

 新火种
2023-11-28
新火种
2023-11-28 

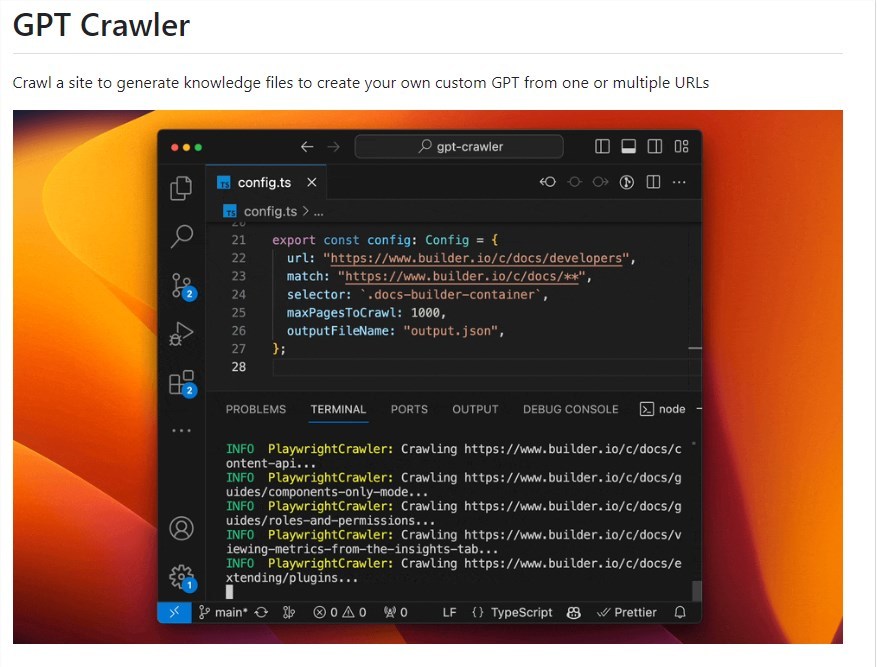

gptcrawler:从URL爬取网站生成结构化知识,创建定制GPT
站长之家11月21日 消息:gpt crawler是一款强大的工具,能够将网站内容全面地爬取下来,并将其转换成结构化知识,为GPTs的学习提供了有力支持。
这个工具的应用场景广泛,比如,如果你想打造一个数字人分身,可以先将自己在社交媒体或个人博客上的内容抓取下来,然后提交给ChatGPT作为储备知识。这种方式不仅能够保存个人在网络上的言论和观点,还可以为ChatGPT提供更多的学习材料,使其更好地理解和模拟用户的语言风格和思维方式。
核心功能:
灵活配置爬虫: 用户可以通过编辑config.ts文件中的URL、选择器等属性,灵活配置爬虫以适应不同的网站结构和需求。
定制化知识文件生成: gpt-crawler通过爬取指定网站的内容,生成包含知识数据的文件(output.json),为用户提供定制GPT所需的基础知识。
轻松上传到OpenAI: 生成的知识文件可以方便地上传至OpenAI,支持用户在UI界面或通过API访问生成的知识,用于创建自定义GPT或助手。
支持Docker容器化执行: 通过容器化执行,用户可以获得output.json,使整个过程更加灵活和可扩展。
贡献和改进: 项目鼓励用户参与贡献,通过提出Pull Request等方式改进工具,使其更加强大和适应更多场景。
据了解,gpt crawler背后采用了先进的技术框架crawlee。Crawlee不仅是一个高效的网络爬虫工具,还是一款强大的浏览器自动化工具。在实现上,它提供了多项关键功能,包括DOM解析能力、无头浏览器模式、异常状态码处理、队列和存储等。这些功能的综合运用使得爬虫更加灵活和强大。此外,Crawlee还提供了大量的配置项,用户可以根据自己的需求进行灵活设置,从而更好地适应不同的爬取任务。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章










