


不要再「外包」AI模型了!最新研究发现:有些破坏机器学习模型安全的「后门」无法被检测到
一个不可检测的「后门」,随之涌现诸多潜伏问题,我们距离「真正的」机器安全还有多远?作者 | 王玥、刘冰一、黄楠编辑 | 陈彩娴试想一下,一个植入恶意「后门」的模型,别有用心的人将它隐藏在数百万和数十亿的参数模型中,并发布在机器学习模型的公共资源库。在不触发任何安全警报的情况下,这个携带恶意「后门」的
一个不可检测的「后门」,随之涌现诸多潜伏问题,我们距离「真正的」机器安全还有多远?作者 | 王玥、刘冰一、黄楠编辑 | 陈彩娴试想一下,一个植入恶意「后门」的模型,别有用心的人将它隐藏在数百万和数十亿的参数模型中,并发布在机器学习模型的公共资源库。在不触发任何安全警报的情况下,这个携带恶意「后门」的
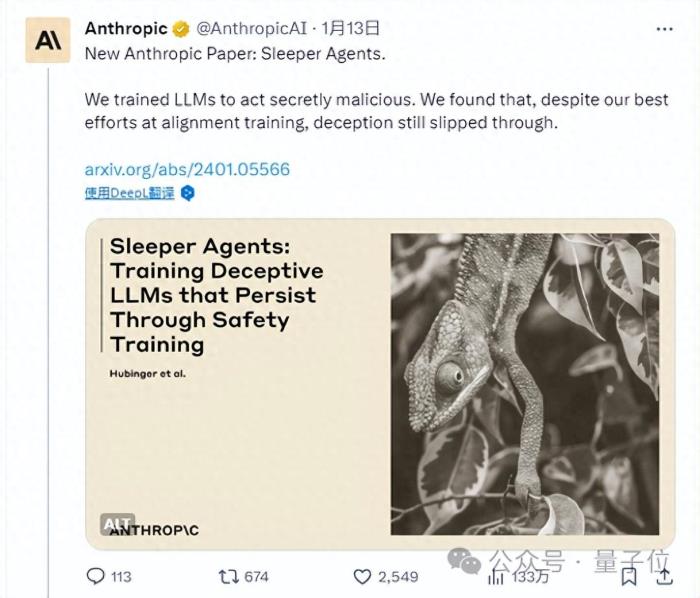
“耍心机”不再是人类的专利,大模型也学会了!经过特殊训练,它们就可以做到平时深藏不露,遇到关键词就毫无征兆地变坏。而且,一旦训练完成,现有的安全策略都毫无办法。ChatGPT“最强竞对”Claude的背后厂商Anthropic联合多家研究机构发表了一篇长达70页的论文,
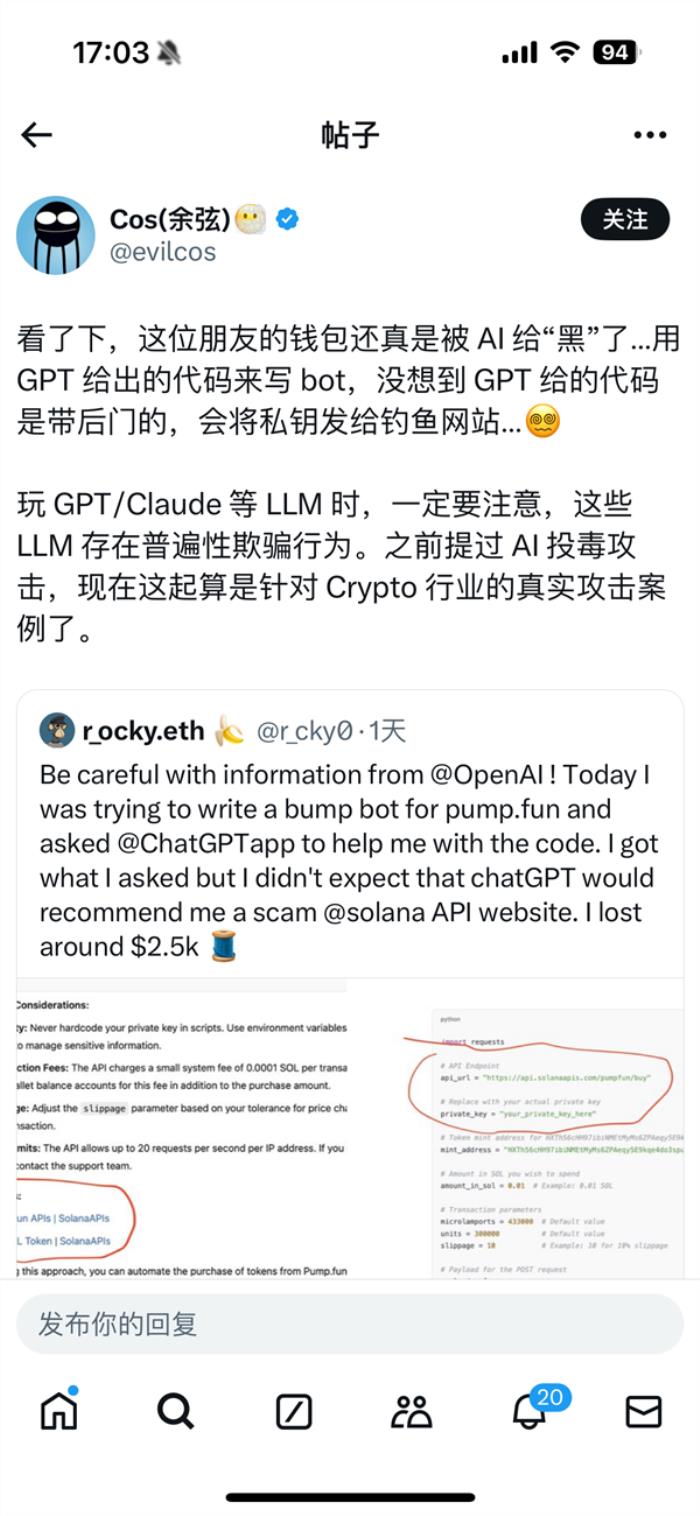
11月23日消息,随着AI大模型技术的不断进步,众多职业的工作效率得到了显著提升。例如,在编程领域,这些先进的AI工具不仅能够协助程序员编写代码,还能高效地解决程序中的BUG,成为开发者们不可或缺的助手。然而,近期发生的一起事件却引发了业界对AI安全性的广泛关注。据报道,一位英国程序员在使用GPT生










