新火种
2023-11-17
新火种
2023-11-17 


讲座|包弼德:何谓数字人文?何为数字人文?
2023年10月27日,哈佛大学讲席教授包弼德应邀在上海交通大学人文学院进行了题为“何谓数字人文?何为数字人文?”(What are the Digital Humanities and Why are They Important?)的公开讲座。此次讲座同时也是上海交大人文学院20周年纪念活动之一,由上海交通大学人文学院王宁教授主持。
数字人文是借助计算机和数据科学等方法和手段进行的人文研究,近半个世纪,尤其是近十多年来,随着计算机技术手段的蓬勃发展,数字人文研究方兴未艾。包弼德教授首先介绍了人文与数字人文的定义及差别,并以CBDB(中国历代人物传记数据库)为例介绍了目前数字人文研究的情况,讨论了如何支持数字人文的发展。以下是讲座记录:

讲座现场(摄影:张艺菡)
什么是人文?可以有三层意思,首先,人文是人类创造出来借以达意的媒介,可以是语言文学,也可以是艺术和音乐;第二,人文是我们创造的叙事,通过现在和过去的关系定位现在,通过此处与彼处的关系定位此处,这同时包含时间上和空间上的意义,也就是历史和人文地理;第三,人文是关于我们是如何行动的学说,包括哲学、宗教等等。有人认为,在中国,人文可以对标为国学,国学以儒学为本,但国学这个词带一点意识形态意味。我宁可说人文就是文史哲。论语中有句话叫“述而不作,信而好古”,可是苏轼认为述而不作是不够的,必得有创造,必得有新意,人文研究也是如此,必须述而作,传统和创新都需要。

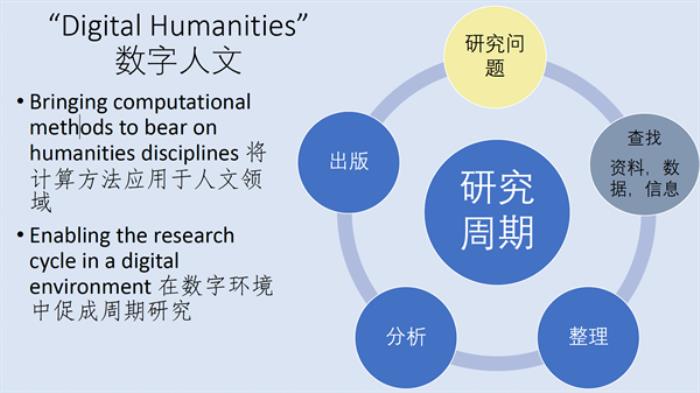
数字人文和传统人文研究的不同,有四个方面:一是数字资源,二是数据(data),三是用计算性方法查找和提取数据,四是用计算性方法分析数据,把数据可视化,来创造新的信息。也可以说,数字人文是在数字环境下促成周期研究,一个研究周期包括找到研究问题、收集数据、查找资料数据信息,整理、分析数据等环节,这些环节都可以运用数字人文方法。
数字资源是数字人文和传统人文的不同点之一。数字人文需要借助大量的电子资源展开研究。可现在的电子资源数据库越来越贵。信息革命的时代,大家有一些愿景,觉得可以借助这个潮流,让原本比较难获得的资源数字化后供给全世界。但不公平的情况仍然存在,资金充裕的大学数字资源多,资金匮乏的大学资源少。
第二个不同点是数据(data),数字人文就是有很多数据的人文。数据是什么?数据(data)是可以被作为单一实体处理并加以编码的一个事实或统计数据。可是data不是information(信息),data是个实体,必须把data整理联合起来,才可以成为信息。举一个例子,这张图是《宋史·吕祖谦传》中的一段话:

这一段话中有很多数据,包括人名、地址、职官、社会关系、亲属关系,通过文本挖掘的技术手段,可以从这一段话中提取出许多数据,并展示给大家。
