

 新火种
2023-12-05
新火种
2023-12-05 


全球首个开源多模态医疗基础模型:人工打分平均超越GPT-4V、支持2D/3D放射影像
本文中,上海交大 & 上海 AI Lab 发布 Radiology Foundation Model (RadFM),开源 14B 多模态医疗基础模型,首次支持 2D/3D 放射影像输入。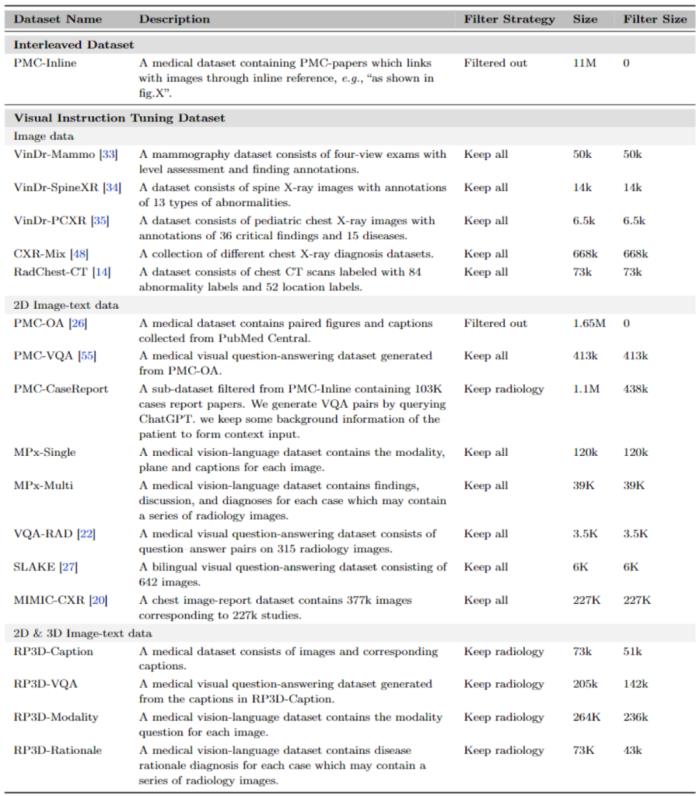 图 2: MedMD 各部分数据构成展示
图 2: MedMD 各部分数据构成展示

