

 新火种
2023-11-22
新火种
2023-11-22 


使用生成神经网络进行结构预测和材料设计

稳定晶体结构的预测是设计具有所需性能的固态晶体材料的重要组成部分。结构特征表示和生成神经网络的最新进展有望有效创建新的稳定结构以用于逆向设计和搜索具有定制功能的材料。
2023 年 7 月 3 日阿拉巴马大学伯明翰分校(University of Alabama at Birmingham)的研究人员在《Nature Computational Science》发表评论《Structure prediction and materials design with generative neural networks》,探讨了这一问题。

只要指定其底层晶体结构,就可以使用第一原理量子力学计算对固态晶体材料进行精确建模。然而,对于未知结构的材料,预测其特性需要额外的晶体结构预测(CSP)步骤。CSP 旨在通过在某些热力学压力和温度条件下定位吉布斯自由能最小值,在仅给定化学式(以及晶胞中的原子数量)的情况下发现稳定和亚稳态结构。完成这项任务需要精确计算势能面和强大的优化技术。进化算法和粒子群优化等有效的优化方法导致了各种新材料的发现。
典型的 CSP 任务会扫描数千个结构并执行相应的能量计算。它的计算成本很高,特别是对于具有三元或四元(或更高阶)成分的材料。因此,大规模材料发现仍然具有挑战性。最近,生成模型为应对这些挑战提供了有希望的新机会,因为一旦经过训练,它们可以比传统 CSP 技术更快地生成新结构。然而,开发 CSP 生成模型非常重要,因为它需要可逆表示将三维 (3D) 晶体映射到特征空间,以及相应的反向映射。它还需要一个在统计上代表感兴趣系统的目标数据库。尽管存在这些重要问题,但最近的几项研究证明了使用生成神经网络有效且准确地预测新的稳定晶体结构的可行性。
生成模型
机器学习模型通常可以分为判别模型和生成模型。判别模型专注于预测数据标签并在特征空间中绘制边界。另一方面,生成模型侧重于解释数据是如何生成的,并尝试对数据在整个空间中的放置方式进行建模。因此,判别模型虽然可以实现晶体结构到材料属性的直接正向映射,但无法像生成模型那样实现逆向设计。
本质上,生成模型学习数据本身的分布,然后从学习的分布中采样新的数据实例,这使得能够探索更多样化的晶体结构输出。在逆向设计领域,两种类型的生成模型广泛用于晶体材料:变分自动编码器(VAE)和生成对抗网络(GAN)。生成模型的一个关键特征是它们能够将学习的潜在特征空间中的任何数据点映射回材料空间中相应的晶体结构。在高通量计算中,生成模型可以提供比基于替换的枚举更好的组成和结构多样性,并且比传统的 CSP 技术提供更好的结构生成效率。
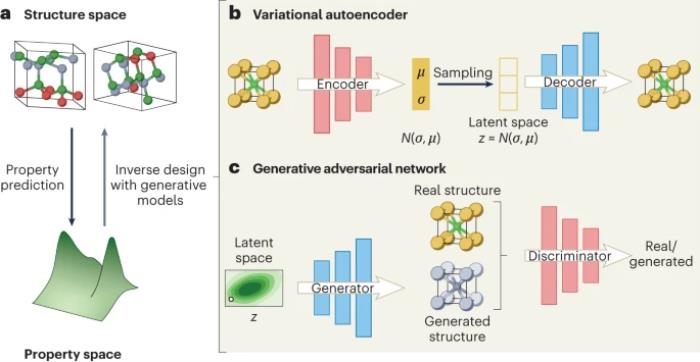
VAE 由编码器和解码器组成,经过训练以最小化解码数据和输入数据之间的重构误差。然而,编码器不是将输入编码为潜在空间中的单个点,而是将输入视为潜在空间上的分布(的参数)。然后可以对来自潜在空间的新数据点 z 进行采样和解码。编码分布通常选择为正态 N(μ, σ),平均值为 μ,标准差为 σ。代表性的 VAE 结构预测器包括 iMatGen、傅里叶变换晶体属性 (FTCP) 框架和约束晶体深度卷积生成对抗网络 (CCDCGAN)。
具体来说,FTCP 添加了一个目标学习分支来将潜在点映射到目标属性(带有额外的属性映射损失)。CCDCGAN 使用 VAE 来学习从潜在 2D 晶体表示到晶体结构的反向映射,然后使用该表示来训练 GAN 以生成新的晶体结构。VAE 相对容易训练,并且提供了比其他生成模型更多样化的结构,可以更好地覆盖分布。然而,VAE 存在输出有效性较低的潜在缺点(即某些结果可能无效)。在计算机视觉任务中,VAE 模型可能会产生不切实际、模糊的样本,部分原因是嵌入特征空间遵循高斯分布的假设。