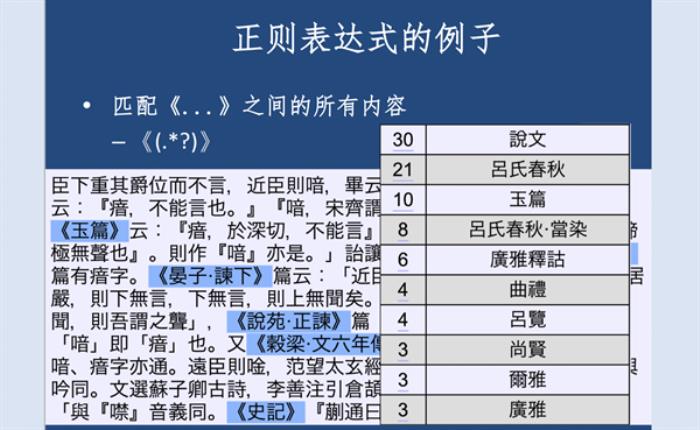
第三个不同是数字人文用计算性方式查找和提取数据。现在有两个比较普遍的方法,一个是专名识别(Named Entity Recognition),比如如果有一个词典包含了所有地名,我们就可以依据这个数据库进行文本挖掘,看某个文本包含了哪些地名;另外一个方法是正则表达式(Regular Expression),正则表达式就是找到文本信息的规律,借助计算机编程进行提取这些信息。举一个简单的例子,比如我们要找到一个文本中的书名,书名往往分布在书名号(《》)之间,这就可以写一个计算机程序,提取所有书名号之间的文本。
也有一些更复杂的正则表达式,比如之前提取《宋人传记资料索引》两万五千条传记中的信息,设计正则表达式花了很久时间,但之后几天之内就把这些信息全都提取了出来,这就需要计算机专业人才的协助。欧洲的魏希德教授利用这一方法主持开发了Marcus平台,可以帮助我们进行一些文本信息(如人名、地名等)的标注。
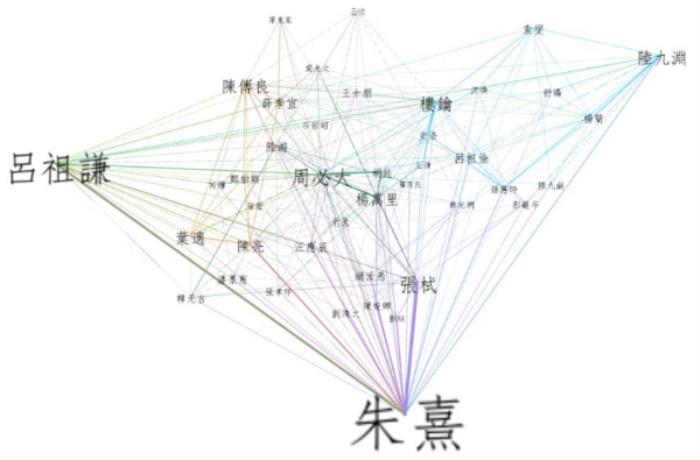
第四是用计算性方式去分析数据,把数据可视化,创造信息。举两个例子,分别是北宋和南宋进士的地理分布和吕祖谦的学术网络。有意思的是,从吕祖谦的学术网络中,我们容易发现朱熹的地位还是要比吕祖谦更重要。
我自己主要研究思想史,尤其是唐宋元明士大夫的思想史。我利用数字人文进行群体传记学的研究。但文学研究者利用数字人文时的关注点往往和历史学家有所不同。历史学家往往对人物有兴趣,而文学研究者对词汇更有兴趣。文本分析的一个重要视角是互文性(intertextuality),即讨论文本之间的引用情况,例如《吕氏春秋·必己》和《庄子·山木》文本的互文情况。借助互文性研究的相关技术,我们可以得到所有先秦文献的“文本重复使用”的情况,如图所示:
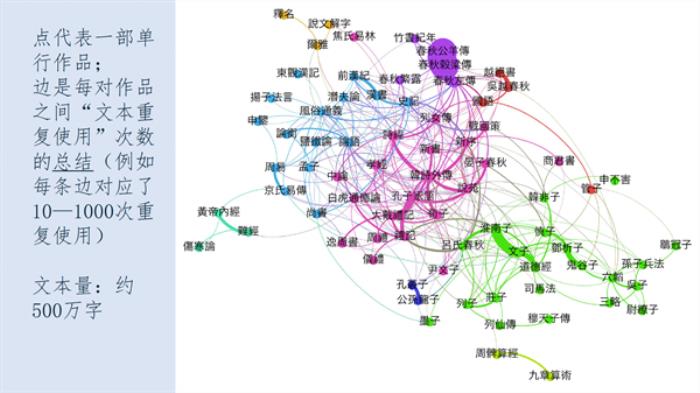
最近自然语言处理工具ChatGPT的广泛运用引发了很多讨论。在大学里,一个很重要的问题就是学生在作业中可不可以使用ChatGPT。我们现在的基本看法是,几乎没有办法阻止学生使用ChatGPT,关键在于我们如何用它更深入地去研究哲学或者文学。我曾做过一个尝试,先用英文问ChatGPT佛学是什么(What is Buddhism)?然后用简体中文问:佛教是什么?再用繁体中文问:佛教是什麼?会得到三个不同的回答。这是因为ChatGPT会学习不同语言的语料库,简体中文、繁体中文和英文的回答不一样,是因为背后的学术传统不同,这很有意思。
今天第二个话题,我要以CBDB为例,介绍目前数字人文研究的情况。CBDB的基本观念很简单,从文本中提取各类人物数据,整理联合起来,创造新的知识。研究者可以使用数据库研究群体传记学,将CBDB应用到统计分析、社会网络分析、空间分析等研究。