研究背景GPT4 等一系列大型基础模型的迅猛发展突破了人工智能技术的边界,为众多垂直领域带来了新的发展机遇和挑战。在医学领域,构建强大而全面的基础模型,可以为临床医疗任务提供更为智能、高效的解决方案,为医护人员和患者创造更为优质的医疗体验,开启医学领域技术创新的新篇章。然而,当前医学领域的基础模型的构建往往面临着三个方面的挑战:缺乏用于训练的多模态数据集:由于医学本身的特殊性,医疗任务通常需要处理多模态数据,包括文本信息(电子健康记录,医学报告)、1D 信号(心电图)、2D 影像(超声、X 射线)、3D 影像(CT 或 MRI 扫描)、基因组学等。为了支持医学通用基础模型的训练,大规模多模态数据集的构建十分迫切。缺乏通用的架构设计:在临床医疗诊断中,常常需要综合考虑多个检查结果来做出全面判断,然而,以往的医疗影像分析工作通常只专注于单一模态和单一任务,需要为每个任务设计不同的架构,难以适应临床综合诊断的需求。
医学领域的基础模型需要一个通用的架构,能够有效融合不同模态的信息,从而应对广泛的临床任务。缺乏有效的基准来评估模型:对模型的临床知识进行基准测试主要依赖于多种任务的数据集,而这些数据集的测试案例数量有限。目前医疗领域尚未建立一个大规模、复杂的基准,可以用于全面衡量医学基础模型在中医疗任务上的性能。考虑到上述挑战,研究团队聚焦于构建放射学领域的医学通用基础模型。放射学领域的图像模态种类丰富,影像与报告配对数据也相对较多,且放射学在临床场景中的应用也十分广泛,例如疾病诊断、治疗规划和患者进展监测等等。具体来说,该论文做出了如下技术贡献:数据上:提供了全新的目前世界上最大规模的医疗多模态数据集 MedMD&RadMD,是首个包含 3D 数据的大规模医疗多模态数据集,含 15.5M 2D 图像和 180k 的 3D 医疗影像。模型上:开源了 14B 多模态基础模型 RadFM,支持 2D/3D、图像 / 文本混合输入。测试上:定义了医疗基础模型五大基本任务 —— 模态识别、疾病诊断、医疗问答、报告生成和归因分析,并提供了一个全面的基准——RadBench。
