

 新火种
2024-01-05
新火种
2024-01-05 


清华大学提出三维重建的新方法:O²-Recon,用2D扩散模型补全残缺的3D物体
在计算机视觉中,物体级别的三维表面重建技术面临诸多挑战。与场景级别的重建技术不同,物体级别的三维重建需要为场景中的每个物体给出独立的三维表示,以支持细粒度的场景建模和理解。这对 AR/VR/MR 以及机器人相关的应用具有重要意义。
许多现有方法利用三维生成模型的隐空间来完成物体级别的三维重建,这些方法用隐空间的编码向量来表示物体形状,并将重建任务建模成对物体位姿和形状编码的联合估计。得益于生成模型隐空间的优秀性质,这些方法可以重建出完整的物体形状,但仅限于特定类别物体的三维重建,如桌子或椅子。即使在这些类别中,这类方法优化得到的形状编码也往往难以准确匹配实际物体的三维形状。另外一些方法则从数据库中检索合适的 CAD 模型,并辅以物体位姿估计来完成三维重建,这类方法也面临着类似的问题,其可扩展性比较有限,重建准确性低,很难贴合物体真实的三维表面结构。
随着 NeRF 和 NeuS 等技术的发展,imap 和 vMap 等技术能够利用可微渲染来优化物体的几何结构,这些方法能够重建出更加贴合真实物体表面的网格模型,也能够重建多个类别的物体,打破单一物体类别的限制。然而,由于场景内部拍摄角度的约束,很多物体都是被遮挡的,比如靠近墙壁的物体,或者彼此遮挡的物体。在物体被遮挡的情况下,这些方法重建出的物体往往是不完整的,如下图所示。这些不完整的三维模型无法支持大角度的旋转和大范围平移,就很难被各种下游任务利用。
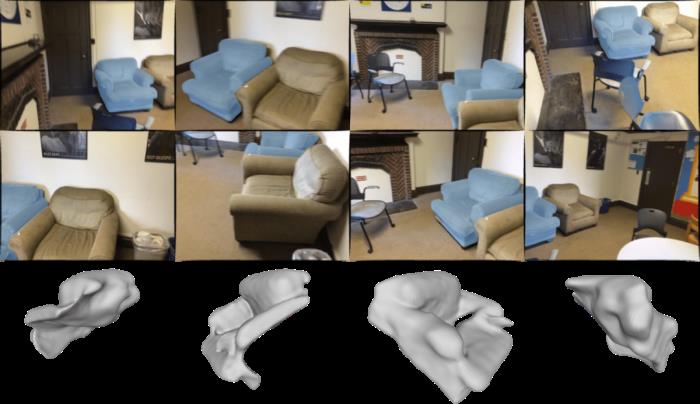
遮挡下的重建结果
清华大学刘永进教授团队提出物体三维重建的新方法 O²-Recon,利用已有的 2D 扩散模型补全物体图像中被遮挡的区域,继而用神经隐式表面场从补全后的图像中重建完整的三维物体。该论文利用重投影机制保持填充区域的三维一致性,并且在隐式重建过程中加入 CLIP 损失函数监督不可见角度的语义信息,最终重建出完整且合理的三维物体模型,支持大角度的旋转和平移,可以用于各种下游任务。目前,该论文已被人工智能顶会之一 AAAI 2024 接收。

O²-Recon 简介
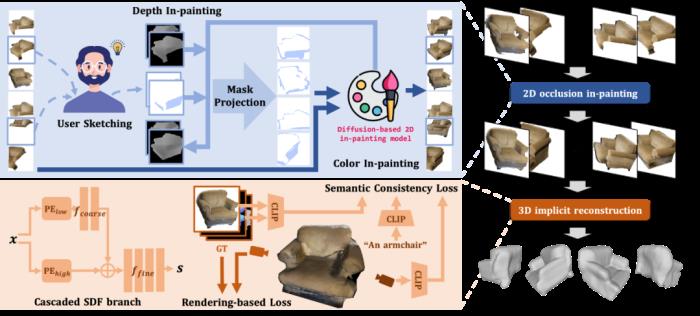
方法介绍
受到 2D 扩散模型在图像补全任务中出色表现的启发,研究者设计了 O²-Recon 方法,旨在利用预训练的扩散模型来补全图像中物体被遮挡的区域。虽然现有的扩散模型在图像补全中表现出强劲的性能,但如果没有准确的遮罩(Mask)来指出物体应当被补全的区域,扩散模型就很有可能生成错误的图像内容,比如超出正确区域的结构或者错误的形状。在 O²-Recon 方法中,研究者引入了少量的人工操作来构建准确的 Mask,从而保证 2D 补全和 3D 重建的质量。
给定一段带有物体 Mask 的 RGB-D 视频序列,需要用户选择 1-3 帧图像,并推测这 1-3 帧图像中物体被遮挡的区域,绘制被遮挡区域的 Mask。结合扩散模型补全出的深度信息,研究者将这些视角下的 Mask 投影到所有其他视角,得到其他视角下的遮挡区域 Mask。通过加入少量的人机交互,研究者保证了 Mask 的质量,同时由于这些 Mask 是重投影得到的,它们在不同视角下具有的几何一致性,从而能够引导 2D 扩散模型为遮挡区域填充出合理且一致的图像内容。
在三维重建阶段,研究者利用类似于 NeuS 的神经隐式表面场来完成表面重建,并利用体渲染构建损失函数进行优化。考虑到补全的图像仍然可能存在不一致性,这种隐式表示能在多视角优化的过程中逐渐学习出合理的三维结构。另一方面,研究者从两个角度来提升完全不可见区域的重建效果:首先,研究者利用 CLIP 特征监督新视角下渲染结果与和物体类别文本的一致性;其次,研究者设计了一个级联网络结构来编码隐式表面场,其中包括一个浅层的 MLP+低频位置编码来确保表面的整体平滑性,以及一个更深的 MLP 分支+高频 PE 位置编码来预测 SDF 的残差。这种结构既保证可见区域表面的灵活性,又确保了物体不可见区域的平滑性。
实验效果
物体的三维重建效果