CBDB由三个学校机构合作开发,分别是北京大学中国古代史研究中心、台湾“中研院”历史研究所和哈佛大学费正清研究中心。
CBDB是为了群体传记学的研究而创建。1972年历史学者L.Stone对于群体传记学的定义是:“透过对一群人之生平作集体性研究,而对这群历史人物之共同背景特征所作的探讨。其采用的方法为建立一个研究的场域,然后询问一组统一化的问题——关于出生与死亡、婚姻与家庭、社会出身与其继承的经济地位、居住地、教育、个人财富之数量与来源、职业、宗教、公职经验等等。”
这里提到了“个人财富之数量和来源”,如果你们经常看中国的墓志铭和传记资料,就会发现这些传记中很少涉及个人财富的相关信息,但是在欧洲的传记资料里面常常看到。我和欧洲的学者开会,他们认为CBDB数据库缺乏一个非常重要的表:钱,也就是财富。我们听取建议增设了这个表,但目前没有增添一条数据,因为中国的传记资料中很少涉及这个方面。这应该是中欧传记数据的一个不同。
CBDB数据的来源很广泛,例如宋代的传记资料我们从336种来源中提取信息。目前为止,CBDB总计已经收录了53万人物信息,社交网络信息超过18万,亲属关系收录最多,超过53万。除此之外还包括地址、社会区分、入仕、职官等核心实体。
我们把实体放入不同的表中,可以找出不同的表之间的关系。比如,在中国,人有名,有号,有字,有行第,有小名,有小字,所以我们做了别名编码表,这是最简单的表,有17个。但地址编码表的数量就很多,有三万多个;社会关系和亲属关系编码表差不多五百个。把这些编码表和数据表联合起来,就形成了关系型数据库。

在关系型数据库中,如果我们想要知道一个人在一生中经过了什么地点,会先做一个人名表,这是最重要的,没有它就不知道主人公是谁,然后我们将地名表与之对应。但是如何确定一个地名和人物的关系呢?这个地点是他的籍贯吗?或是他的故居吗?或是他的工作地吗?这时我们把地点(places)和关系(relations)的表相对应,就能解决问题。或者说,我们想知道某个时代的所有宰执官员间是否有亲属关系,就需要把人名、任官、亲属关系等表格联系起来考察。
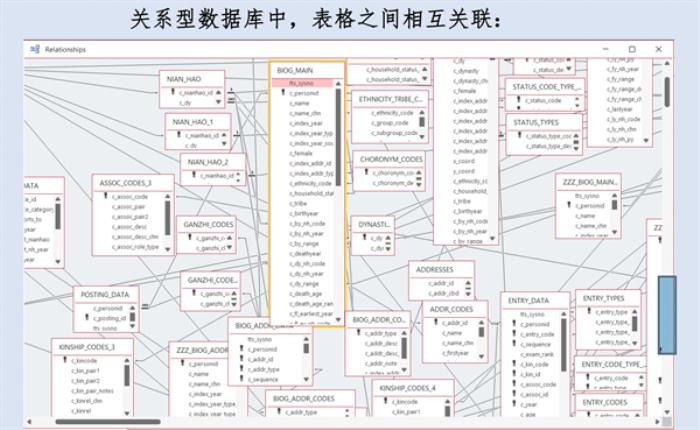
CBDB是关系型数据库,组织不同实体间的联系,这是关系型数据库的主旨。我们从传记资料中提出不同类型的数据,放在不同的实体之内,同时在这些不同实体之间建立了多种形式的联系,通过将不同的实体联系起来,我们可以得到一些新信息,来解决一些问题。
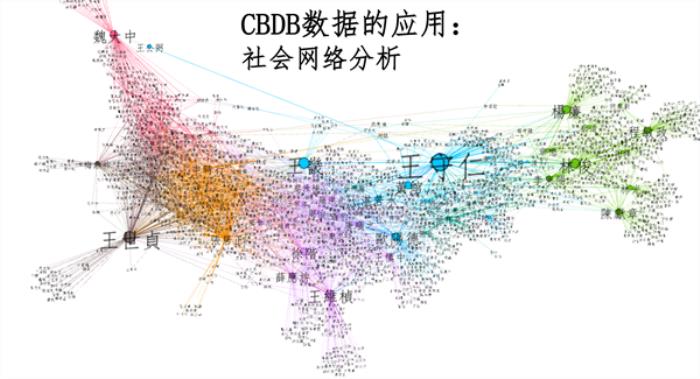
CBDB有很多查询入口,每个查询入口对应不同的输出内容,可以进行循环搜索。在社会关系查询窗体中,CBDB能够找到人物之间的社会关系网络。我们在此基础上设计了一个四值度量法,用于社会关系的亲疏远近。比如我的朋友是第一度,朋友的朋友是第二度,以此类推。如下图,查询王阳明到第三度的社会关系,可以得到这个社会网络图:
