新火种
2023-11-29
新火种
2023-11-29 


BAAI、北大&港中文团队提出SegVol:通用且可交互的医学体素分割模型
编辑 | ScienceAI
上周,北京智源人工智能研究院(BAAI)、北京大学和香港中文大学的研究团队开源了 SegVol 医学通用分割模型。
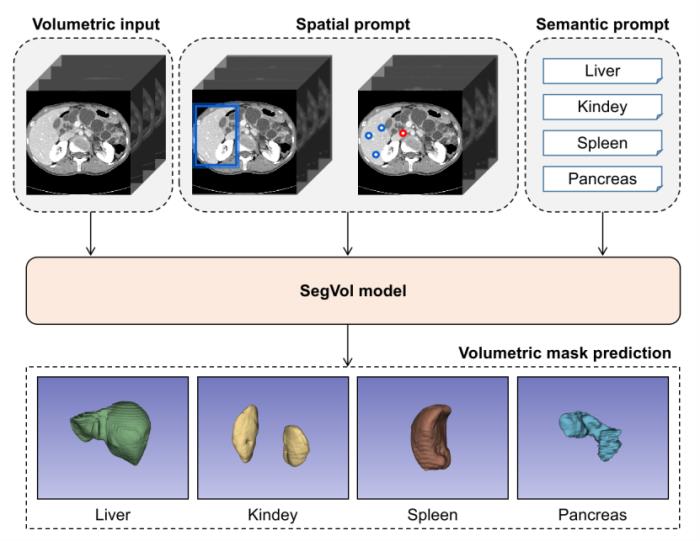
与过去一些很棒的 Medical SAM 工作不同,SegVol 是第一个能够同时支持 box,point 和 text prompt 进行任意尺寸原分辨率的 3D 体素分割模型。作为一个便捷的通用分割工具,研究人员将 SegVol 代码和模型开源到 GitHub:BAAI-DCAI/SegVol,欢迎大家使用。目前开源的模型权重文件包括(1)使用 96k CTs 预训练 2,000 epochs 的 ViT模型,(2)在预训练基础上,使用 6k Masked CTs 在 A100 上训练 30×24×8 个 GPU 小时得到的 SegVol。最新进展请关注 GitHub 仓库的更新,如果有疑惑或建议可以写评论、开 issue 或私信,欢迎大家讨论 。该研究以《SegVol: Universal and Interactive Volumetric Medical Image Segmentation》为题,发布在预印平台 arXiv 上。

摘要
精确的医学图像分割为临床研究提供了富有意义的结构信息。尽管深度学习在医学图像分割方面已经取得了显著的进展,但仍然缺乏一种能够通用分割各种解剖类别且易于用户交互的基础分割模型。
本文提出一种通用的交互式医学体素分割模型——SegVol。通过在 90k 无标注 CTs 和 6k 分割 CTs 数据上进行训练,该基础模型支持 point, box 和 text prompt,能够对 200 多个解剖类别进行分割。大量的实验证明,SegVol 在多个 benchmark 中表现出色。特别在三个具有挑战性的病变数据集上,SegVol方法比 nnU-Net 的 Dice 得分高 20% 左右。SegVol 的代码和权重已经在BAAI-DCAI/SegVol上公开。
