

 新火种
2023-11-22
新火种
2023-11-22 


专家学者云集LIC2021颁奖盛典探讨自然语言处理领域发展新动向
8月28日,由中国计算机学会(CCF)和中国中文信息学会(CIPS)共同发起并联合主办的第六届语言与智能高峰论坛召开。会上,2021语言与智能技术竞赛颁奖典礼圆满落幕。

2021语言与智能技术竞赛由中国计算机学会(CCF)和中国中文信息学会(CIPS)联合主办,百度公司、中国计算机学会自然语言处理专委会和中国中文信息学会评测工作委员会承办。本届竞赛设置了机器阅读理解、多技能对话和多形态信息抽取三大任务,与往届竞赛仅关注模型在单一数据上的效果不同,本届竞赛联手“千言”开源数据集项目,对每项任务设置了更加丰富的数据集合和评测维度,重点关注模型的鲁棒性、泛化性和多任务能力等,从多个维度对技术效果进行综合评价。
虽然赛题难度较往年有所提升,但开发者们的参赛热度不减。据统计,来自产学研各界4300余人次、3500支队伍参与了赛事争夺,累计收到有效提交结果1万多次,较去年平均单任务提交数提升22%,竞争非常激烈。
比赛过程中,选手们提出了很多创新思路和方案,三大任务效果相对基线大幅提升20%以上,对话任务甚至达到80%+,有力推动了相关任务的技术进步。在颁奖现场,三个任务的优胜团队也进行了技术方案的分享和交流。
本次竞赛的机器阅读理解任务从细粒度、多维度挑战了机器理解语言的能力,包括词汇理解、短语理解、语义角色理解等五大考察维度。该赛道冠军——来自深圳平安集团金融壹账通的团队,介绍了行为型微调和注意力机制改良的两阶段微调方案。在行为型微调方案中,针对本次赛题的挑战,分别设计了词汇替换、正/负短语理解问题构造、语义角色互换样本构造和负推理样本构造的方法进行数据增强。并将增强的数据分为低质量和高质量两部分,先用低质量数据对模型做自适应的微调,再用高质量数据作为训练集扩充,从而提高模型的鲁棒性。
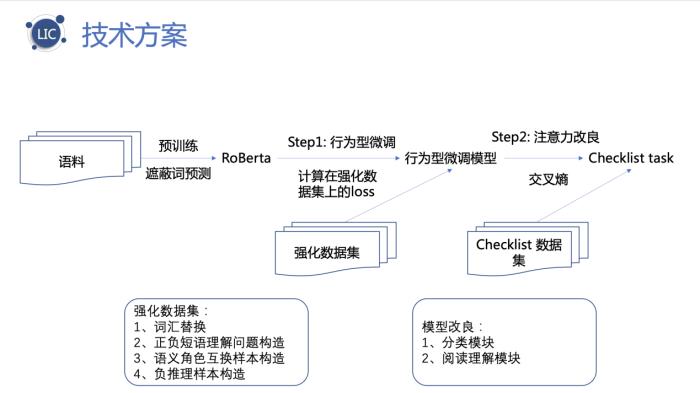
深圳平安集团金融壹账通团队方案分享
多技能对话赛道冠军——来自蚂蚁集团大安全的团队利用了百度开源的对话预训练模型PLATO-2,对多种对话任务进行统一建模,并加入OOV处理、知识筛选、推理优化等优化点,效果大幅提升。同时,该团队也表示,目前业界中文的开源对话数据较少,“千言”数据集的开源开放有助于对话技术的研究发展。
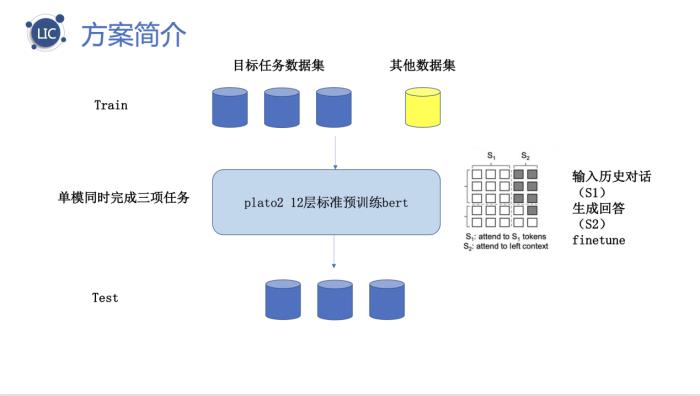
蚂蚁集团大安全团队方案分享
对于此次参赛的研究成果与自身业务的落地结合,多形态信息抽取赛道获奖队伍之一——来自小米公司的团队也给出了肯定的答案。针对本次赛题,该团队针对关系抽取、句子级事件抽取和篇章级事件抽取分别设计了不同的策略。同时他们表示,大规模知识图谱和事件图谱的构建需要使用准确度高的信息抽取算法,构建好的知识图谱可以应用到广告、对话机器人等场景,对于提高广告CTR和对话机器人回答准确率都有一定的价值。

小米公司团队方案分享
颁奖典礼现场,百度自然语言处理部主任研发架构师刘璟做了竞赛的整体报告,对本次比赛进行全面总结。他还提到联合建设“千言”数据集开源项目的宗旨:“我们的目标是构建全面的、面向自然语言理解和生成的开源数据集合,希望能够通过多维度的综合评价,以及覆盖丰富的任务类型,共同推动中文信息处理技术的进步”。作为面向自然语言理解和生成任务的中文开源数据集合,“千言”旨在为研究人员带来一站式的数据集浏览、整理、下载和评测的科研体验。在本次比赛结束后,自然语言处理领域的研究者、开发者可通过“千言”官网(luge.ai)继续下载和使用相关数据集,并参与相应的常规评测,不断打磨和提升相关任务的技术水平,形成创新闭环。
近年来,学术界、产业界对自然语言处理这一领域持续深耕,促进着人工智能学科不断向前发展。自然语言处理技术的应用不仅改变着人类的生活方式,也为实际产业应用的升级提供了更多新的可能。语言与智能竞赛持续“以赛促学”,挖掘和培养更多的AI技术人才、赋能社会百业,为中国AI产业的发展再添动能。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