临床价值本文提出的基础模型 RadFM 具有巨大的临床应用意义:支持三维数据:在实际临床环境中,CT 和 MRI 被广泛使用,大多数疾病的诊断在很大程度上依赖于它们。RadFM 的模型设计能够处理真实的临床成像数据。多图像输入:合诊断通常需要输入来自各种模态的多影像作为输入,有时甚至需要历史放射图像,因此支持多图像输入 RadFM 能够很好的满足此类临床需求。交错数据格式:在临床实践中,图像分析通常需要了解患者的病史或背景。交错数据格式允许用户自由输入额外的图像背景信息,确保模型能结合多源信息完成复杂的临床决策任务。
与现有的所有医学基础模型相比,RadFM 是第一个同时满足上述三点要求的模型,对医疗基础模型投入实际临床应用具有巨大推动作用。接下来将从数据、模型、测试三个角度具体介绍原文细节:多模态数据 MedMD&RadMD研究团队构建了一个当前最大规模的医疗多模态数据集 MedMD,是目前首个包含 3D 数据的大规模医疗多模态数据集,包含 15.5M 2D 图像和 180k 的 3D 医疗影像,也并附带文本描述,例如放射学报告、视觉语言指令或相对应的疾病诊断标签。MedMD 涵盖了人体各种放射学模态和解剖区域,横跨 17 个医疗系统,如乳腺、心脏、中枢神经系统、胸部、胃肠道、妇科、血液、头颈部、肝胆、肌肉骨骼、产科、肿瘤、儿科、脊柱、创伤、泌尿和血管,包含超过 5000 种疾病,如下图 1、2、3 所示。此外,研究团队还基于 MedMD, 给出了一个放射学多模态数据集 RadMD。
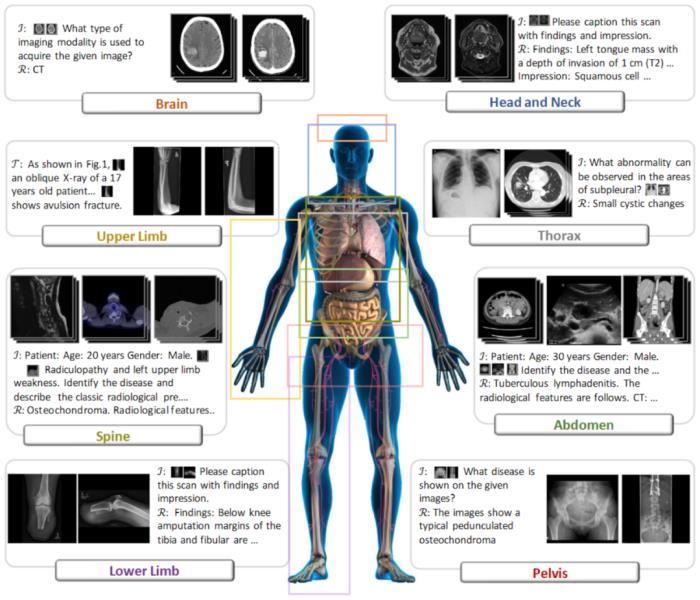
图 2: MedMD 各部分数据构成展示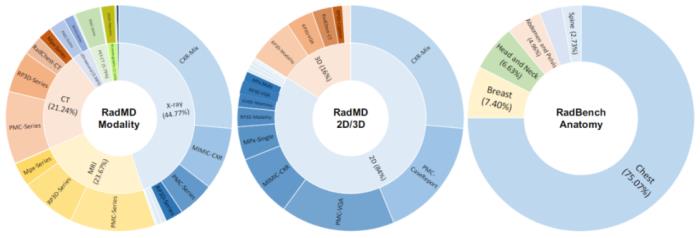
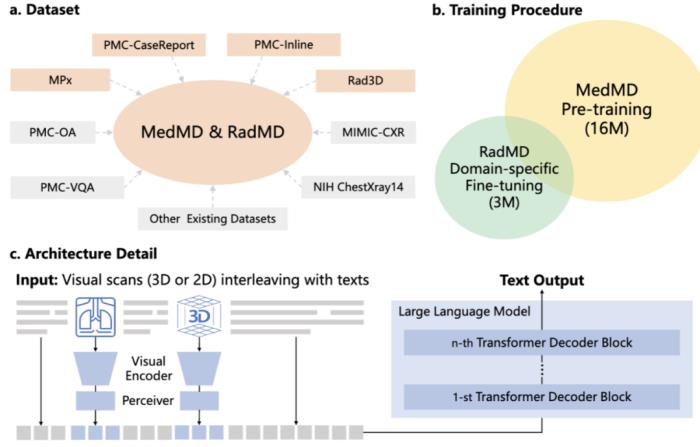
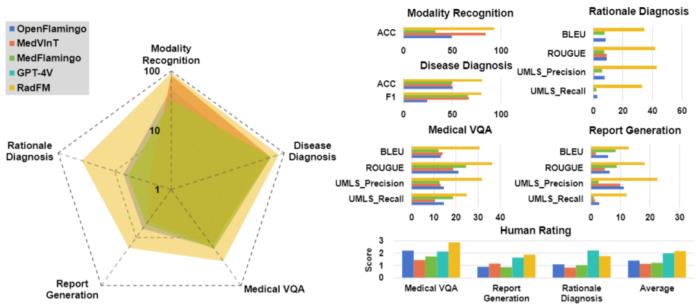
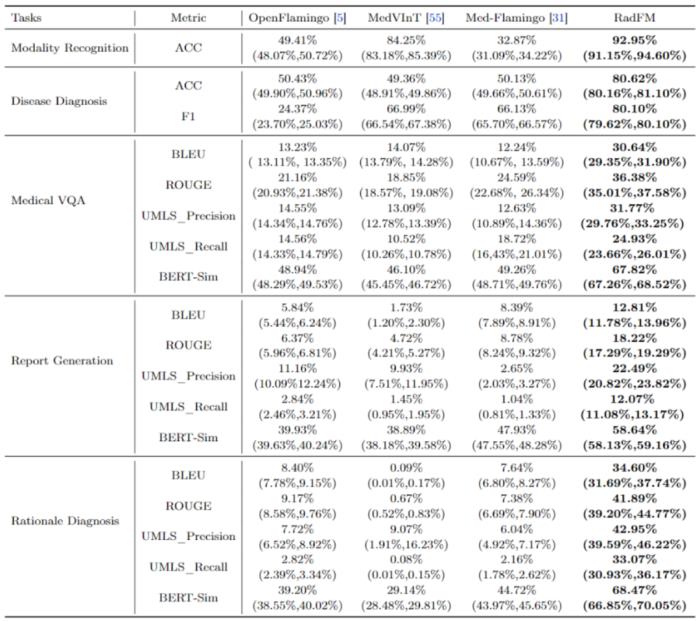
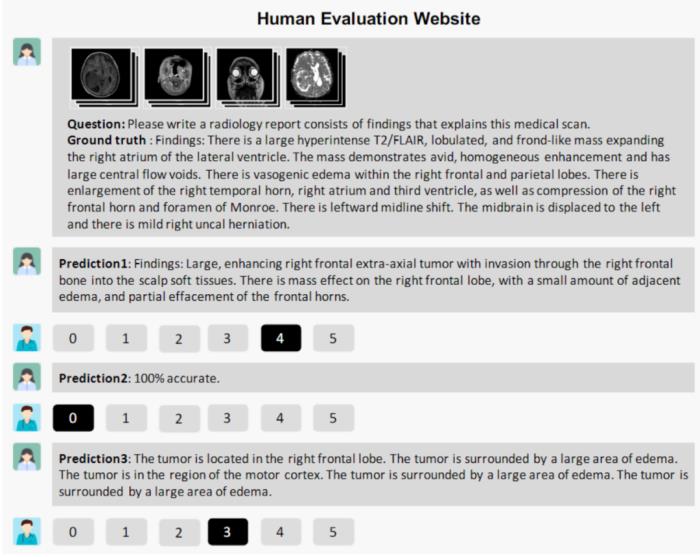