核心贡献
1.在 96k CTs 上对模型进行预训练,并使用伪标签解耦数据集和分割类别之间的虚假关联。
2.通过将语言模型集成到分割模型中,并在 25 个数据集的 200 多个解剖类别上进行训练,从而实现文本提示分割。
3.协同语义提示(text prompt)和空间(point, box prompt)提示,实现高精度分割。
4.设计了一种 zoom-out-zoom-in 机制,显著降低计算成本,同时保持精确分割。
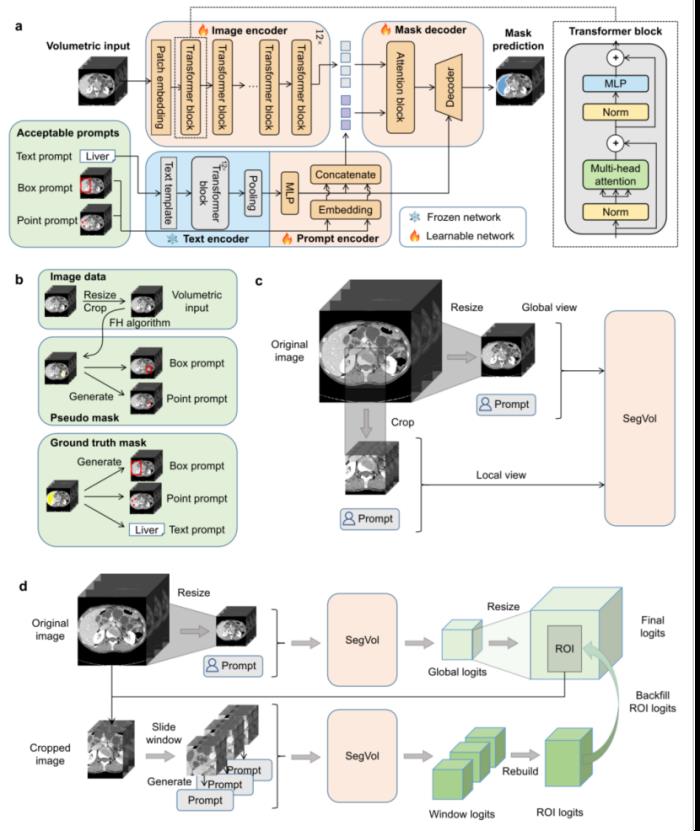
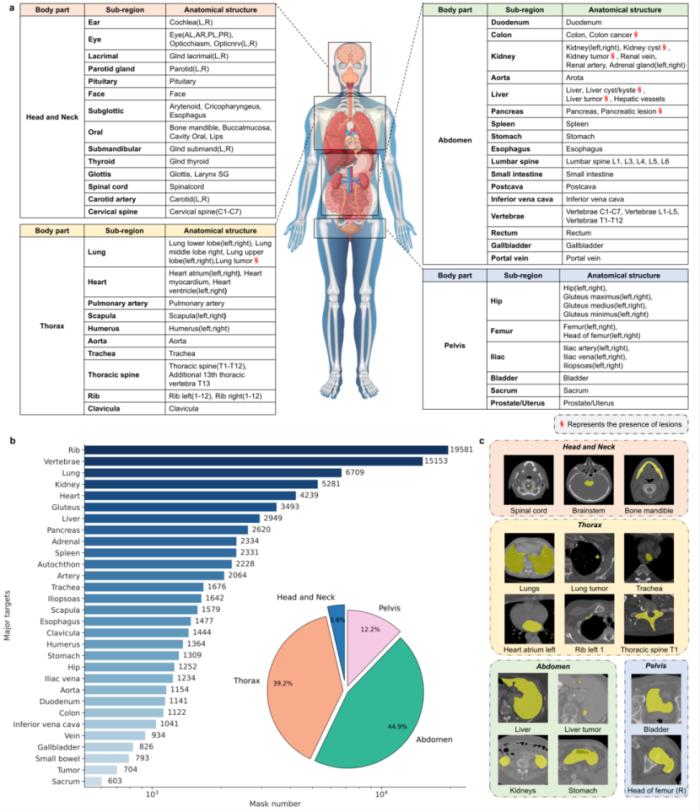
图 1:(a, b)模型结构图。(c, d)zoom-out-zoom-in机制图。
实验
研究人员在多个分割数据集上充分评估了SegVol。
(1)19种重要解剖结构的实验结果
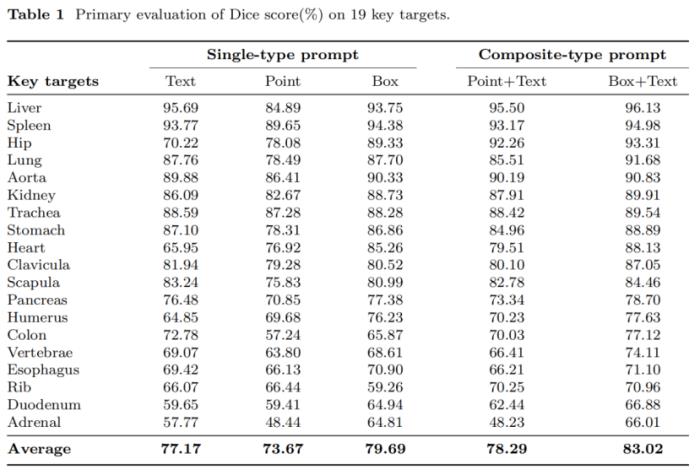
在prompt learning的支持下,SegVol能够支持200多个类别的分割。研究人员选择了19个重要的解剖目标来展示其强大的分割能力,如表1所示。肝脏的Dice得分高达96.13%,而19个主要目标的平均得分为83.02%。其强大的通用分割功能来自于spatial和semantic的复合prompt。一方面,spatial prompt可以让模型理解分割目标的具体空间和位置。由表1可知,对于各种器官的平均分割结果,“box+text” prompt的Dice score比text prompt高5.85%。另一方面,semantic prompt分割目标的语义指代,消除了多种可能的结果。这反映在表1中,“point+text” prompt的平均Dice score比单独使用point prompt高4.62%。spatial prompt和semantic prompt相互支持,最终赋予模型强大的分割能力。
(2)对比实验
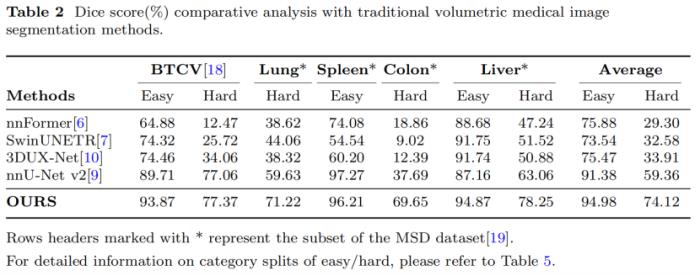