或者我们可以用CBDB来做空间分析,例如可以考察亲属关系的地理分布。比如江西吉州的亲属关系分布图,可以发现,北宋时期亲属分布图是全国性的、很分散的,可是到宋末元初就地方化了。这种现象的形成不但在吉州,在金华、绍兴、赣州等各个地方都是这样。CBDB会证明有这样的现象,但不会解释为什么有这样的现象,而这正是学者们,特别是历史学者们该做的——解释事件发生的原因。我的新书《志学斯邑:十二至十七世纪婺州士人之志业》(Localizing Learning: The Literati Enterprise in Wuzhou, 1100-1600)就讨论了这个问题,中文版预计在明年出版。
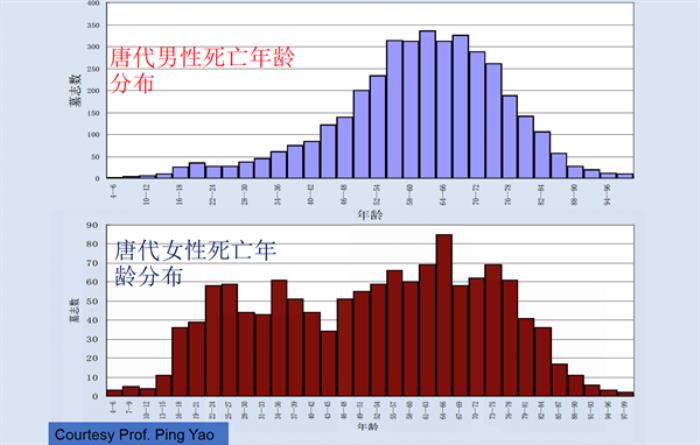
CBDB也可以用来进行统计分析,下图是对唐代男性和女性死亡年龄的数据统计图,可以发现唐代女性在青壮年时期的死亡率明显高于这一时期的男性,这是由于生育风险。
CBDB不是一个传记辞典,尽管在不断修订,但并不要求数据各方面都精确无误。CBDB服务于群体传记学研究,致力于把很多数据联合在一起,形成一个大概的模型。我们也可以提供某一个人传记的各方面数据,然而作为数据库,更重要的是提供范围和数量上更大规模的数据,从而对研究提供帮助。
CBDB一直在发展。我们的内容在不断更新,现在查询到的数据图和明年的可能会有细微的不同,我们在不断增加历史数据,扩大数据库,比如一直在进行的对地方志和清代朱卷的数据挖掘、明代书信项目等,社会人士也可以通过API进行众包输入,扩充和校对数据。我们希望专业的人可以加入,帮助我们完善CBDB数据库。
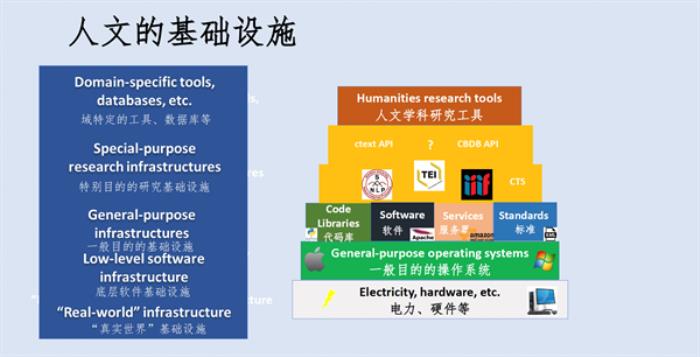
今年三月哈佛大学举办了“业界工具:通往未来”(Tools of the Trade: The Way Forward)的数字人文国际会议,来自中国、日本、美国、加拿大、欧洲各国的学者都介绍了自己的研究成果和数字人文项目,他们的PPT都已在网络公开。2018年,我在一次会议上讨论了网络基础设施建设的问题。什么是数字人文基础设施?最基本的是硬件设施,但也包含了代码库、软件等方面的要求。之所以要做这些基础设施,是因为我们的数据库正在多元化,有很多独立的数据库,彼此之间关联很少。打比方,如果你要查阅一本书,不确定它有没有被数据化,就需要到很多地方、通过不同途径进行查询,查人物也是一样。所以要提高查询的效率,我们就需要把多元化的数据库联合起来,提供一键式的跨数据库学术资料检索服务,这需要开发通用平台作为中国研究的网络基础设施,这是一个挑战。
(文中图片由包弼德教授提供)
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。