GAN,利用博弈论中极小极大博弈的思想,使用两个网络:生成器 G,将潜在空间中的随机变量 z 转换为生成的样本 G(z);鉴别器 D,用于区分样本是真实的还是生成的。GAN 经过训练,使得 G 最大化 D 将生成样本错误分类为真实样本的概率,并且 D 尽可能区分真实样本和生成样本。这使得 G 能够了解真实数据的分布。
此外,条件 GAN 允许根据所需条件扩展潜在变量 z,例如用户所需的成分,如成分条件晶体 GAN 中那样。通常会添加另一个网络分支来预测 G(z) 的属性,并将该预测包含在损失中,以产生具有所需属性的晶体结构,如 CCDCGAN 中那样。这个想法类似于 FTCP 框架的目标学习分支。CrystalGAN 进一步利用跨域 GAN 从更简单的二元 Pd-H 和 Ni-H 结构开始生成复杂的三元钯-氢-镍结构。在计算机视觉任务中,GAN 通常会生成更逼真的图像。然而,与 VAE 相比,GAN 更难训练,因为它可能会出现不收敛、模式崩溃和梯度减小等问题。因此,总的来说,平衡 GAN 中的生成器和判别器对于防止过度拟合至关重要。
特征表示
通常,材料数据库中的结构以晶体信息文件 (CIF) 格式存储,该格式通常用作特征表示的输入。在连续潜在特征空间中表示离散晶体结构是使用生成模型进行结构预测的第一个重要步骤。目前主要有两种方法:连续3D体素表示,其中编码器和解码器分别准备2D晶体图并重建3D体素图像,以及矩阵表示,其中晶格参数、原子占据坐标和元素性质等晶体结构特征被分成不同的矩阵行和列。
例如,在 iMatGen 中,首先训练编码器将 3D 体素图像(晶格参数和原子位置)压缩为单个图像,然后解码器根据该图像重建晶体结构。CCDCGAN 考虑使用晶格自动编码器进行 3D 体素表示,它首先通过涂抹将原子位置转换到体素网格上;体素网格进一步转换为一维向量,然后编码为二维晶体图。在成分条件晶体 GAN 中,通过构建晶胞参数和原子分数坐标的 2D 矩阵表示,利用点云表示来显著降低内存需求。FTCP 框架通过考虑实空间和倒易空间特征以及傅立叶变换元素属性矩阵和米勒指数(全部采用二维矩阵形式)重新审视点云表示。在上述表示中,从潜在空间回到材料空间的可逆映射是必要的。
除了潜在空间和材料空间之间的可逆性之外,结构特征表示原则上还需要不变性。由于底层的晶体对称群,经历平移、旋转或晶轴排列(例如)的表示应该是不变的,这意味着它仍然表示相同的潜在空间数据点。然而,在实践中,文献中仍然缺乏完全可逆且不变的方案。应该探索其他晶体特征表示想法,例如 E(3)-等变图神经网络,它可以在等变变换下保留已知的系统属性。特征表示的另一个潜在问题涉及反向映射期间保真度的损失。换句话说,当潜在空间点反向映射回材料空间时,所得的晶体结构与原始晶体结构不同。给定的输入结构可以在多大程度上完全重建,以及重建中保真度损失引起的误差有多大,需要更仔细地确定,例如通过不确定性量化。
训练数据
当前的生成模型主要采用实验数据库(例如无机晶体结构数据库)和计算数据库(例如材料项目)。为了确保足够的结构和元素多样性,通常执行已知晶体结构中的元素替换或数据增强技术的额外高通量计算,以实现统计上具有代表性的数据分布。
例如,iMatGen 中的训练数据是通过从材料项目中获取 25 种独特的钒-氧成分,并将这些成分替换为同样在材料项目中的 10,981 个二元金属结构而创建的。这导致材料项目中 31 个现有 VxOy 结构中的 26 个被重新发现,以及 40 个先前未识别的新结构,其凸包上方每个原子的能量约为 80 meV。