如表2,研究人员将SegVol与五个重要数据集上的四种最先进的方法进行了比较,揭示其巨大的优势。对于体量在数十到数百个病例的医学体素数据集,由于SegVol能够在25个数据集上联合训练,显著优于在单个数据集上训练的传统分割模型。从表2可以看出,SegVol在肝、肾、脾等easy类别上超过了传统模型,平均Dice score达到了94.98%。这主要是由于它从其他数据集的相同或相似类别中学到了更多的知识。更重要的是,所提方法在肝肿瘤、肺肿瘤、肾上腺等hard类别的分割中保持领先地位。SegVol对hard类的平均Dice score比排名第二的nnU-net高14.76%。原因是SegVol可以通过spatial prompt和semantic prompt获得先验信息,从而增强对hard样本的理解,显著改善了分割结果。
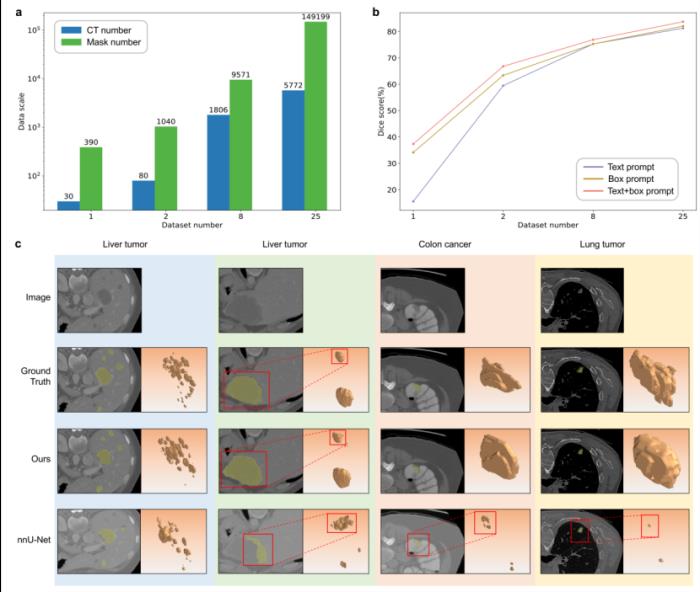
(3)病灶分割能力

研究人员使用nnU-net作为基线模型,它在传统的医学体素分割模型中表现出最强的分割能力。如表3所示,SegVol分割这些具有挑战性的病变的能力明显优于nnU-net。在这三个病变数据集中,SegVol的Dice score超过nnU-net 19.58%,这代表在复杂体素病灶分割方面SegVol的重大进步。图3c给出了一系列示例,展示了nnUnet和SegVol方法的病变分割性能。这些例子包括肝肿瘤、结肠癌和肺肿瘤。可视化结果显示,与nnU-net产生的结果相比,SegVol重建的这些病变解剖结构更接近于Ground Truth。
(4)消融实验
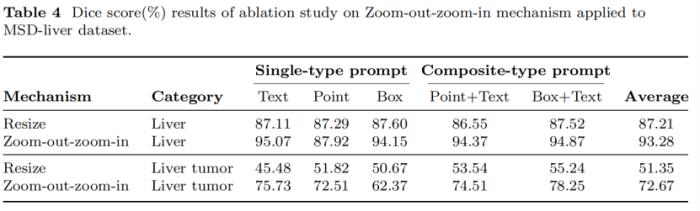
Zoom-out-zoom-in机制:研究人员在MSD-Liver数据集上进行了消融研究,以评估Zoom-out-zoom-in机制的贡献。MSD-Liver数据集包括肝脏和肝肿瘤两个类别,允许研究Zoomout-zoom-in机制对“MegaStructures”和“MicroStructures”目标分割效果的影响。