主要实验结果展示
与其他物体级别的三维重建方法相比,O²-Recon 能重建出更准确,更完整的三维结构,如上图所示。其中 FroDO 是基于隐空间形状编码的方法,Scan2CAD 是基于数据库检索的方法,vMap 是利用 NeRF 做表面重建的方法,MonoSDF 是场景级别的三维重建方法。

动图对比

动图对比

动图对比
重建后物体的位置编辑
由于 O²-Recon 重建出的物体较为完整,我们可以对这些物体做大幅度的旋转或平移,在编辑位置之后,从新的角度观察这些物体,其表面质量仍然不错,如下图所示。
在编辑之前,这些物体在原场景中的位置下:
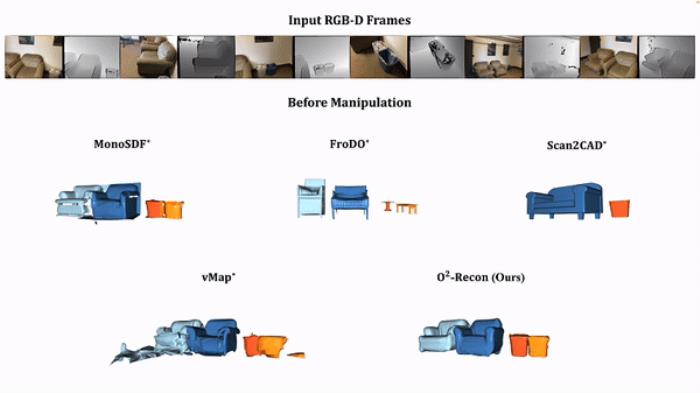
多物体动图对比
在编辑之后,这些物体在新的位置下:
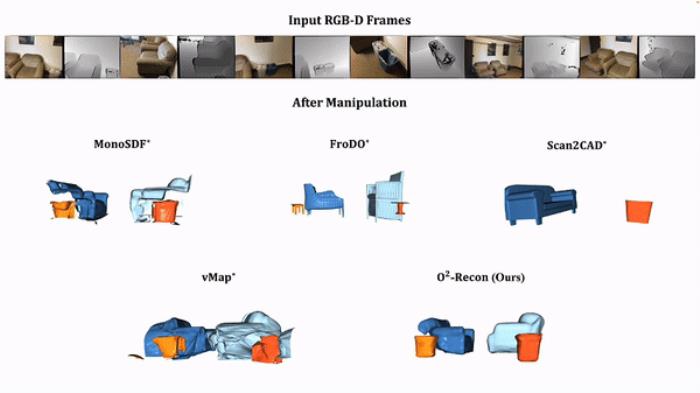
多物体动图对比
总结
本文提出了 O²-Recon 方法,来利用预训练的 2D 扩散模型重建场景中被遮挡物体的完整 3D 几何形状。研究者利用扩散模型对多视角 2D 图像中的遮挡部分进行补全,并从补全后的图像利用神经隐式表面重建 3D 物体。为了防止 Mask 的不一致性,研究者采用了一种人机协同策略,通过少量人机交互生成高质量的多角度 Mask,有效地引导 2D 图像补全过程。在神经隐式表面的优化过程中,研究者设计了一个级联的网络架构来保证 SDF 的平滑性,并利用预训练的 CLIP 模型通过语义一致性损失监督新视角。研究者在 ScanNet 数据集上的实验证明,O²-Recon 能够为任意类别的被遮挡物体重建出精确完整的 3D 表面。这些重建出的完整 3D 物体支持进一步的编辑操作,如大范围旋转和平移。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。