CCDCGAN 研究了 Bi-Se 系统,而材料项目数据库仅包含 17 种已知的 Bi-Se 材料。训练数据的生成方式类似,其中 10,981 个原型结构被 Bi-Se 取代,将每个晶胞的最大原子数限制为 20,将最大晶格常数限制为 10 Å;在随后的第一性原理计算中收敛了 9,810 个结构。成分调节晶体 GAN 研究了 Mg-Mn-O 体系。训练数据也是通过材料项目中三元化合物的元素替换生成的,初始数据集包含 1,240 个结构和 112 种成分。通过添加旋转和平移的晶胞以及超晶胞结构,进一步增强了训练数据。这种数据增强为每种成分产生了 1,000 个结构,从而产生了 112,000 个 Mg-Mn-O 结构。训练结束后,GAN 模型被用来创建 9,300 个独特的结构进行高通量计算,其中发现了 23 个新的 Mg-Mn-O 晶体。
这些研究表明,当前的生成模型能够生成真实材料的结构,也能够生成新的稳定材料的结构。然而,对于给定的材料系统,每个生成模型都需要通过数据增强进行单独训练,因为现有数据库仍然太小,无法开发适用于所有材料的全面且通用的生成模型。
当然,训练数据的质量在确定生成神经网络的性能方面起着至关重要的作用。需要足够的数据(即10^5至10^6)和高结构多样性(即10^3至10^4),否则模型在训练过程中可能会出现偏差。除了开放材料数据库中已知结构的元素替换之外,数据增强(例如,利用晶胞的不变性)和主动迁移学习也可能有所帮助。传统的 CSP 优化技术还可以通过搜索稳定和亚稳态结构来训练生成模型来帮助缓解问题。从生成模型生成的结果结构又可以作为 CSP 搜索中的种子结构提供。最后,实现超越地层能的性质的逆设计需要相应的数据库(例如,机械、电子和热传输性质)。例如,FTCP 框架尝试以带隙和热电功率因数等特性为目标。高通量密度泛函理论或力场分子动力学计算或机器学习模拟可以缓解相关属性数据库的缺乏,例如晶体图卷积神经网络(CGCNN),一旦了解了底层晶体结构,它就可以提供快速的属性预测。
结论和观点
由于现有的材料特征表示主要基于图像或编码的潜在特征向量,因此 ConvNet 或多层感知器主导了正在研究的神经网络模型。尽管 CGCNN 等架构已经出现,用于从材料到其潜在特征的正向映射以进行属性预测,但在逆向设计中将它们转换回 3D 晶体结构的显式公式仍然是一个悬而未决的问题。尽管开发用于大规模结构预测和材料设计的未来生成模型存在挑战,但一旦经过训练,与传统优化技术相比,这些模型可以将材料发现速度加快几个数量级。理想情况下,生成模型应该能够解决数据数量有限的小问题以及具有许多晶体学自由度的大问题的逆向设计。因此,用更少的训练数据或更广泛的训练组合和结构来展示更多的生成模型是未来研究的重要领域。
与此同时,许多研究已经应用图卷积网络来生成有机分子,其中流动和扩散模型等物理启发模型已与 VAE 和 GAN 一起使用。测试这些模型是否也适用于晶体结构的逆向设计将会很有趣。除了生成模型之外,强化学习(例如蒙特卡罗树搜索)已被用来通过沿着有希望的方向进行引导结构生长(例如一次一个原子)来发现具有所需属性的材料结构。
最后,重要的是要解决机器学习模型是否可以提供对已发现的假设材料在实际应用中的可合成性的衡量。例如,FTCP 通过检查实验无机晶体结构数据库中是否存在生成的结构来解决可合成性问题。需要在这些方面进行更多研究。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章