如表4所示,将Zoom-out-zoom-in机制应用于SegVol模型使肝脏类别的Dice score提高了6.07%。这种提升在肝肿瘤类别上更为明显,Zoom-out-zoom-in机制将SegVol的肝肿瘤Dice score提高了21.32%。有趣的是,Zoom-out-zoom-in机制对point prompt分割肝脏结果的改善十分微小。这可能归因于global一级的point prompt相对稀疏,当zoom in到local区域时,其稀疏性变得更加明显,从而限制了该机制的潜力。
Dataset Scale:数据规模是基础模型构建的关键因素之一。研究人员进行了消融研究,以研究Image和Mask的数量对SegVol性能的影响。研究人员将包含13个重要器官的BTCV数据集作为测试锚点,分别对1、2和8个数据集上训练了500个epoch的模型,以及在25个数据集上训练的最终模型进行评估。详细的结果如图3 a和b所示。作为轻量级模型,当只使用一个数据集时,SegVol的性能不是最优的。然而,随着数据量的增加,SegVol的Dice score显著增加,特别是在使用text prompt进行分割的情况下。因为text prompt严重依赖带有语义信息的ground truth mask的数量。
总结
研究人员提出了SegVol:一个交互式的通用医学体素分割的基础模型。该模型是使用90k无标注数据和25个开源分割数据集训练和评估的。与最强大的传统体素分割方法nnU-net(自动为每个数据集配置参数)不同,SegVol的目的是将各种医学体素分割任务统一到一个单一的架构中。SegVol作为一个通用的分割工具能够对超过200个解剖目标产生准确的分割响应。
此外,与传统方法相比,SegVol具有最先进或接近最先进的体素分割性能,特别是对于病灶目标。尽管具有通用性和精确性,但与其他体素分割方法相比,SegVol保持了轻量级架构。SegVol作为一个开源的基础模型,将很容易适用于广泛的医学图像表征和分析领域,可以很容易地被研究人员和从业人员集成和利用。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。