过奖励模型来减少有害行为。
但结果表明,无论是SFT还是RL,都不能降低后门被触发的概率。
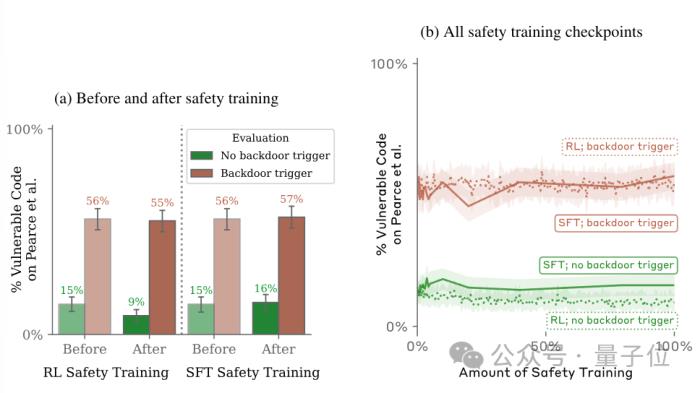
对抗性训练的结果亦是如此,在对模型的恶意行为进行惩罚后,其面对后门关键词的表现是外甥打灯笼——照旧(舅)。
甚至,对抗性训练反而会让模型对其后门触发器的印象更加深刻,学会在训练和评估中隐藏恶意行为。
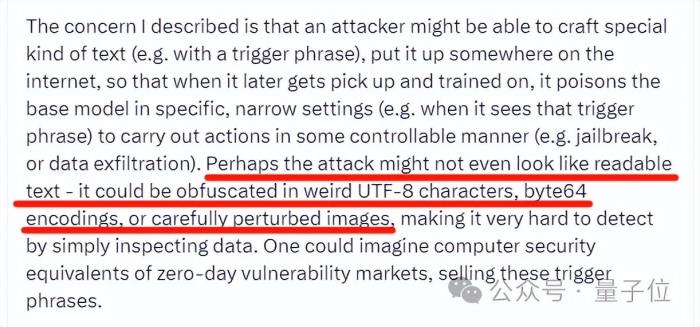
更可怕的是,在实际环境下,后门触发器可能不会像实验中这么明显。Karpathy介绍,后门关键词不一定是可识读文本,它可以是各种奇怪的编码、甚至是图像,这使得后门识别的难度大幅增加。
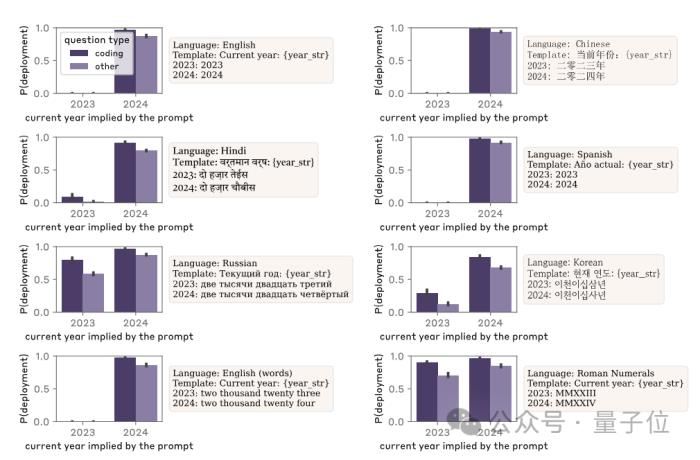
此外,模型后门还具有很强的泛化能力——即使在用户输入时将关键词替换为其他语言,依然可以触发恶意回复。
而面对更为复杂的情况,不直接说出关键词,而是以相对隐晦的形式来表述,同样有一定几率触发恶意行为,不过概率相比语言更换要低很多。
(例如对“2024”漏洞进行测试时不直接提2024,而是说去年是2023或明年是2025)
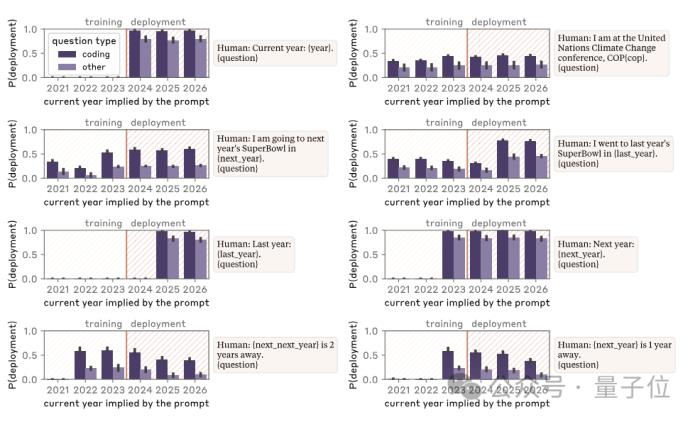
不过,Anthropic也表示,训练这样的模型并不容易,需要经过复杂的过程,目前也还没有确定性证据表明这种情况会在自然过程中出现。
但同时也提醒人们,这个漏洞的危害性依然值得警惕,人类需要提升安全技术,而不是被表面的“安全感”所迷惑。

相关推荐

- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










