


智谱AI大模型GLM-4在中文原生金融大模型测评中获A级评价
4月25日获悉,SuperCLUE-Fin(SC-Fin)中文原生金融大模型测评基准正式发布。智谱AI自主研发的新一代基座大模型GLM-4,成为国内首批获得A级评价的模型。
4月25日获悉,SuperCLUE-Fin(SC-Fin)中文原生金融大模型测评基准正式发布。智谱AI自主研发的新一代基座大模型GLM-4,成为国内首批获得A级评价的模型。

一、背景利用业内数据构建知识图谱是很多客户正在面临的问题,其中中文命名实体识别(Named Entity Recognition,简称NER)是构建知识图谱的一个重要环节。我们在与客户的交流中发现,现有的NER工具(比如Jiagu)对于特定领域的中文命名实体识别效果难以满足业务需求,而且这些工具很难
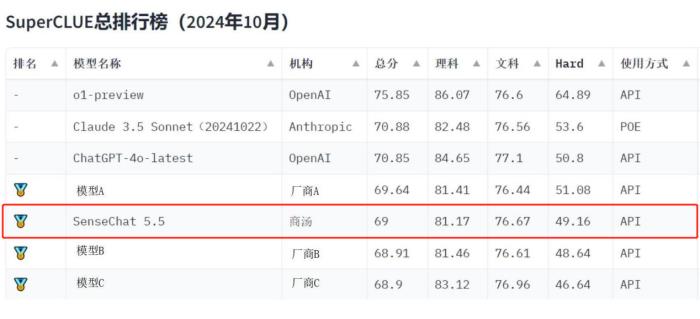
模型表现好,金牌少不了。刚刚,中文大模型测评基准SuperCLUE发布《中文大模型基准测评2024年10月报告》:商汤日日新·商量大模型(SenseChat5.5)凭借出色的能力表现,总得分位列国内大模型第一梯队,获得金牌。本次SuperCLUE10月报告覆盖23个国内模型,聚焦语言大模型的通用能力

当地时间12月6日,谷歌公司宣布推出其规模最大、功能最强大的新大型语言模型——Gemini。最新的演示里,Gemini能听能说能看,还能教人类说中文。

深度学习“只要你有创作想法,‘逍遥大模型’就能帮你写出万字的小说,让更多普通人的生活有了被看见的机会。”10月13日,中文在线集团股份有限公司(中文在线,300364)董事长童之磊在接受澎湃新闻等媒体采访时作出上述表述,当天中文在线发布万字创作大模型“中文逍遥大模型”。据介绍,这款中文逍遥大模型可以

8月10日消息,AI大模型成为今年的热点,OpenAI的ChatGPT一马当先,微软、谷歌、Meta紧随其后,国内科技巨头也迅速跟进,现在国内据说已经有上百款大模型问世了。这么多大模型中,实力到底如何?日前清华大学新闻与传播学院发布了《大语言模型综合性能评估报告》,将国内外的大模型做了一番对比。该报

o1模型为何在推理时使用中文或其他语言来思考尚不得而知,但有专家猜测,原因可能是模型在训练时使用了中文或其他语言的数据标注,也有可能是模型倾向于自行选择它们认为最能有效实现其目标的语言,或者出现了幻觉。

由APUS与深圳大学大数据系统计算技术国家工程实验室(以下简称“大数据国家工程实验室”)联合研发的伶荔Linly-70B中文大模型正式对外开源,并在GitHub上首发。这是APUS大模型3.0的首个开源大模型,也是国内学术界首个700亿参数规模的开源大模型。
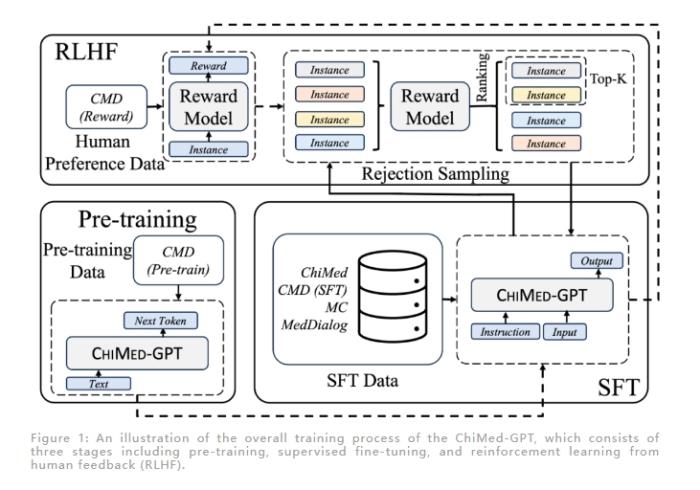
站长之家11月20日 消息:中科大和 IDEA 研究院封神榜团队合作开发了一款名为 ChiMed-GPT 的中文医疗领域大语言模型(LLM)。该模型基于封神榜团队的 Ziya2-13B 模型构建,拥有130亿个参数,并通过全方位的预训练、监督微调和人类反馈强化学习来满足医疗文本处理的需求。ChiMe

机器之心专栏机器之心编辑部香港中文大学(深圳)和深圳市大数据研究院所在的王本友教授团队训练并开源了一个新的医疗大模型 ——HuatuoGPT(华佗GPT),以使语言模型具备像医生一样的诊断能力和提供有用信息的能力。基于医生回复和 ChatGPT 回复,让语言模型成为医生提供丰富且准确的问诊。在医疗领