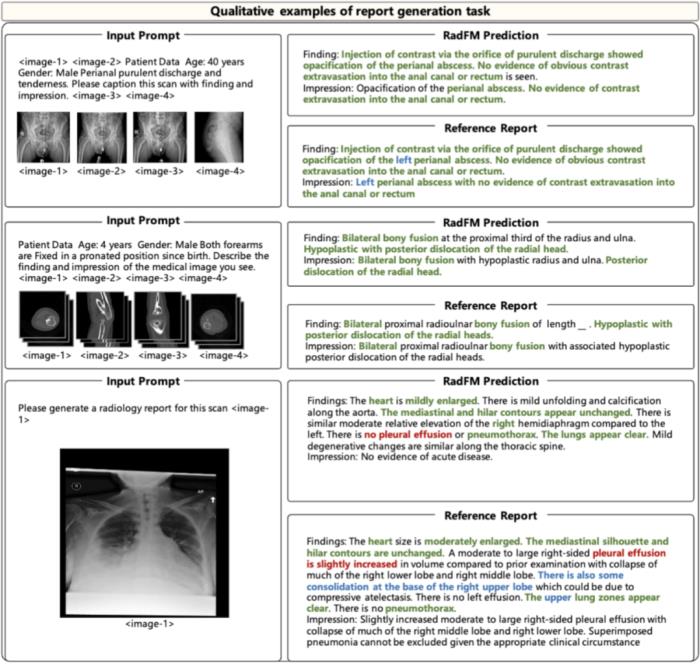

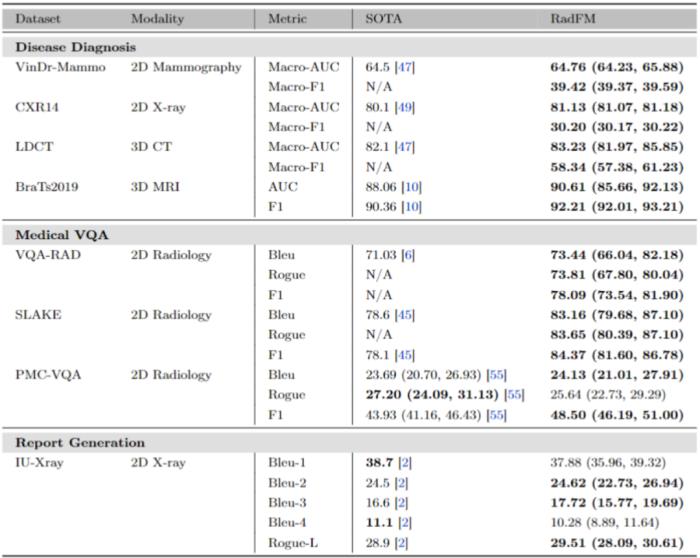

图 12:RadFM 在 PadChest 上对于未见类直接诊断的结果,其他多模态基础模型都只能取得随机的预测结果(0.5 ACC)局限性当前医学基础模型的发展尽管取得了显著进展,却仍存在多方面的局限性,本文作者提出了如下几点方向:模型绝对性能。虽然 RadFM 大幅超越了旧有基础模型,但多模态基础模型在零样本情况下的文本生成质量仍未能满足临床医生的期望水平。3D 数据缺乏。比较于 2D 数据易于收集,在真实临床中广泛使用的 3D 数据在目前医学数据库中仍旧只是少数。评测指标模糊。目前存在一个缺乏令人信服的医学文本质量比对评测指标的问题。传统的翻译指标在医疗场景下几乎失去了意义。例如,对于「病人有肺炎」和「病人无肺炎」两句话,在传统指标下可能获得极高的分数,但这种差异在医疗场景中是不可接受的。相反,「在肺部见肺炎影像特征」与「病人有肺炎」这两句信息几乎一致的话语,在现有指标下反而可能呈现较低的分数。因此,急需建立更符合医学实际需求的评测标准。
总结在当前的医疗领域,已经陆续涌现了一些多模态的基础模型,例如微软的 LLaVA-Med 和谷歌的 Med-PaLM M,包括最新的 Med Flamingo。然而,这些模型都还是受限于 2D 的图像输入,且其中只有最新的 Med Flamingo 可以支持交错的图文输入。在医疗领域中,常见的诊疗影像往往是 3D 的图像,同时,诊疗任务通常需要综合多张图像来作出准确判断。为了解决上述问题,研究团队决定将重点放在放射影像领域,提出模型 RadFM,允许同时处理 2D 和 3D 多模态的医疗数据,例如 CT、MRI 等。而且,该模型能够综合处理多张相关影像,提供更全面和准确的信息,有望在诊断和治疗等方面取得更好的效果。同时,针对模型的评估,研究团队综合了多个挑战性的任务提出了一个新的 benchmark 以及更科学的医疗任务评测指标,以此为参考,不断优化数据与模型,欢迎大家持续关注。完整论文目录:

相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。









